
Apache Kafka часто используется в качестве средства интеграции информационных систем, выполняя роль посредника при обмене сообщениями. Поэтому, чтобы сформулировать требования к подсистеме интеграции на основе Kafka, аналитику следует понимать ключевые принципы работы этой распределенной платформы потоковой передачи событий. Именно это рассмотрим далее, а также разберем, как требования определяют значения конфигураций топиков, продюсеров и потребителей.
Что такое Apache Kafka и как это работает: краткий обзор
Apache Kafka часто называют брокером сообщений, но это скорее гибрид распределенного лога и key-value базы данных. Эта распределенная платформа потоковой передачи событий часто используется в качестве шины обмена сообщениями при интеграции нескольких систем. При этом Kafka реализует принцип «издатель/подписчик», когда приложения-продюсеры отправляют сообщения в топик, откуда их считывают приложения-потребители, подписанные на этот топик. Все это происходит в режиме почти реального времени, т.е. соответствует парадигме потоковой обработки информации.
Топик в Kafka – это не физическое, а логическое хранилище сообщений, которые публикует продюсер, чтобы их считали потребители. Топик позволяет сгруппировать потоки сообщений по категориям, например, по сущностям домена: в один топик будут отправляться события пользовательского поведения, в другой – системные данные с «умных часов» или других устройств носимой электроники и т.д. Каждый топик может быть разбит на разделы (партиции, partition). Раздел является единицей параллелизма и представляет собой журнал (лог) сообщений от одного и только одного приложения-продюсера, упорядоченных в порядке их поступления в Kafka. Порядковый номер сообщения под названием смещение (offset) определяет, когда приложения-потребители считают данные. Лог устроен по принципу FIFO (First In, First Out): первыми считываются сообщения, которые отправлены в Kafka раньше. Подробнее об этом здесь.
Разделение топика на разделы позволяет выровнять нагрузку в кластере Apache Kafka благодаря их равномерному распределению по нескольким узлам, которые называются брокеры. Кроме того, количество разделов определяет количество потоков данных, которые могут обрабатываться параллельно. При отправке данных в Apache Kafka приложение-продюсер назначает сообщение какому-то из разделов топика на основе настраиваемой стратегии, по умолчанию по ключу разделения, т.е. какому-то полю входящего сообщения.
Каждый топик может иметь один или несколько разделов, распараллеленных на разные брокеры, чтобы сразу несколько потребителей могли считывать данные из одного топика одновременно. Если количество потребителей меньше числа разделов, одно приложение-потребитель считывает сообщения из нескольких разделов. Если потребителей больше, чем разделов, некоторые приложения-потребители не могут считывать сообщения, пока их общее количество не снизится до количества разделов. Хотя в теории разделов может быть сколько угодно, на практике их количество ограничено размером сохраняемых сообщений, которые могут поместиться на одном брокере. Обычно на одном брокере рекомендуется держать не более 1000 разделов, включая реплики. Если в топике больше данных, чем фактически может вместить брокер, надо увеличить количество разделов. Когда приложении-потребитель подписывается на какой-то топик, он потребляет сообщения из всех разделов этого топика. Чтобы потребитель не «захлебнулся» от данных, в Kafka есть механизм объединения потребителей в группы для равномерного распределения разделов между несколькими приложениями-потребителями. А порядок чтения сообщений из раздела гарантируется тем, что Kafka дает доступ к разделу только одному потребителю из группы потребителей.
Также разделение является механизмом обеспечивается отказоустойчивости этой распределенной системы за счет копирования (реплицирования) данных на несколько брокеров. При этом «права и обязанности» брокеров, которые содержат фактически одни и те же данные, т.е. данные реплицированного раздела, разделяются:
- есть брокер-лидер (leader), который принимает запросы на чтение и запись данных от приложения-продюсера;
- есть брокеры-подписчики (followers), которые только реплицируют данные лидера и принимают запросы только на чтение сообщений.
