
Сегодня я на практическом примере покажу, как именно реализуются принципы работы Apache Kafka при интеграции информационных систем. Для этого напишем и запустим в Google Colab 2 небольших Python-приложения. Продюсер будет публиковать сообщения в топик экземпляра Kafka, развернутого на облачной платформе upstash.com, а приложение-потребитель будет считывать и обрабатывать эти данные.
Постановка задачи и создание кластера Apache Kafka в облачной платформе Upstash
О том, что такое Apache Kafka и как эта распределенная платформа потоковой передачи событий используется для асинхронного общения между несколькими сервисами в проектах интеграции информационных систем, я писала здесь.
В качестве демонстрационного стенда возьмем облачную платформу Upstash (upstash.com), где можно на бесплатном плане развернуть собственный кластер Apache Kafka и подключиться к нему с помощью собственных клиентов через TCP и REST API через HTTP. Разумеется, бесплатный тариф имеет ряд ограничений: не более 10 000 команд в день и общий объем данных 256 МБ, а также отсутствие шифрования в REST API. Впрочем, этих возможностей более чем достаточно для нашего демонстрационного примера, чтобы познакомиться с этой технологией.
Для демонстрации возьмем пример из моего недавнего материала про JMS-брокер RabbitMQ. Приложением-продюсером, которое создает данные и отправляет их в Kafka, будет умный датчик с 2-мя видами измерений: температура и давление. Эти данные и обрабатывает считывает одно приложение-потребитель.
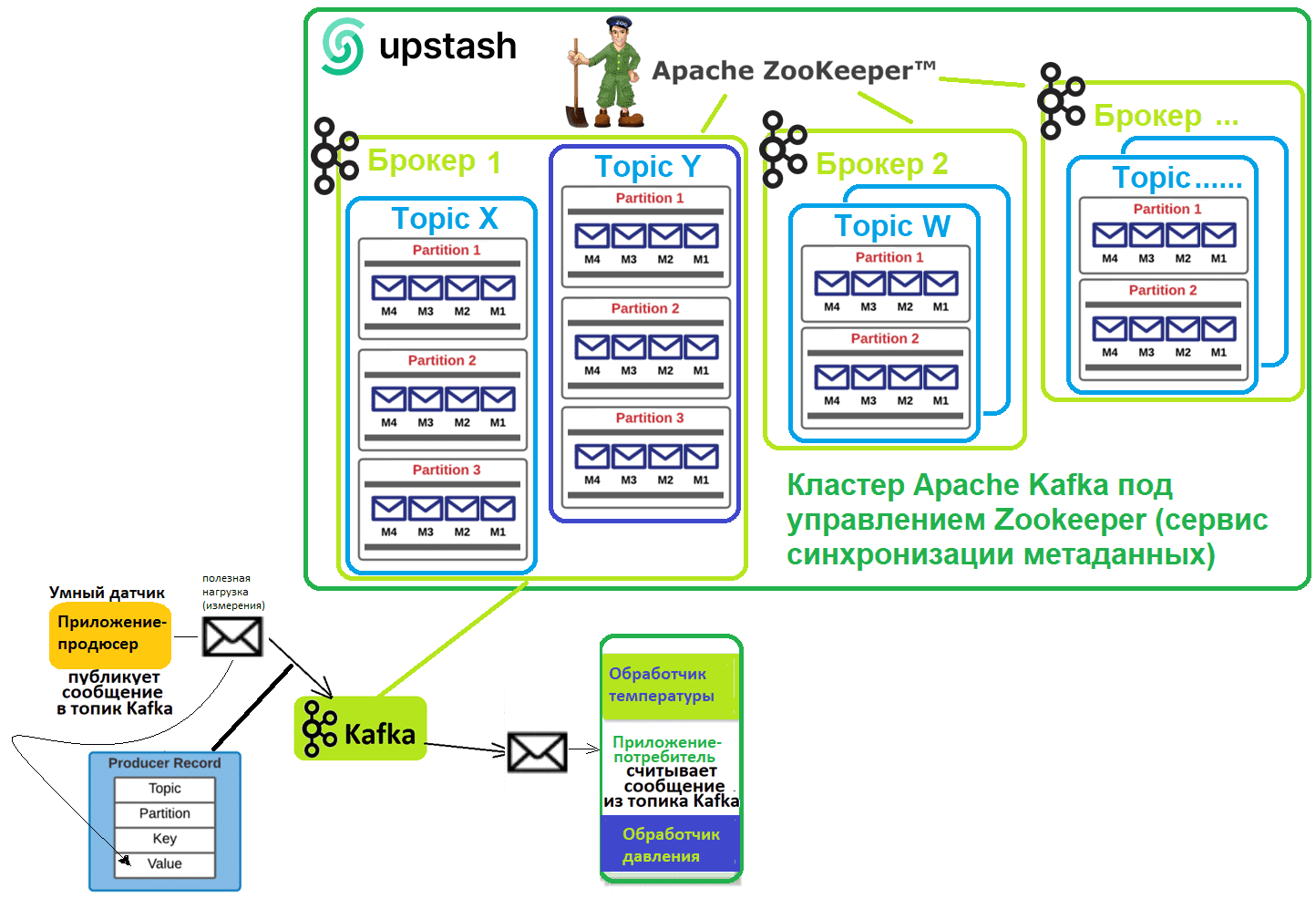
Данные от умного датчика, т.е. полезная нагрузка сообщения от приложения-продюсера, отправляются в JSON-формате по следующей схеме:
{
"$schema": "http://json-schema.org/draft-04/schema#",
"type": "object",
"properties": {
" device_id": {
"type": "integer"
},
"measure": {
"type": "string"
},
"value": {
"type": "integer"
}
},
"required": [
" device_id",
"measure",
"value"
]
}
Определившись с решаемой задачей, приступим к технологиям ее реализации. Сперва создадим собственный кластер в облачном сервисе Upstash, выбрав бесплатный план. Также создадим топик Kafka, куда будут публиковаться сообщения от продюсера.
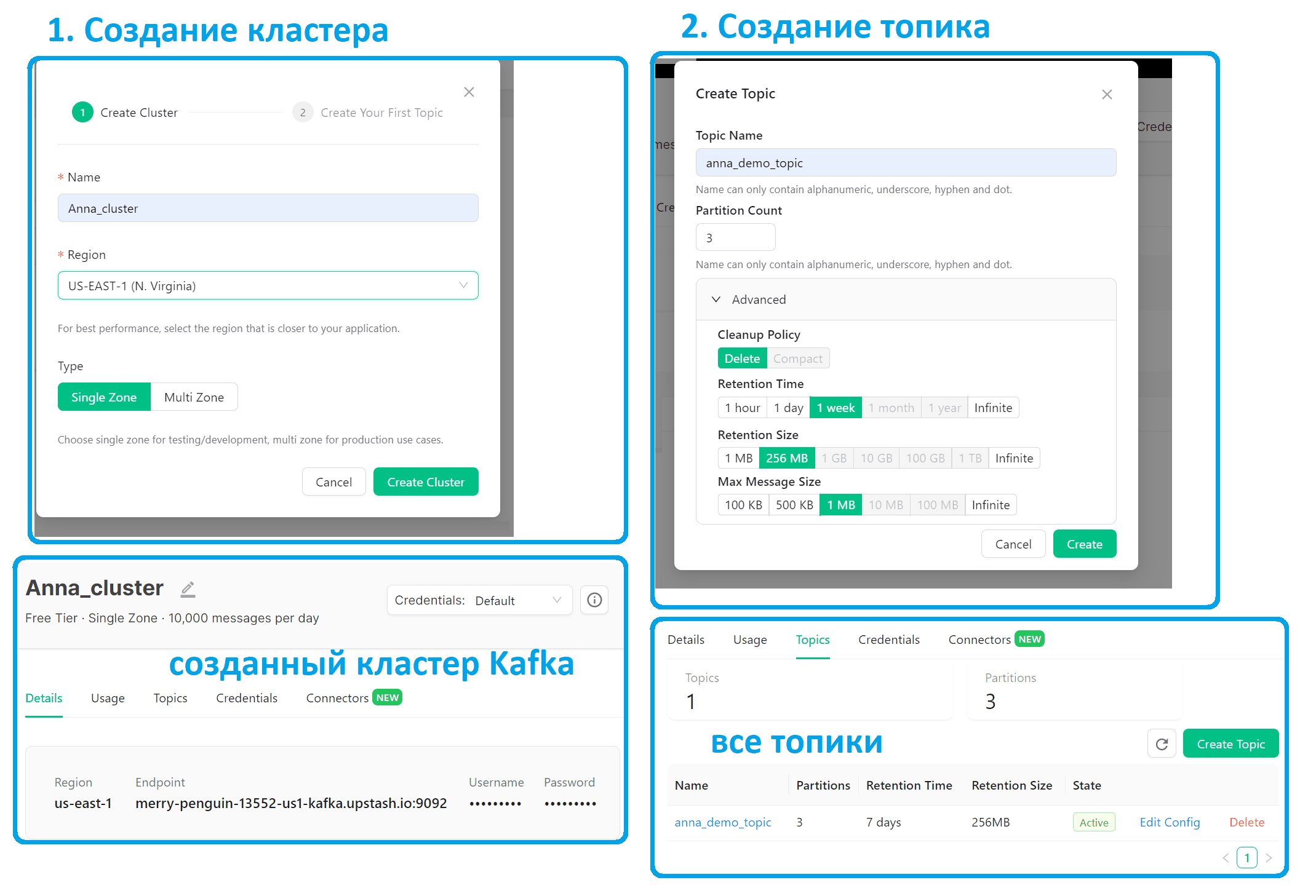
Подготовив инфраструктуру, можно перейти к созданию своих приложений: продюсера и потребителя. Как обычно, я буду писать код на Python и запускать его в Google Colab –интерактивной облачной среде. Как она работает, я ранее рассказывала здесь и здесь.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Пишем приложение-продюсер
