
Чтобы помочь начинающим аналитикам разобраться с основами SQL и реляционных баз данных, сегодня рассмотрим практический пример построения модели данных, заполнения таблиц значениями и генерации запросов к полученной базе. DDL-запросы для создания таблиц и примеры DML-запросов для наполнения их данными, а также выборки с условиями WHERE, GROUP BY, HAVING, операторы работы с датами и временем.
Проектирование реляционной модели (схемы базы данных)
Как я уже рассказывала здесь, системные и бизнес-аналитики часто сталкиваются с моделированием данных в рамках задачи разработки требований к ИС. Однако, зачастую простого концептуального моделирования, которое переводит ключевые сущности домена (предметной области) в плоскость программной системы, бывает недостаточно для разработки или более детального проектирования базы данных на физическом уровне. Основным фактором, определяющим ценность концептуальной модели, является возможность ее использования для дальнейшей работы. И чтобы повысить эту ценность, аналитику полезно понимать, какие именно потребности бизнеса позволит обеспечить разработанная им модель. Применительно к моделированию данных это примеры SQL-запросов.
Предположим, учебный центр, который предлагает курсы по 3-м направлениям: системный и бизнес-анализ, технологии Big Data, а также менеджмент, имеет данные о заявках слушателей на разные курсы.
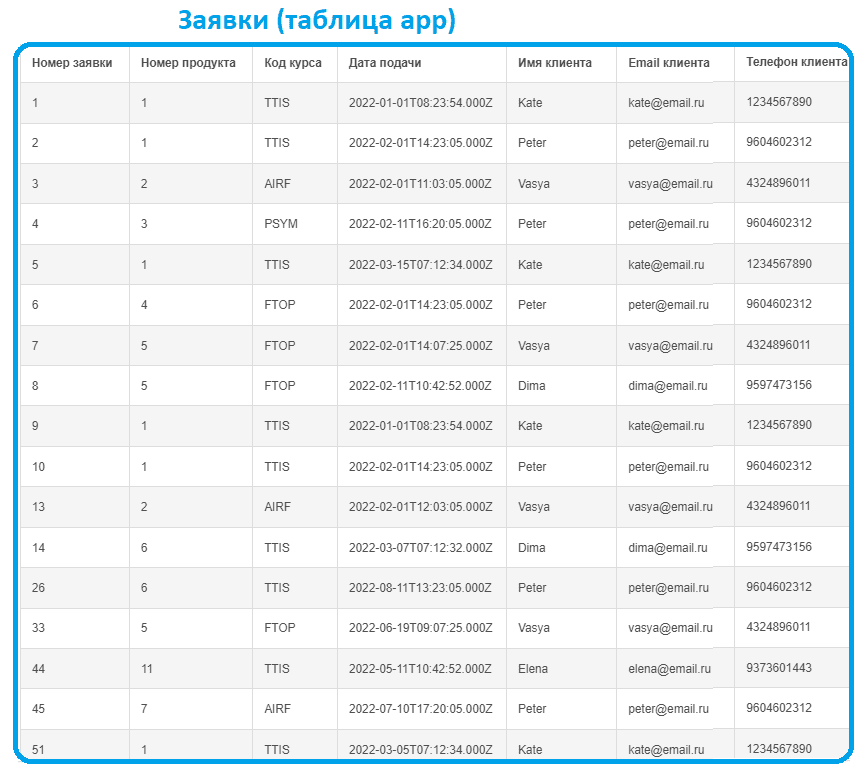
Имеется каталог курсов и расписание их проведение, а также данные по потенциальным клиентам, подавшим заявки и тренерам, которые проводят курсы.