Количество брокеров-подписчиков определяется значением фактора репликации минус один. Фактор репликации задает общее количество копий данных раздела во всем кластере, включая размещение на брокере-лидере. Чтобы клиенты Kafka, т.е. приложения-продюсеры и потребители знали, к какому брокеру нужно подключиться, в кластере используется внешний (по отношению к Kafka) сервис синхронизации метаданных Apache ZooKeeper. Он хранит метаданные о разделах топиков и брокерах. С весны 2021 года вышло важное обновление Kafka 2.8, где на замену ZooKeeper предлагается внутренний механизм Quorum Controller, который использует новый протокол KRaft (Kafka Raft) для обеспечения точной репликации метаданных в кворуме. Однако, он все еще не рекомендуется для реальных высоконагруженных проектов. Подробнее об этом здесь и здесь.
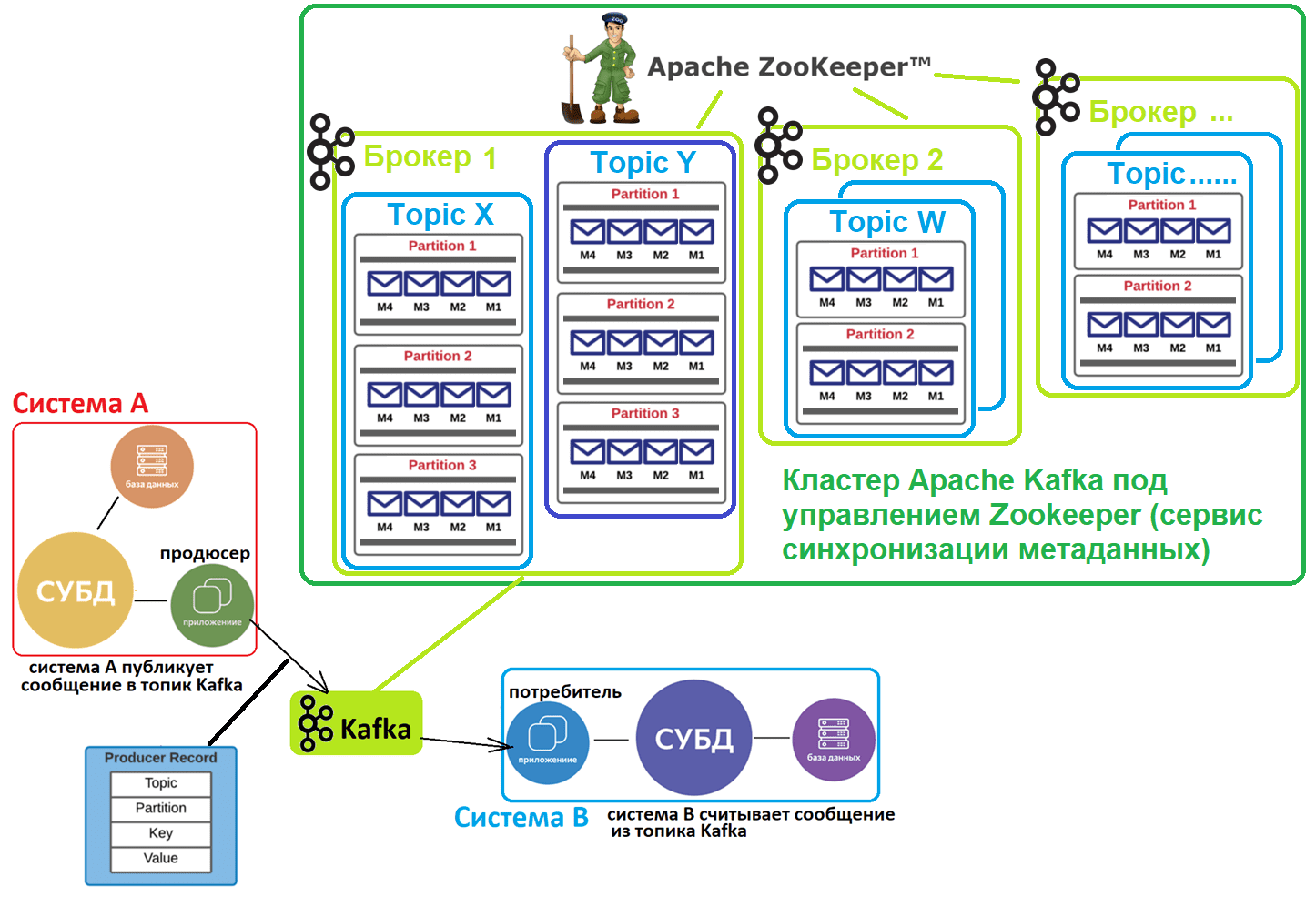
В отличие от популярного JMS-брокера сообщений Rabbit MQ, Kafka работает по принципу вытягивания (pull), когда приложения-потребители сами считывают из топиков нужные им данные. По сути, это соответствует концепции «тупой сервер, умный клиент», когда логика работы с сообщениями реализуется на клиентской стороне. Kafka не следит, какие сообщения прочитаны потребителями, а просто хранит их на жестком диске в течение заданного периода времени или до момента превышения заданного лимита. Потребители сами опрашивают топик Kafka на предмет новых сообщений и указывают, какие сообщения нужно считать, увеличивая или уменьшая смещение. Из одного топика данные могут считывать несколько приложений-потребителей, тогда как отправлять сообщения в топик может только один продюсер, чтобы не нарушать упорядоченность событий. Подробнее про отличия Kafka и Rabbit MQ, а также разницу с другими JMS-брокерами, смотрите здесь и здесь.