Благодаря отличной документации и визуализации возможностей платформы Upstash в ее пользовательском интерфейсе писать код вручную почти не нужно. Заготовки для продюсера и консумера с уже предзаполненными учетными данными для подключения к своему облачному инстансу Kafka можно взять на вкладке Details созданного кластера. А учетные данные нужно скопировать с вкладки Credentials.
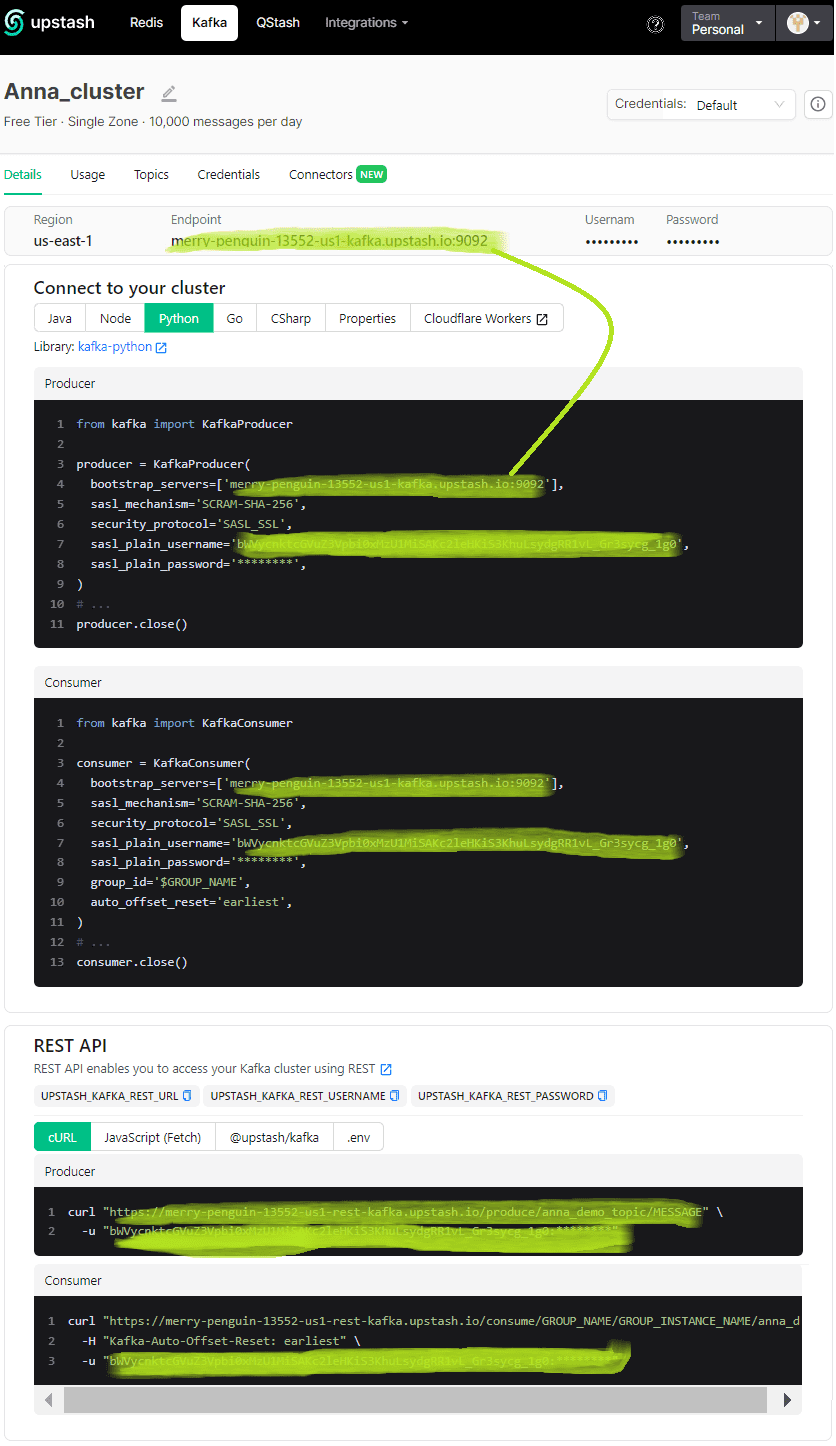
Теперь напишем Python-код своего приложения-продюсера, который будет каждые 3 секунды отправлять данные по температуре и давлению в Kafka. Причем измерения по давления будут отправляться в раздел 1, а измерения температуры – в раздел 2 одного и того же топика. Эти данные (полезная нагрузка) будут в формате JSON с кодировкой utf-8.
!pip install kafka-python
import json
import random
import time
from kafka import KafkaProducer
# Connect to Kafka server
producer = KafkaProducer(
bootstrap_servers=['URL-адрес_вашего_инстанса_Kafka:порт_обычно_9092'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='имя_вашего пользователя',
sasl_plain_password='пароль_вашего_пользователя',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# Prepare a list of devices
devices =[random.randint(0, 100) for i in range(100)]
# Prepare a list of possible routing keys
measures = ['pressure', 'temperature']
while True:
# Prepare random message in JSON format
measure=random.choice(measures)
data = {'device': random.choice(devices), 'measure': measure, 'value': random.randint(0,100)}
message = json.dumps(data)
if measure=='pressure':
partition_key = 1
else:
partition_key = 2
print(f' [x] partition {partition_key}')
print(f' [x] Message {message}')
# produce json messages
future = producer.send('anna_demo_topic', value=data, partition=partition_key)
record_metadata = future.get(timeout=60)
print(f' [x] Sent {record_metadata}')
# Sleep for 3 seconds
time.sleep(3)
# close producer
producer.close()
В Google Colab этот код лучше распределить по 3-м ячейкам:
- в 1-ой ячейке будет установка и импорт Python-библиотек для работы с Kafka (kafka-python), а также форматом JSON, операторами random и времени;
- во 2-ой ячейке код подключения к Kafka и публикации сообщений;
- в 3-ей ячейке закрытие активного подключения и продюсера.