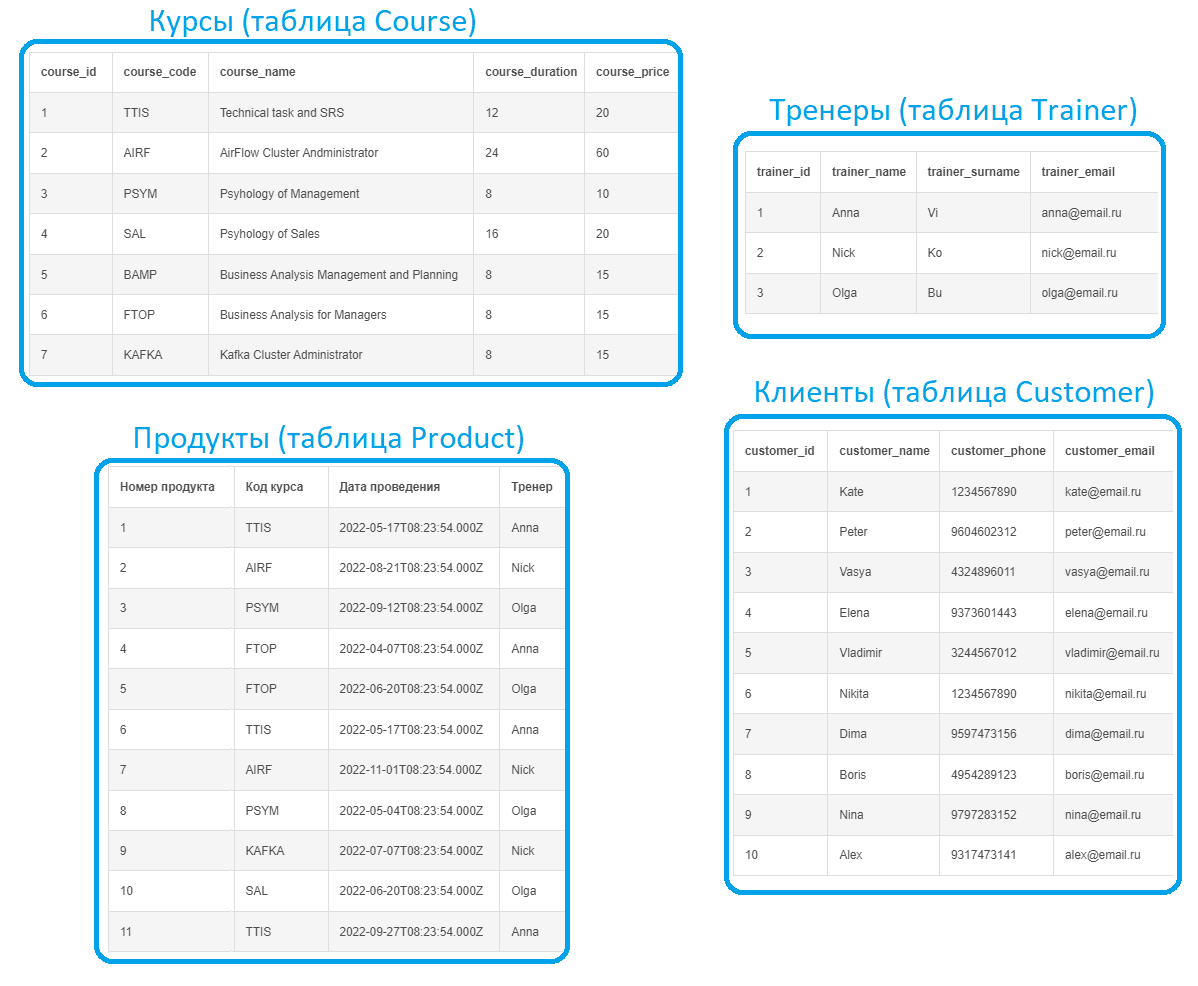
Реляционная модель данных, спроектированная для рассматриваемого случая, будет выглядеть следующим образом:
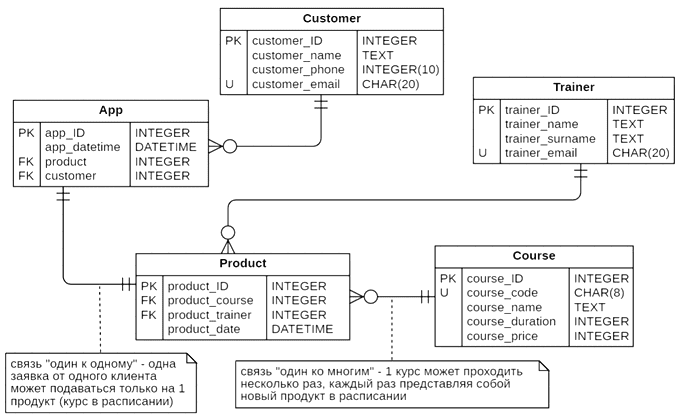
Выделено 5 сущностей, которые связаны между собой разными типами отношений. Каждая сущность в итоге представляет собой таблицу реляционной базы данных с набором столбцов, т.е. атрибутов или полей, каждое из которых содержит данные определенного типа. Поскольку база данных является реляционной, таблицы связаны между собой по ключам. Например, один тренер может вести несколько курсов. Таблица Course представляет собой каталог курсов, каждый из которых может проводиться несколько раз в разное время разными тренерами, что хранится в таблице Product. Один клиент (Customer) может подать много заявок, но каждая заявка может быть только по одному продукту.