Потоковая парадигма означает бесконечное поступление сообщений и их обработку в режиме реального времени, тогда как при пакетной обработке итоговое значение создается только после полной обработки всех связанных данных. Поэтому для потоковой обработки особенно важны полнота, доступность и упорядоченность сообщений, чтобы исключить дублирование и потерю данных. Для этого в Apache Kafka есть гарантия доставки сообщений, реализующая семантику строго один раз (exactly once). Это значит, что если приложение-продюсер из-за сбоя сети или какой-то внутренней ошибки повторно отправит одни и те же данные в Kafka, сообщение будет записано в топик только один раз.
За реализацию этой семантики доставки сообщений отвечает свойство идемпотентности в настройках продюсера и число подтверждений об успешной записи (acknowledge, acks). Например, если параметр acks равен 0, приложение-продюсер не ждет от Kafka подтверждения об успешной записи сообщения в топик: сообщение считается отправленным в любом случае, т.е. даже при фактическом сбое записи. Если acks равно 1, отправленное сообщение записывается в локальный лог брокера-лидера, не ожидая полного подтверждения от всех подписчиков. При этом сообщение может быть потеряно в случае сбоя лидера до репликации по всему кластеру. Если параметр acks равен -1 (all), приложение-продюсер ждет полной репликации сообщения по всем серверам кластера. Это повышает надежность системы интеграции, предотвращая потерю данных, но увеличивает задержку их обработки и снижает пропускную способность. Подробнее смотрите здесь, здесь и здесь.
Приложение-продюсер отправляет в Kafka сообщение, которое имеет следующую структуру:
- ключ — двоичное поле, которое может быть нулевым;
- значение, которое является содержимым сообщения, и оно также может быть нулевым;
- тип сжатия сообщения – без сжатия (none) или один из кодеков (gzip, snappy, lz4, zstd);
- дополнительные заголовки, пары ключ-значение, которые содержат метаданные.
- номер раздела и идентификатор смещения, которые становятся частью сообщения, как только приложение-продюсер отправило сообщение в Kafka;
- отметка времени происхождения события, данные о котором зашиты в полезную нагрузку, т.е. значение сообщения.