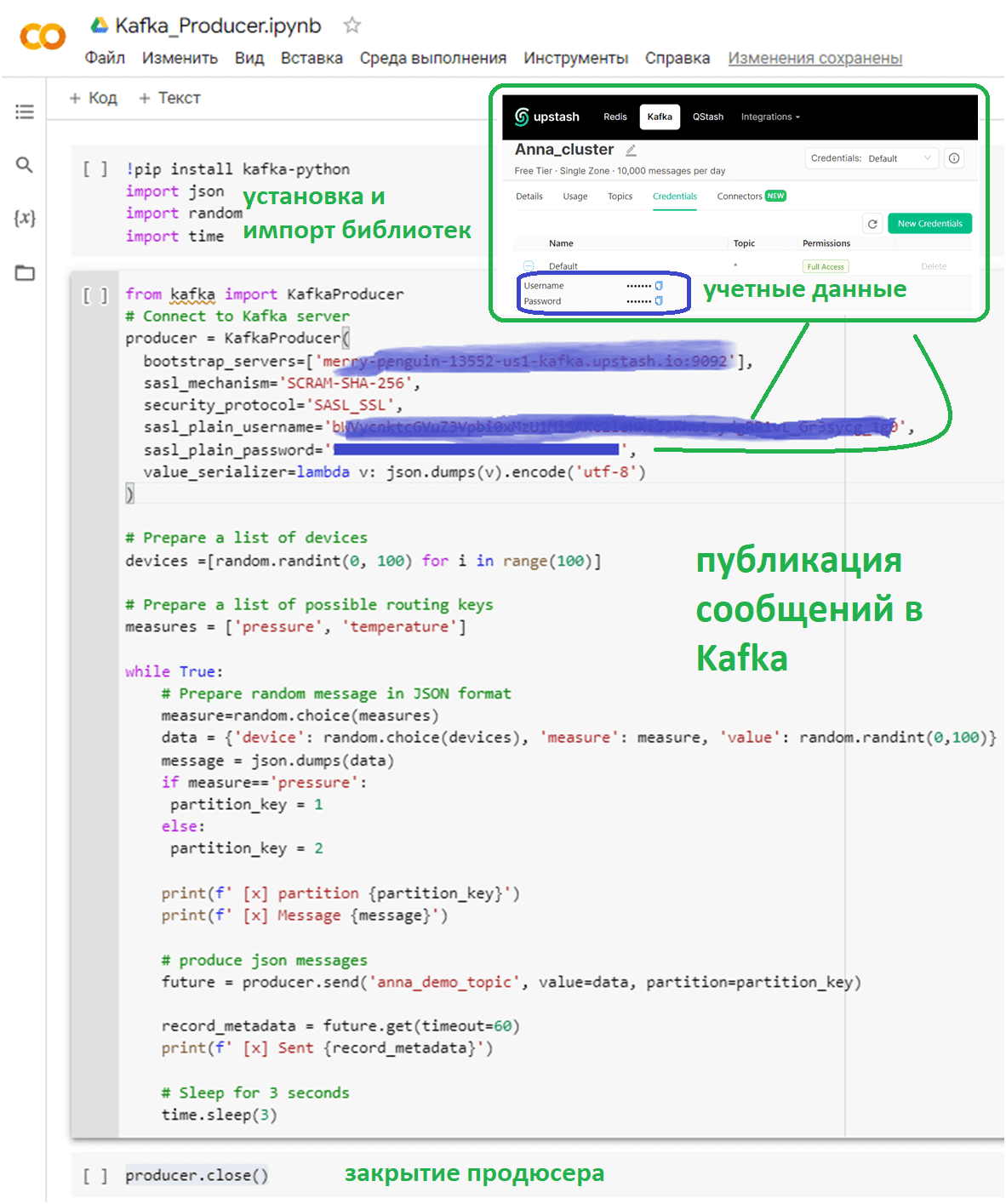
Для публикации сообщений последовательно запустим первые 2 ячейки и увидим, как дополнительно к полезной нагрузке, т.е. исходному JSON-сообщению с данными о номере устройства, измерении (температура или давление) и значении этого измерения, продюсер добавляет в сообщение название топика, раздел, позицию смещения, отметку времени и другие служебные метаданные.