Чтобы сократить избыточность данных в разных таблицах, проведена нормализация, т.е. приведение структуры данных к нормальной форме. В частности, данные клиентов хранятся не в таблице заявки, а выделены в отдельную таблицу Customer. Аналогичным образом данные о курсах и тренерах, которые их проводят содержатся не в таблице с расписанием (Product), а в отдельных таблицах. Это исключает транзитивную зависимость полей друг от друга. Чаще всего ER-модель приводят к 3-ей нормальной форме, когда каждая таблица атомарна и любой не ключевой атрибут в ней зависит только от первичного ключа.
В каждой таблице определен первичный ключ (Primary Key, PK),– столбец, каждое значение которого уникально и однозначно идентифицирует запись (строку) этой таблицы. Для ускорения работы базы данных в качестве первичного ключа обычно принимается целочисленный идентификатор, который реализуется автоматической генерацией поля ID с автоинкрементом, т.е. увеличением на 1 при создании новой записи. Большинство современных СУБД сами следят за этим, т.е. на уровне концептуального проектирования при описании модели предметной области, этот атрибут не обязательно добавлять в словарь данных.
Связи между таблицами реализованы с помощью внешних ключей (Foreign Key, FK). Внешний (ссылочный) ключ показывает, что поведение записи в одной таблице (зависимой сущности) меняется при изменении или удалении записей из другой связанной таблицы (независимой сущности). Внешний ключ также нужен для объединения двух таблиц. Можно сказать, FK в одной таблице – это один или несколько столбцов, значения которых соответствуют PK в другой таблице. Связь между двумя таблицами задается через соответствие PK в одной таблице FK во второй. Например, в таблице App внешними ключами будут поля product и customer, соответствующие первичным ключам (id) в таблицах Product и Customer соответственно.
После проектирования схемы модели данных в редакторе StarUML, который я часто использую для разработки UML-диаграмм, с помощью расширения Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL, я получила набор SQL-команд по созданию таблиц:
CREATE TABLE public.course (
course_id integer NOT NULL,
course_code char(8) NOT NULL,
course_name text NOT NULL,
course_duration integer NOT NULL,
course_price integer NOT NULL,
PRIMARY KEY (course_id)
);
ALTER TABLE public.course
ADD UNIQUE (course_code);
CREATE TABLE public.customer (
customer_id integer NOT NULL,
customer_name text NOT NULL,
customer_phone char(10) NOT NULL,
customer_email char(20) NOT NULL,
PRIMARY KEY (customer_id)
);
ALTER TABLE public.customer
ADD UNIQUE (customer_email);
CREATE TABLE public.app (
app_id integer NOT NULL,
app_datetime timestamp with time zone NOT NULL,
product integer NOT NULL,
customer integer NOT NULL,
PRIMARY KEY (app_id)
);
CREATE INDEX ON public.app
(product);
CREATE INDEX ON public.app
(customer);
CREATE TABLE public.trainer (
trainer_id integer NOT NULL,
trainer_name text NOT NULL,
trainer_surname text NOT NULL,
trainer_email char(20) NOT NULL,
PRIMARY KEY (trainer_id)
);
ALTER TABLE public.trainer
ADD UNIQUE (trainer_email);
CREATE TABLE public.product (
product_id integer NOT NULL,
product_course integer NOT NULL,
product_trainer integer NOT NULL,
product_date timestamp with time zone NOT NULL,
PRIMARY KEY (product_id)
);
CREATE INDEX ON public.product
(product_course);
CREATE INDEX ON public.product
(product_trainer);
Автоматическая генерация DDL-запросов по спроектированной схеме сэкономила мне время на прописывание SQL-команд вручную, чтобы создать нужные таблицы, определить их атрибуты и связи между таблицами. Полученный код я внесла в бесплатный веб-движок тестирования SQL-запросов https://www.db-fiddle.com/, определив схему SQL. Там же внесла данные в мои таблицы с помощью следующих DML-запросов:
INSERT INTO app VALUES (1, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (2, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (3, '2022-02-01 13:03:05', 2, 3); INSERT INTO app VALUES (4, '2022-02-11 18:20:05', 3, 2); INSERT INTO app VALUES (5, '2022-03-15 09:12:34', 1, 1); INSERT INTO app VALUES (6, '2022-02-01 16:23:05', 4, 2); INSERT INTO app VALUES (7, '2022-02-01 16:07:25', 5, 3); INSERT INTO app VALUES (8, '2022-02-11 12:42:52', 5, 7); INSERT INTO app VALUES (9, '2022-01-01 10:23:54', 1, 1); INSERT INTO app VALUES (10, '2022-02-01 16:23:05', 1, 2); INSERT INTO app VALUES (13, '2022-02-01 14:03:05', 2, 3); INSERT INTO app VALUES (45, '2022-07-10 19:20:05', 7, 2); INSERT INTO app VALUES (51, '2022-03-05 09:12:34', 1, 1); INSERT INTO app VALUES (26, '2022-08-11 15:23:05', 6, 2); INSERT INTO app VALUES (33, '2022-06-19 11:07:25', 5, 3); INSERT INTO app VALUES (44, '2022-05-11 12:42:52', 11, 4); INSERT INTO app VALUES (14, '2022-03-07 09:12:32', 6, 7); INSERT INTO customer VALUES (1, 'Kate', 1234567890, 'kate@email.ru'); INSERT INTO customer VALUES (2, 'Peter', 9604602312, 'peter@email.ru'); INSERT INTO customer VALUES (3, 'Vasya', 4324896011, 'vasya@email.ru'); INSERT INTO customer VALUES (4, 'Elena', 9373601443, 'elena@email.ru'); INSERT INTO customer VALUES (5, 'Vladimir', 3244567012, 'vladimir@email.ru'); INSERT INTO customer VALUES (6, 'Nikita', 1234567890, 'nikita@email.ru'); INSERT INTO customer VALUES (7, 'Dima', 9597473156, 'dima@email.ru'); INSERT INTO customer VALUES (8, 'Boris', 4954289123, 'boris@email.ru'); INSERT INTO customer VALUES (9, 'Nina', 9797283152, 'nina@email.ru'); INSERT INTO customer VALUES (10, 'Alex', 9317473141, 'alex@email.ru'); INSERT INTO trainer VALUES (1, 'Anna', 'Vi', 'anna@email.ru'); INSERT INTO trainer VALUES (2, 'Nick', 'Ko', 'nick@email.ru'); INSERT INTO trainer VALUES (3, 'Olga', 'Bu', 'olga@email.ru'); INSERT INTO course VALUES (1, 'TTIS', 'Technical task and SRS', 12, 20); INSERT INTO course VALUES (2, 'AIRF', 'AirFlow Cluster Andministrator', 24, 60); INSERT INTO course VALUES (3, 'PSYM', 'Psyhology of Management', 8, 10); INSERT INTO course VALUES (4, 'SAL', 'Psyhology of Sales', 16, 20); INSERT INTO course VALUES (5, 'BAMP', 'Business Analysis Management and Planning', 8, 15); INSERT INTO course VALUES (6, 'FTOP', 'Business Analysis for Managers', 8, 15); INSERT INTO course VALUES (7, 'KAFKA', 'Kafka Cluster Administrator', 8, 15); INSERT INTO product VALUES (1, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (2, 2, 2, '2022-08-21 10:23:54'); INSERT INTO product VALUES (3, 3, 3, '2022-09-12 10:23:54'); INSERT INTO product VALUES (4, 6, 1, '2022-04-07 10:23:54'); INSERT INTO product VALUES (5, 6, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (6, 1, 1, '2022-05-17 10:23:54'); INSERT INTO product VALUES (7, 2, 2, '2022-11-01 10:23:54'); INSERT INTO product VALUES (8, 3, 3, '2022-05-04 10:23:54'); INSERT INTO product VALUES (9, 7, 2, '2022-07-07 10:23:54'); INSERT INTO product VALUES (10, 4, 3, '2022-06-20 10:23:54'); INSERT INTO product VALUES (11, 1, 1, '2022-09-27 10:23:54');
Когда схема данных создана и таблицы наполнены, можно приступить к самому интересному: SQL-запросам на выборку нужных данных.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
10 августа, 2026
Продолжительность
22 ак.часов
Стоимость обучения
52 800 руб.
SQL-запросы для анализа данных
Напомню, для доступа к данным в реляционных СУБД используется язык структурированных запросов SQL (Structured Query Language) — декларативный язык программирования. Он содержит операторы определения данных (DDL), манипулирования данными (DML), определения доступа к данным (DCL) и управления транзакциями (TCL). Все эти операторы реализуют не только базовые CRUDL-операции, но и обеспечивают целостность и непротиворечивость информации. В рамках этой статьи мы рассматриваем только самые распространенные DDL- и DML-запросы. Например, следующий запрос покажет, сколько заявок подано на каждый курс:
SELECT course.course_code AS "Код курса",
course.course_name AS "Название курса",
count(*) AS aps_number
FROM app
JOIN product ON product.product_id=app.product
JOIN course ON course.course_id=product.product_course
GROUP BY app.product,
course.course_code,
course.course_name
ORDER BY aps_number DESC;
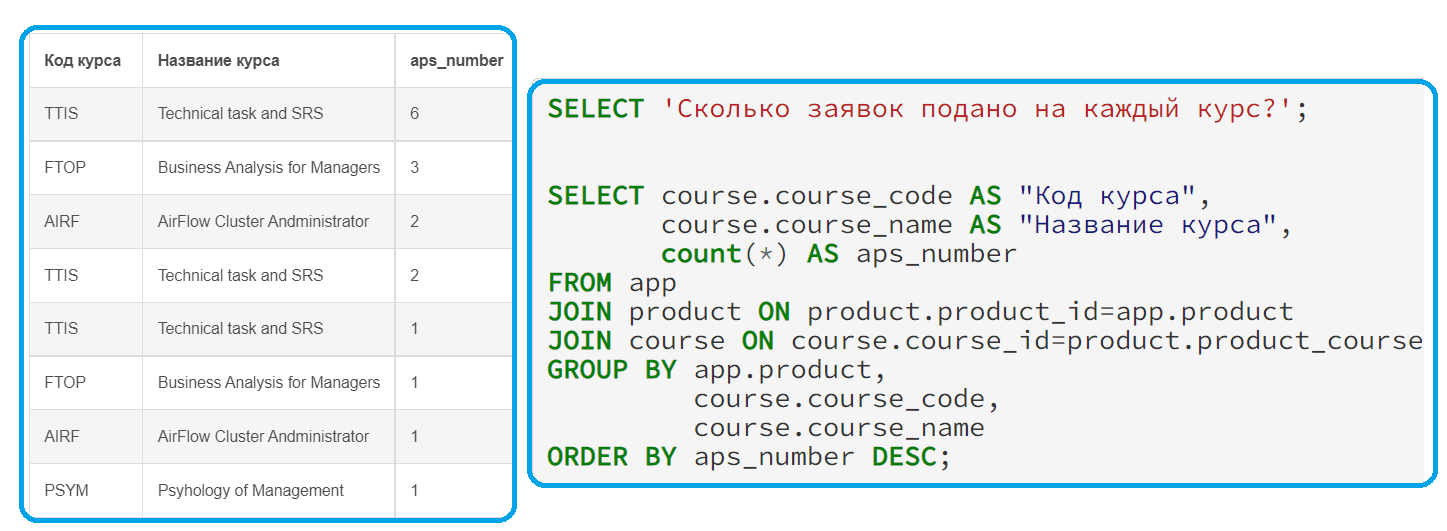
В этом запросе выполнено несколько соединений таблиц через оператор JOIN. Например, чтобы получить код и название курса, таблицу с заявками app нужно было соединить с таблицей продуктов, где указаны внешние ключи курсов, а не сами курсы. А чтобы получить название и код курса, пришлось выполнять соединение с таблицей курсов по внешним ключам, что указывается после ключевого слова ON. Для группировки заявок, поданных по одному и тому же курсу, в конце запроса добавлено выражение GROUP BY, в котором указаны поля группировки. В нашем случае некоторые из них совпадают с теми, что указаны в выборке после ключевого слова SELECT. Оператор COUNT(*) считает все строки таблицы с заявками. За сортировку по убыванию отвечает оператор ORDER BY с уточнением DESC.
Рассмотрим другой бизнес-запрос. Например, нужно определить, сколько денег на каком курсе заработает каждый тренер. На это ответит следующий SQL-запрос:
SELECT course.course_code AS "Код курса",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
GROUP BY course.course_code,
trainer.trainer_name,
course.course_price
ORDER BY income DESC;

В этом SQL-запросе тоже появилась группировка, поскольку здесь выполняется агрегация строк по курсу. Поэтому встречается оператор GROUP BY с указанием полей, по которым выполняется группировка. Агрегатные функции, такие как расчет суммы, среднего или количества строк, выполняют вычисление на наборе ненулевых значений и возвращают одиночное значение. Исключением из этого правила является функция подсчета количества значений COUNT().
Также в запрос добавлен оператор сортировки по убыванию дохода от проведения курса, который вычисляется как произведение стоимости курса на количество поданных заявок. В свою очередь, количество заявок по определенному продукту, с которым связан курс, определяется через соединение с таблицей заявок.
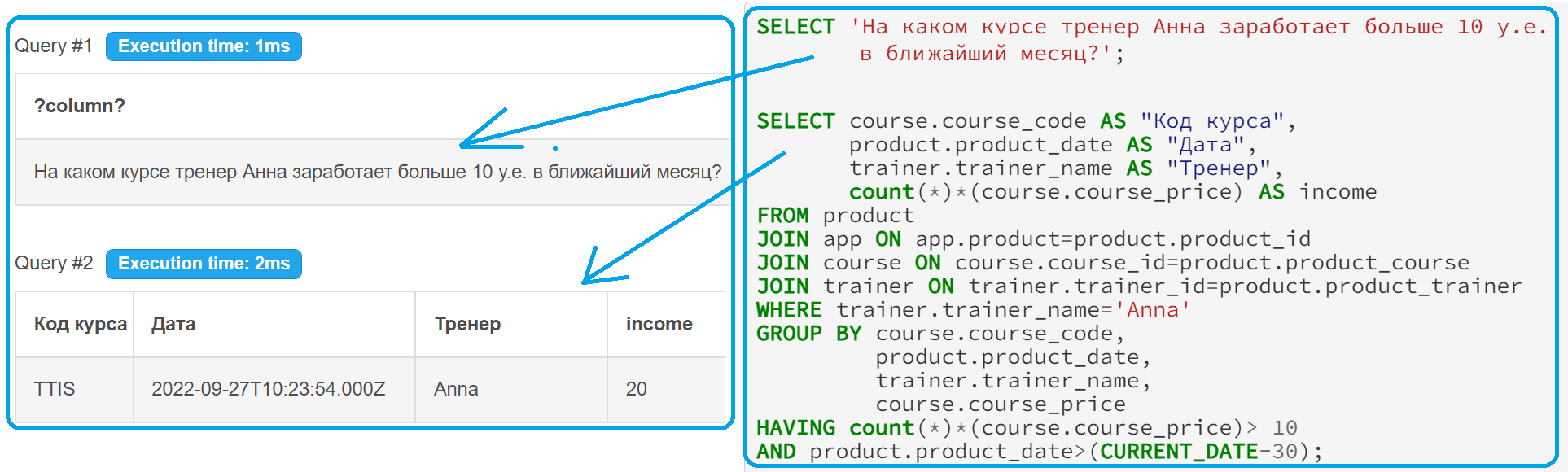
В заключение рассмотрим еще один пример с использованием группировки и фильтрации значений по агрегатным функциям через добавление HAVING после GROUP BY. Например, на каком курсе тренер Anna заработает больше 10 в ближайший месяц от текущей даты? Для этого используем следующий SQL-запрос:
SELECT 'На каком курсе тренер Анна заработает больше 10 у.е. в ближайший месяц?';
SELECT course.course_code AS "Код курса",
product.product_date AS "Дата",
trainer.trainer_name AS "Тренер",
count(*)*(course.course_price) AS income
FROM product
JOIN app ON app.product=product.product_id
JOIN course ON course.course_id=product.product_course
JOIN trainer ON trainer.trainer_id=product.product_trainer
WHERE trainer.trainer_name='Anna'
GROUP BY course.course_code,
product.product_date,
trainer.trainer_name,
course.course_price
HAVING count(*)*(course.course_price)> 10
AND product.product_date>(CURRENT_DATE-30);
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
13 июля, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Аналогичный пример проектирования и использования реляционной модели данных я разбираю в новой статье.
Разумеется, в рамках это статьи не рассматривались все типы SQL-запросов и возможности этого языка. Наиболее эффективным способом освоить их будет самостоятельная работа с выполнением упражнений. Для этого есть множество открытых ресурсов, платных и бесплатных курсов, а также свободных и проприетарных инструментов. В частности, очень советую следующие онлайн-учебники и тренажеры:
- https://sql-academy.org/ru/guide
- https://learndb.ru/articles
- https://www.sql-ex.ru/
- https://stepik.org/course/63054/promo?search=882582677
Чтобы освоить все нюансы проектирования реляционных моделей и написания SQL-запросов к ним, также необходимо читать документацию и выполнять упражнения в соответствующей среде, развернув ее на своем компьютере. Например, для MySQL отлично подходит платформа MySQL Workbench (>https://www.mysql.com/products/workbench/), а для PostgreSQL можно использовать pgAdmin (>https://www.pgadmin.org/). Эти инструменты поддерживают как визуальное проектирование ER-модели, так и выполнение SQL-запросов. Они способны заменить целый набор инструментов, которые использовались при подготовке этой статьи:
- StarUML – среда разработки UML и ER-диаграмм;
- расширение Postgresql DDL Extension for StarUML 2 для создания DDL-запросов к СУБД PostgreSQL по спроектированной диаграмме;
- https://www.db-fiddle.com/ — онлайн-движок реляционных баз данных для тестирования, отладки и обмена фрагментами SQL-запросов;
- https://sqlformat.org/ — онлайн-форматер для операторов SQL, который делает код более читаемым;
- https://postgrespro.ru/docs/postgrespro/14/index — документация по Postgres Pro Standard, популярной объектно-реляционной СУБД.
В заключение отмечу, что проверить, как вы усвоили материал этой статьи можно бесплатно прямо на нашем сайте, выполнив интерактивный тест по основам баз данных и языку запросов SQL.
10 вопросов по основам теории баз данных и SQL: тест для начинающих
А подробнее познакомиться с основами реляционных СУБД и моделированием данных вам помогут курсы Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS