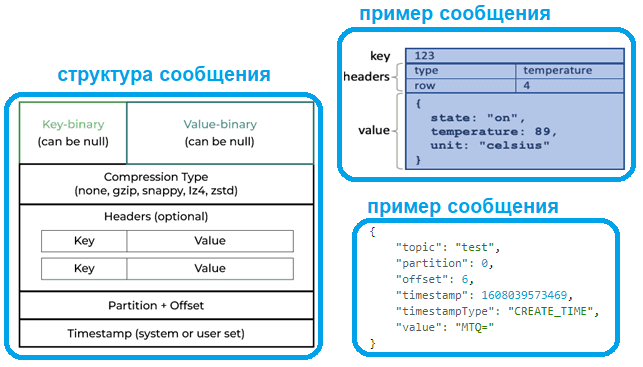
Обычно полезная нагрузка представляет собой некоторое сообщение в JSON-формате, структура которого может быть задана в виде JSON-схемы, что хранится в реестре схем (Schema registry). Реестр схем – это модуль платформы Kafka от компании Confluent, что занимается коммерциализацей этой технологии. Реестр схем особенно полезен в случае множества приложений-продюсеров, которые могут посылать данные разных структур. Такое часто бывает в проектах интернета вещей (Internet of Things).
Впрочем, Kafka поддерживает не только JSON, но и другие форматы сообщений: бинарные Apache AVRO и Protobuf, текст и т.д. В любом случае, какой бы формат данных не был у исходного сообщения, в топике оно хранится в виде набора байтов. Этот процесс перевода структурированных данных в набор байтов называется сериализацией и нужен для передачи данных по сети и их хранения на жестком диске. Для этого исходные данные сериализуются, т.е. переводятся в массив байтов с помощью сериализаторов ключей и значений. Kafka отлично работает с огромным количеством сообщений, но они должны быть небольшого размера. Максимальный размер сообщения, отправленных в топик Kafka, определяется конфигурацией message.max.bytes и по умолчанию не превышает 1 МБ. При отправке сообщения большего размера, приложение-продюсер получит от брокера Кафка уведомление об ошибке, а само сообщение не будет принято к записи. Важно также, сколько сообщений укладывается в пакет — хотя Kafka и реализует потоковую парадигму обработки данных, сообщения от приложения продюсера отправляются в топик не сразу. Сперва они добавляются в пакет – внутренний буфер, размер которого по умолчанию равен 32 МБ. Если продюсер отправляет сообщения быстрее, чем их можно передать брокеру, или случились проблемы с сетью, этот внутренний буфер переполняется. Тогда метод продюсера, запускающий непосредственную отправку в топик, будет заблокирован на время, указанное в конфигурации max.block.ms (по умолчанию 1 минута). Подробно об этом читайте здесь.
Поскольку сообщения в Kafka отправляются в виде пакета записей, он имеет так называемые накладные расходы: 61 байт метаданных, где указываются версия сообщения, количество записей, алгоритм сжатия, транзакция и пр. Эти накладные расходы на пакетную запись постоянны и не поддаются уменьшению. Но можно оптимизировать размер пакета, объединяя несколько сообщений в 1 пакет, сжимая данные с помощью кодеков и/или используя более экономные форматы сериализации данных, например, AVRO вместо JSON. Подробнее об этом здесь.
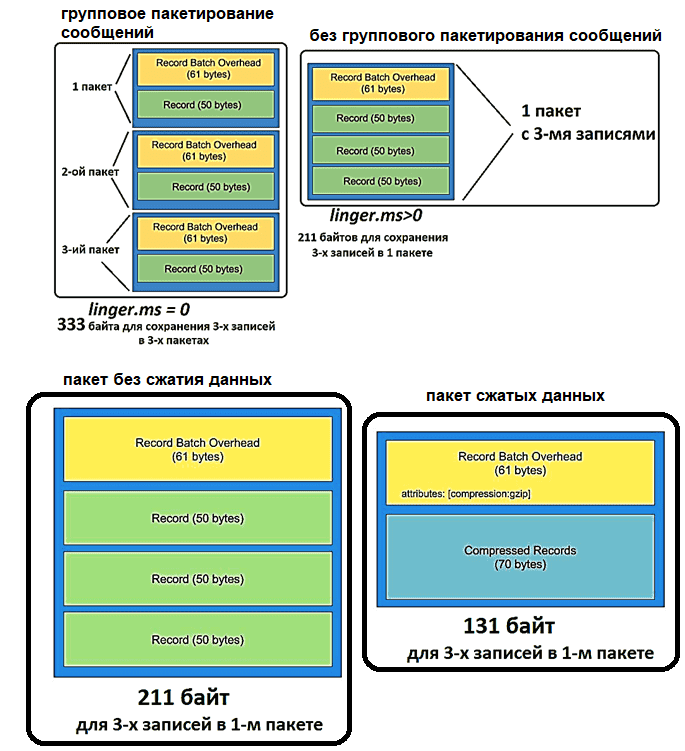
Также за задержку отправки пакета сообщений отвечают конфигурации linger.ms и batch.size. linger.ms. Увеличение linger.ms, по умолчанию равного 0, снижает количество запросов и повышает пропускную способность шины, но увеличивает задержку перед отправкой данных. Batch.size определяет максимальный размер одного пакета сообщений: чем больше значение этого параметра, тем больше сообщений группируются в один пакет, что тоже увеличивает задержку. Конфигурации linger.ms и batch.size дополняют друг друга: пакет данных отправляется при достижении любого из этих 2 лимитов. Подробности здесь и здесь.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
7 главных требований аналитика к шине на Apache Kafka