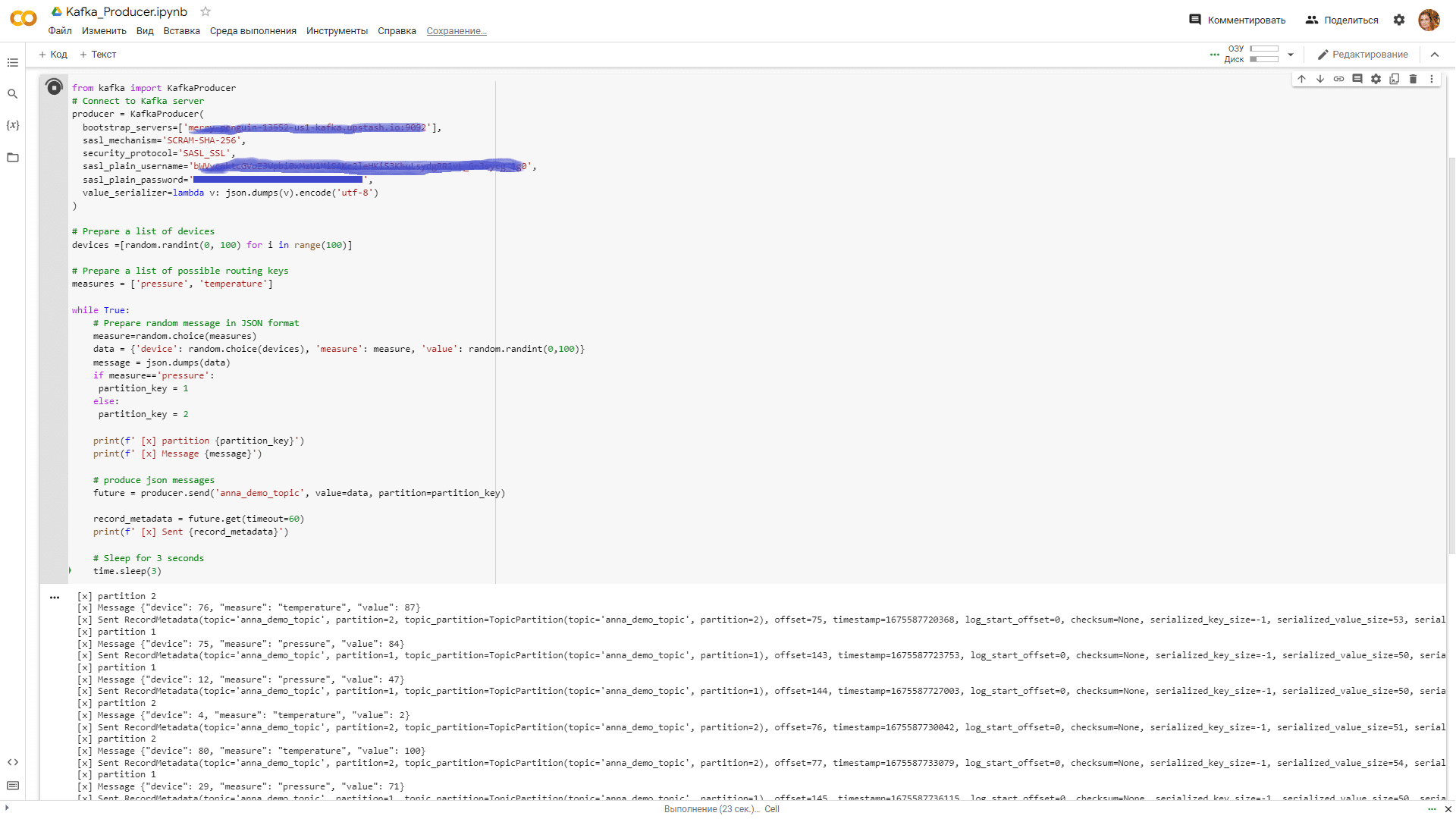
Далее напишем код приложения-потребителя и посмотрим, как все работает.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Пишем потребитель
Пусть наше приложение-потребитель не просто потребляет данные из разделов топика Kafka под названием anna_demo_topic, но и обрабатывает принятые значения измерений, маркируя состояние устройства отметкой OK или ошибкой ERROR. Для этого придется в цикле приема сообщений выполнить парсинг полученной полезной нагрузки и написать проверку значений этого JSON.
!pip install kafka-python
import json
import random
import time
from kafka import KafkaConsumer
import json
from json import loads
consumer = KafkaConsumer(
bootstrap_servers=['URL-адрес_вашего_инстанса_Kafka:порт(обычно_9092)'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='имя_вашего пользователя',
sasl_plain_password='пароль_вашего_пользователя',
group_id='$group',
auto_offset_reset='earliest'
)
consumer.subscribe(['anna_demo_topic'])
for message in consumer:
print (message)
payload=message.value.decode("utf-8")
data=json.loads(payload)
device_state=''
device_measure=''
if (data['measure']== 'pressure'):
device_measure='pressure'
if ((data['value']<= 50) and (data['value'] >= 10)):
device_state='OK'
else:
device_state='ERROR'
else:
device_measure='temperature'
if ((data['value']<= 80) and (data['value'] >= 20)):
device_state='OK'
else:
device_state='ERROR'
print("Устройство № ", data["device"], device_measure, device_state, "значение ", data['value'])
#unsubscribe and close consumer
consumer.unsubscribe()
consumer.close()
Аналогично продюсеру, разделим этот код на 3 ячейки в Google Colab, сохранив в отдельном блокноте. Чтобы потребление сообщений работало, следует параллельно запустить их публикацию. Поэтому будет 2 разных ipynb-файла. Посмотрим, как работает потребление сообщений, выполнив первые 2 ячейки вышеприведенного Python-кода.