Разобравшись с ключевыми принципами работы и основами архитектуры Apache Kafka, определим, какие главные требования к ней как к средству межсистемной интеграции следует определить аналитику, чтобы ИТ-архитектор и администратор кластера смогли реализовать это решение:
- определить набор топиков с учетом их привязки к бизнес-задачам или доменным сущностям. Например, топик для данных о пользовательских действиях, системных событиях, изменениях окружающей среды и т.д. Сделать это можно в виде таблицы:
| Название топика | Смысл топика (что за данные там хранятся) |
| user_events | Хранилище данных о событиях пользовательского поведения (клики, просмотры, скролы страницы и пр.) |
| system_events | Хранилище данных о системных событиях (повышение объема потребляемой памяти, изменение температуры процессора и т.д.) |
- определить, какие приложения будут источниками, а какие – приемниками данных, т.е. в терминах Kafka это будут продюсеры и потребители. Графически это можно сделать в виде контекстной DFD-диаграммы или дополнить вышеприведенную таблицу:
| Топик | Смысл топика | Приложение-продюсер | Приложение—потребитель |
- определить допустимую задержку отправки данных от приложения-продюсера в Kafka – можно задать в миллисекундах, понадобится для установки параметра конфигурации ms. Это также можно сделать в таблице
| Приложение-продюсер | Приложение—потребитель | |||
| Топик | Смысл топика | Название | Задержка отправки данных (мс) | |
- задать требования к надежности передачи данных – следует ли продюсеру дожидаться подтверждения об успешной репликации сообщения с лидера раздела по всем подписчикам (acks=-1), каков коэффициент репликации, т.е. сколько копий сообщения будет сделано (определяется требованиями к надежности системы). Также аналитику следует определить, какая семантика доставки сообщений нужна для приложений-потребителей, т.е. допустимы ли дубли сообщений или потери данных при сбое отправки от потребителя в Kafka. Если потери и сбои недопустимы, это надо явно указать, чтобы разработчики приложения-продюсера сделали его идемпотентным (idempotence=true), реализуя семантику строго однократной доставки сообщений (exactly once). Дополним нашу таблицу:
| Топик | Приложение-продюсер | Приложение—потребитель | ||||
| Название | Смысл | Название | Задержка отправки данных (мс) | Идемпотентность (да, нет) | Ожидание подтверждения отправки (нет, 1, все) | Название |
- определить необходимую длительность хранения данных – поскольку Kafka записывает сообщения на жесткий диск, потенциально они могут храниться там вечно. Однако, зачастую в этом нет смысла. Слишком длительное хранение сообщений снижает пропускную способность Kafka как средства межсистемной интеграции и тормозит работу приложений-продюсеров и потребителей. Поэтому аналитику следует задать период очистки топика, что администратор Kafka установил корректные значения конфигурации топика retention.bytes и retention.ms. Параметр retention.ms контролирует максимальное время, в течение которого лог будет храниться до удаления, чтобы потребители точно успели прочитать данные. Если retention.ms=-1, хранение данных по времени не ограничено. С конфигурацией retention.ms связаны log.retention.hours, log.retention.minutes, log.retention.ms, которые указывают время хранения лог-файлов перед их удалением в часах, минутах и миллисекундах соответственно.
Для этого можно сделать отдельную таблицу для топиков:
| Топик | Смысл топика | Количество разделов | Фактор репликации | Максимальный объем хранимых данных до удаления (байты) | Время хранения данных до удаления (часы, минуты, секунды) |
- Наконец, нужно определиться с данными, которые будут храниться в топиках Kafka – сделать пример сообщения, схему данных для него и максимальный размер, помня о том, что Kafka плохо работает с очень большими записями. Например, приложение-продюсер отправляет в Kafka данные о событиях пользовательского поведения в виде JSON-сообщения со следующей полезной нагрузкой:
{
"session_id": 134453,
"event": {
"event_type": "session_start",
"event_time": "2022-11-03T18:25:43.511Z"
},
"page": "/course_143"
}
Для этого примера JSON-данных схема выглядит так:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
"session_id": {
"type": "integer"
},
"event": {
"type": "object",
"properties": {
"event_type": {
"type": "string"
},
"event_time": {
"type": "string"
}
},
"required": [
"event_type",
"event_time"
]
},
"page": {
"type": "string"
}
},
"required": [
"session_id",
"event",
"page"
]
}
Для этого расширим нашу таблицу топиков:
| Топик | Смысл топика | Количество разделов | Фактор репликации | Максимальный объем хранимых данных до удаления (байты) | Время хранения данных до удаления | Пример сообщения (полезная нагрузка) | Схема данных | Формат сериализации |
- Допустимо сделать предположения относительно ключа разделения, т.к. по умолчанию сообщения от продюсера направляются в разделы топика случайным образом. Чтобы отправить сообщение в конкретный раздел, приложение-продюсер добавляет ключи и все сообщения с указанным ключом отправляются в один и тот же раздел. Например, действия конкретного пользователя можно отслеживать в хронологическом порядке, если все события его поведения помечены одним ключом и попадают в один раздел. Например, если объектом анализа является поведение отдельно взятых пользователей, в качестве ключа разделения может быть идентификатор пользовательской сессии (session_id). А если интересует анализ типа событий (регистрация, клик, просмотр и пр.), ключом разделения может быть тип события (event_type).
Разумеется, это далеко не исчерпывающий список факторов, которые обусловливают выбор проектного решения. В частности, официальная документация Kafka включает около 60 параметров конфигурации продюсеров, причем не все из них напрямую определяют скорость работы системы. Примерно 10 параметров относится к информационной безопасности, в частности, настройки SSL-шифрования, защищенного протокола Kerberos и пр. Кроме этого есть еще множество настроек для приложений-продюсеров, топиков, разделов и брокеров, которые комплексно влияют на пропускную способность и надежность этой распределенной платформы потоковой передачи событий. Подробнее об этом здесь и здесь. Вообще много моих статей про Apache Kafka и другие технологии стека Big Data есть в блоге Школы Больших Данных.
А здесь я пошагово рассказываю, как создав собственный кластер Kafka на бесплатном плане облачной платформы Upstash и написать свои приложения для публикации и потребления сообщений. Впрочем, если погружаться во все эти нюансы, аналитик вступает на территорию архитектора, разработчика и администратора Kafka, что нужно далеко не каждому. Возвращаясь к работе аналитика, вспомним, что главная миссия этого специалиста – снизить уровень неопределенности на проекте. Это означает, чтобы ИТ-архитектор мог выбрать и разработать наиболее подходящее интеграционное решение, аналитику следует подробно сформулировать требования к подсистеме интеграции на основе Apache Kafka, оформив их в техническое задание.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
10 августа, 2026
Продолжительность
22 ак.часов
Стоимость обучения
52 800 руб.
Как это сделать на практике, а также познакомиться с другими важными аспектами архитектуры и интеграции информационных систем, вы узнаете на курсах Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS