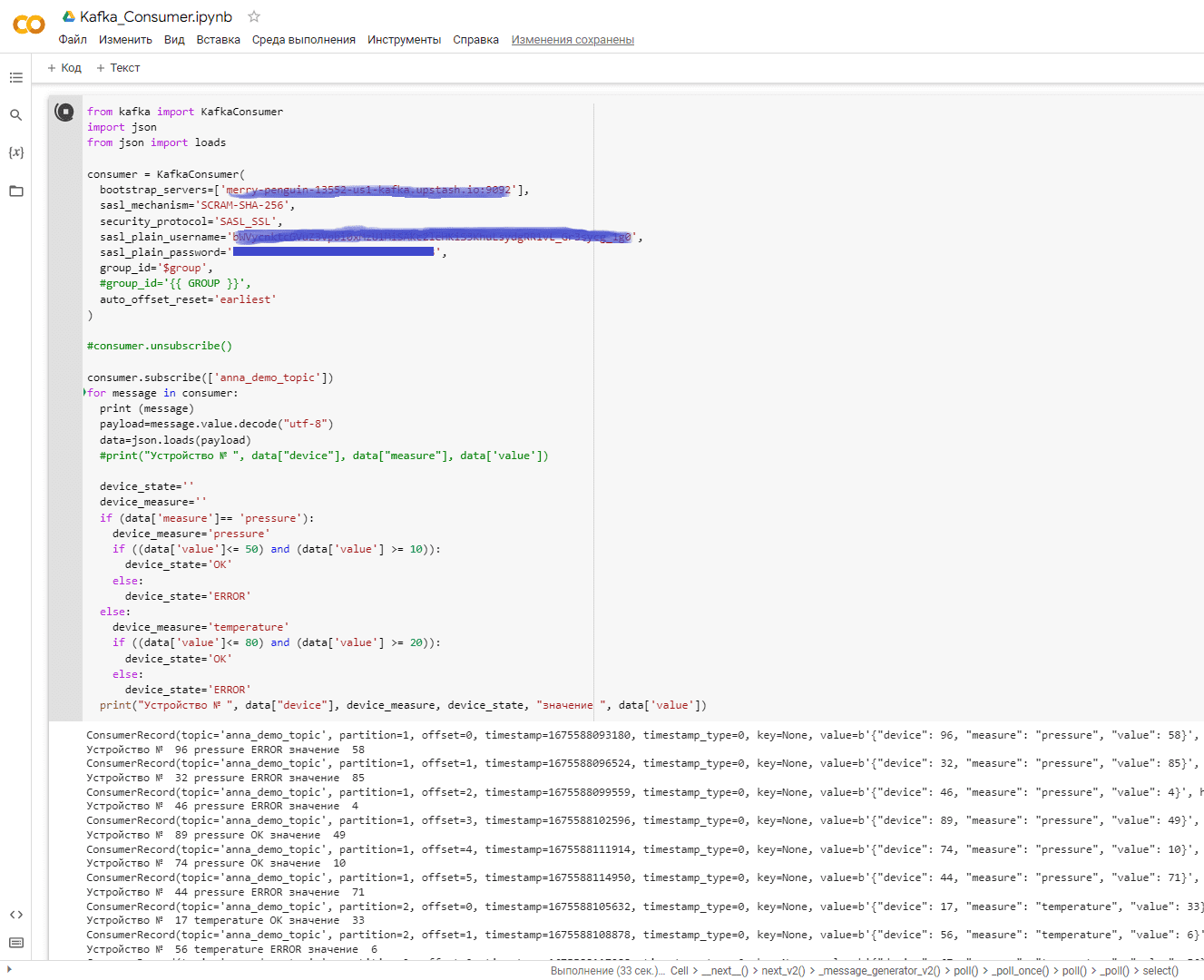
Посмотреть, как меняются данные об опубликованные и потребленных сообщениях, можно в GUI-платформы Upstash.

Как этот код модифицирован для записи данных об ошибках измерений в резидентную NoSQL-СУБД Redis, читайте в моей новой статье.
В заключение посмотрим, как получить сведения о своем Kafka-кластере через REST API этой облачной платформы. Следует простой найти нужный метод в документации и отправить запрос в Postman или другом инструменте тестирования REST API. Например, GET-запрос к конечной точке /consumers с базовой аутентификацией по логину и паролю позволяет узнать про потребителей в группе потребителей, название инстанса в кластере Kafka, топик и количество разделов в нем. О том, что такое конечная точка, а также про HTTP-запросы я писала здесь и здесь.
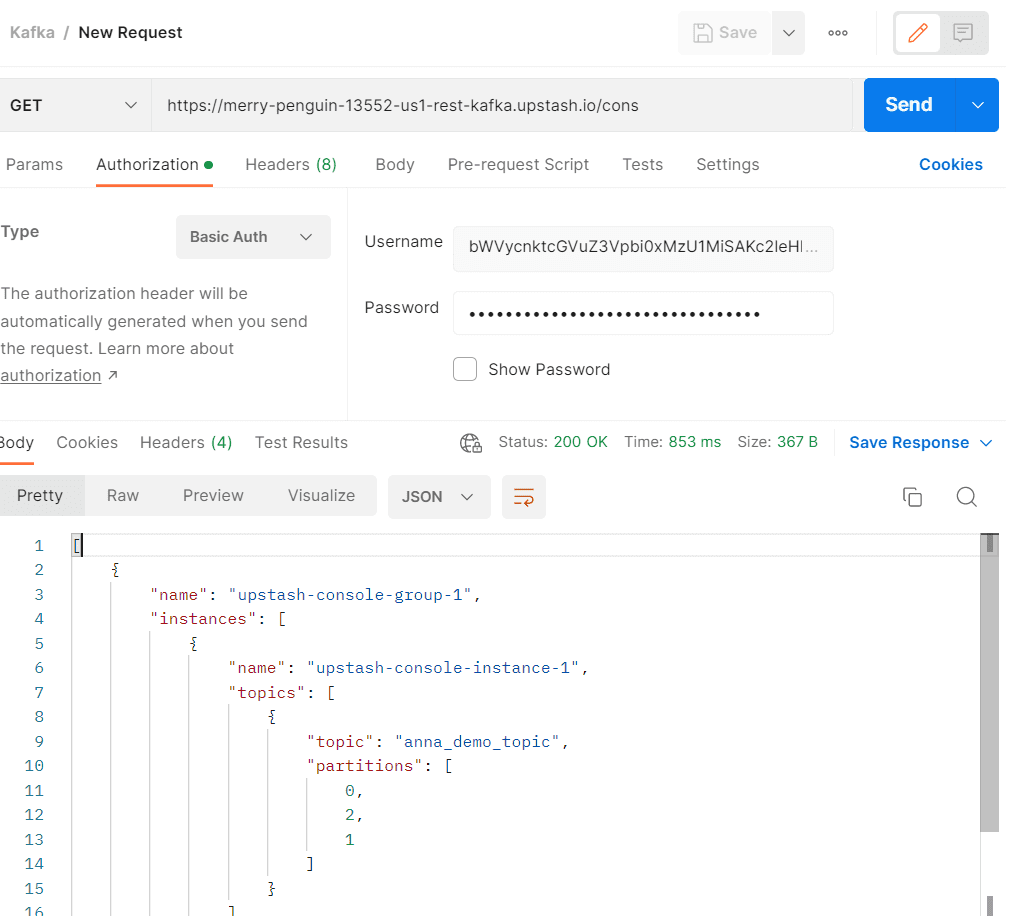
В заключение отмечу, что далеко не на каждом проекте аналитику нужно знать все эти подробности, с которыми взаимодействует архитектор, разработчик и администратор Kafka. Однако, именно такая демонстрация, проделанная собственноручно с помощью открытых инструментов позволяет понять основные принципы этой замечательной технологии, чтобы использовать ее в качестве средства интеграции информационных систем.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Как это выполнить все это на практике, а также познакомиться с другими важными аспектами архитектуры и интеграции информационных систем, вы узнаете на курсах Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:

