
Сегодня рассмотрим пример проектирования, реализации и наполнения случайными данными реляционной БД PostgreSQL для последующего выполнения аналитических запросов к ней. Для этого я написала набор Python-скриптов, которые генерируют INSERT-запросы к БД со случайными значениями.
Постановка задачи и проектирование модели данных
Рассмотрим пример интернет-магазина, который продает товары от разных поставщиков. Клиент может забрать каждый заказ самостоятельно или оформить платную доставку от магазина. В магазине действует программа лояльности для покупателей с присвоением им различных статусов в зависимости от общей суммы покупок. Помимо внесения информации о заказах, клиентах, товарах, поставщиках и заказах, необходимы ответы на вопросы аналитического характера, например:
- какие товары продаются чаще всего?
- сколько заказов собрано, но еще не доставлено?
- товары каких поставщиков не продаются вообще?
- сколько заказов были доставлено за эту неделю?
- каков средний чек покупки в магазине?
- Каков средний LTV клиента?
Изучив бизнес-контекст, назначение системы и полный список аналитических вопросов, можно составить модель данных. Для этого выделим набор сущностей доменной области с полями:
- Клиент (Имя, Емейл, Телефон, Статус);
- Заказ (Дата, Сумма, Статус, Товары, Клиент);
- Товар (Название, Поставщик, Цена, Количество). Здесь атрибут Количество указывает, сколько единиц Товара есть в магазине.
- Поставщик (Название, Емейл, Телефон, Адрес);
- Доставка (Дата, Адрес, Стоимость).
Сделаем первую итерацию проектирования инфологической модели данных, т.е. не привязанной к конкретной СУБД.
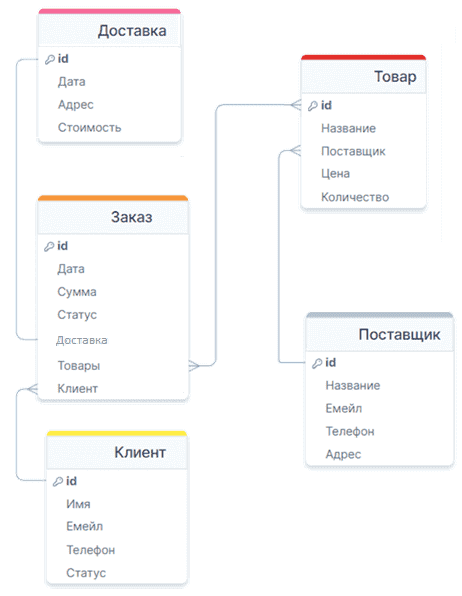
Эта модель имеет связи много-ко-многим между сущностями Заказ-Товар, поскольку один и тот же товар может встречаться во многих заказах, также как один заказ содержит много разных товаров. Необходимо «развязать» эту связь, сделав дополнительную сущность, которая будет содержать поля Заказ и Товар, ссылающиеся на внешние сущности. Кроме того, эта новая сущность (Товары в Заказе) также будет показывать, сколько единиц конкретного Товара имеется в конкретном Заказе.
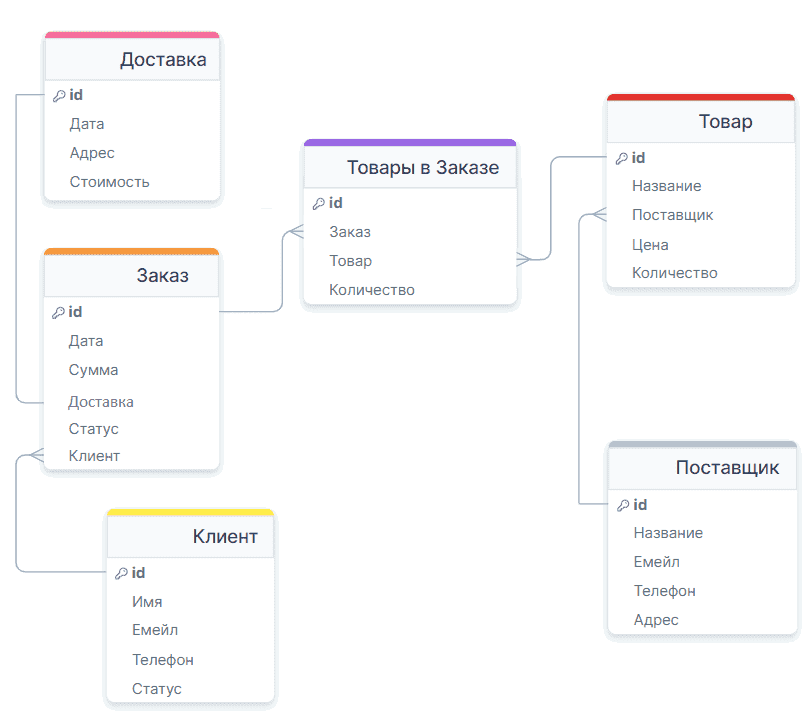
Статусы заказов и клиентов выбираются из ограниченного количества значений. Поэтому их целесообразно вынести в отдельные сущности, сделав таким образом нормализацию модели, т.е. приведение ее к нормальной форме. Это позволяет улучшить целостность данных, исключить противоречивость и несогласованность.
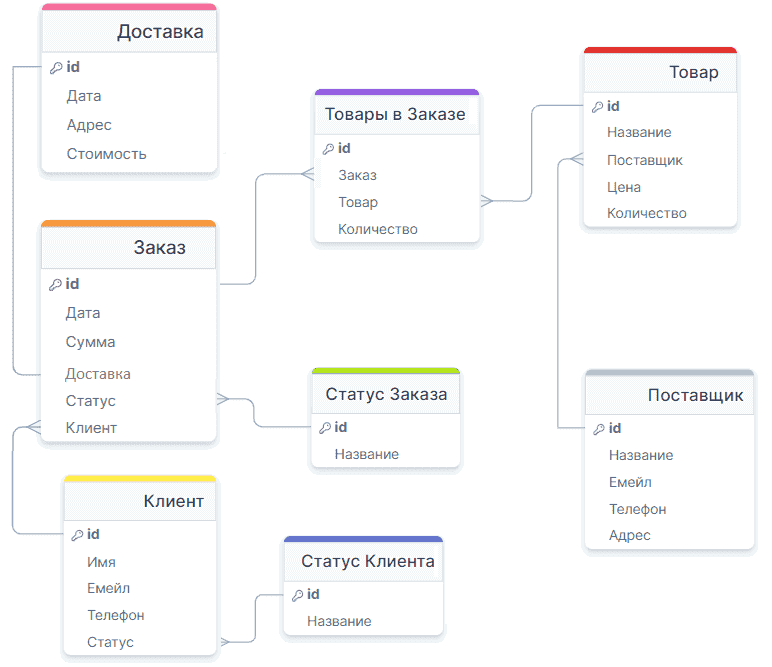
Теперь можно переходить от инфологической модели базы данных к физической, т.е. назначать типы данных каждому атрибуту и привязываться к конкретному решению, т.е. СУБД, которая будет управлять этой БД. Возьмем PostgreSQL – популярную объектно-реляционную СУБД, которая имеет множество встроенных возможностей и дополнительных расширений, отлично подходит как для транзакционных, так и аналитических систем. Чтобы получить из нарисованной схемы DDL-скрипт на создание таблиц БД, все названия сущностей и полей надо написать на английском языке. А также верно проставить типы данных. Например, идентификатор в каждой таблице (id) – это целочисленное поле, которое будет первичным ключом, т.е. уникальным идентификатором строки в таблице. Веб-редактор визуального проектирования drawsql сам подставляет его при создании таблицы. С остальными полями надо поработать вручную. В итоге у меня получилась следующая схема физической модели данных для PostgreSQL. Составим словарь данных для этой модели:
| Таблица | Назначение | Поле | Назначение | Тип данных |
| customer | Клиент | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| name | Имя | сhar (символьный) | ||
| Емейл | сhar (символьный) | |||
| phone | Телефон | сhar (символьный) | ||
| state | Ссылка на Статус Клиента, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| orders | Заказ | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| date | Дата | date (дата YYYY-MM-DD) | ||
| sum | Сумма | Double precision (вещественное двойной точности) | ||
| state | Ссылка на Статус Заказа, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| customer | Ссылка на Клиент, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| delivery | Ссылка на Доставку, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| product | Товар | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| name | Название | сhar (символьный) | ||
| provider | Ссылка на Поставщик, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| price | Цена | Double precision (вещественное двойной точности) | ||
| quantity | Количество | int (целочисленный) | ||
| provider | Поставщик | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| name | Название | сhar (символьный) | ||
| Емейл | сhar (символьный) | |||
| phone | Телефон | сhar (символьный) | ||
| address | Адрес | text (текстовый) | ||
| delivery | Доставка | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| date | Дата | date (дата YYYY-MM-DD) | ||
| address | Адрес | text (текстовый) | ||
| price | Стоимость | Double precision (вещественное двойной точности) | ||
| customer_states | Статус Клиента | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| name | Название | сhar (символьный) | ||
| order_states | Статус Заказа | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| name | Название | сhar (символьный) | ||
| order_product | Товары в Заказе | id | Уникальный идентификатор, первичный ключ (PRIMARY KEY) | int
(целочисленный) |
| order | Ссылка на Заказ, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| product | Ссылка на Товар, внешний ключ (FOREIGN KEY) | int
(целочисленный) |
||
| quantity | Количество | int (целочисленный) | ||
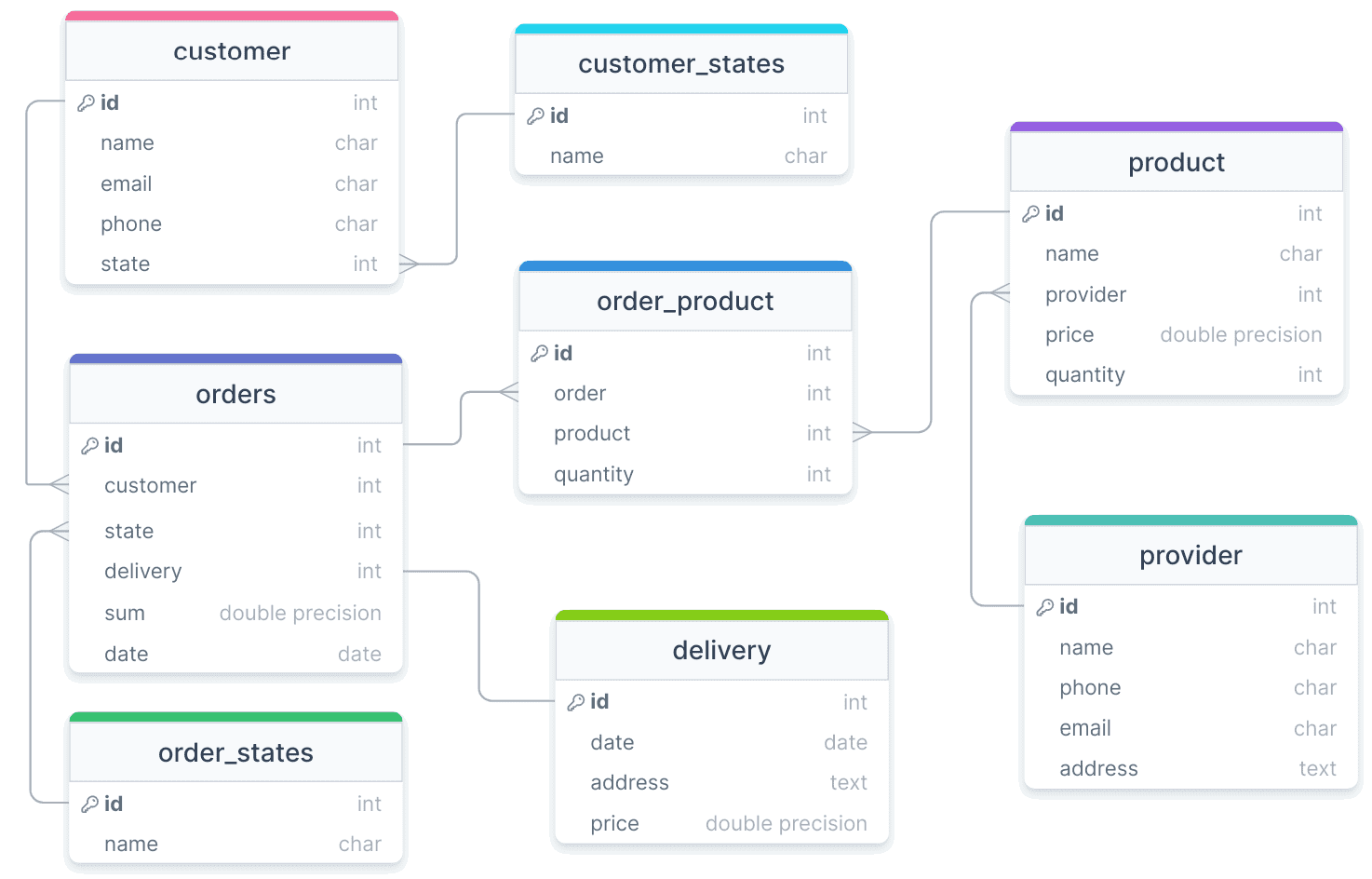
Эта схема была выполнена в онлайн-редакторе https://drawsql.app/ , который позволяет не только визуально спроектировать модель, но и получить DDL-скрипт на создание таблиц:
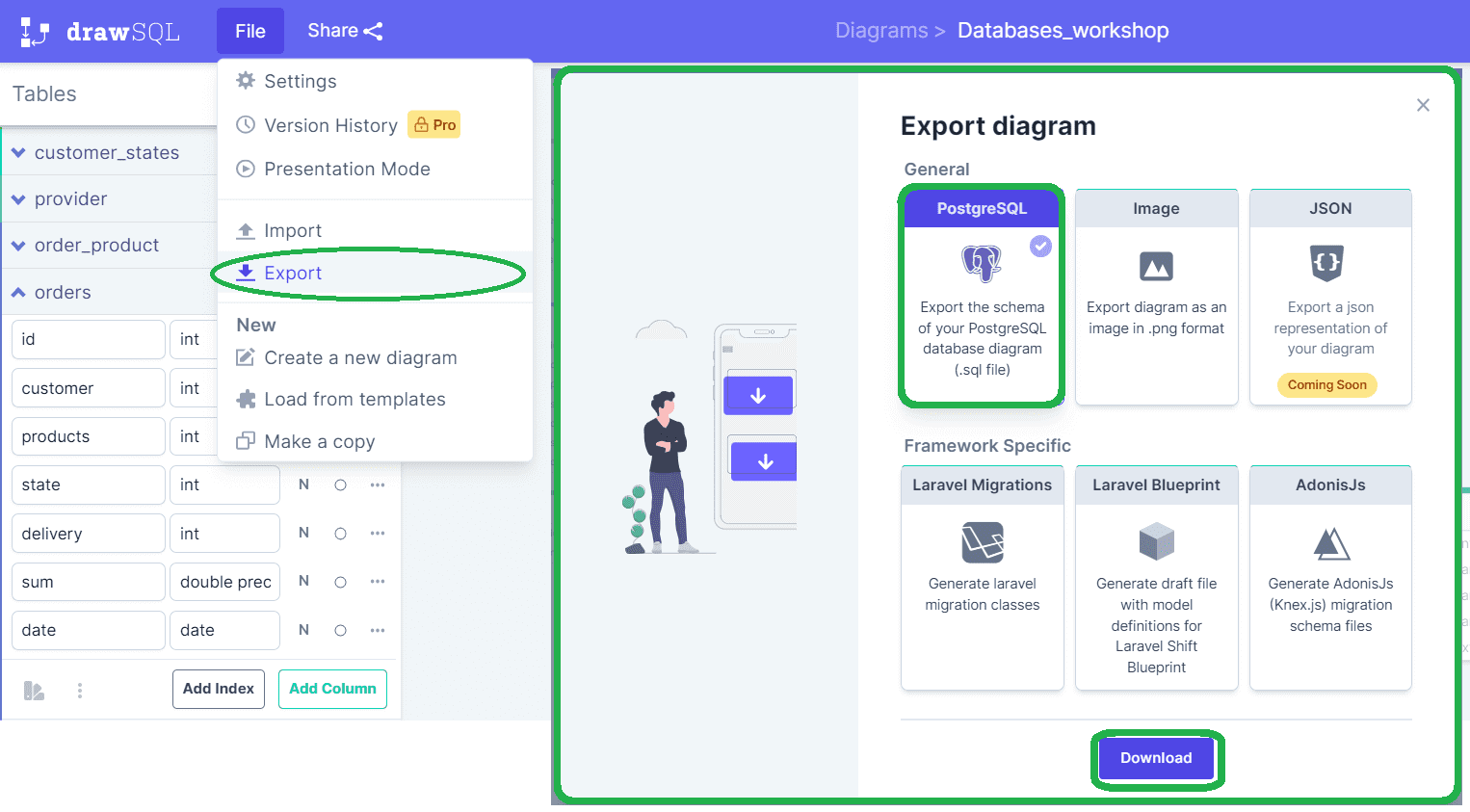
Скрипт выглядит следующим образом:
CREATE TABLE "order_states"(
"id" INTEGER NOT NULL,
"name" CHAR(255) NOT NULL
);
ALTER TABLE
"order_states" ADD PRIMARY KEY("id");
CREATE TABLE "product"(
"id" INTEGER NOT NULL,
"name" CHAR(255) NOT NULL,
"provider" INTEGER NOT NULL,
"price" DOUBLE PRECISION NOT NULL,
"quantity" INTEGER NOT NULL
);
ALTER TABLE
"product" ADD PRIMARY KEY("id");
CREATE TABLE "orders"(
"id" INTEGER NOT NULL,
"customer" INTEGER NOT NULL,
"state" INTEGER NOT NULL,
"delivery" INTEGER NOT NULL,
"sum" DOUBLE PRECISION NOT NULL,
"date" DATE NOT NULL
);
ALTER TABLE
"orders" ADD PRIMARY KEY("id");
CREATE TABLE "order_product"(
"id" INTEGER NOT NULL,
"order" INTEGER NOT NULL,
"product" INTEGER NOT NULL,
"quantity" INTEGER NOT NULL
);
ALTER TABLE
"order_product" ADD PRIMARY KEY("id");
CREATE TABLE "customer_states"(
"id" INTEGER NOT NULL,
"name" CHAR(255) NOT NULL
);
ALTER TABLE
"customer_states" ADD PRIMARY KEY("id");
CREATE TABLE "customer"(
"id" INTEGER NOT NULL,
"name" CHAR(255) NOT NULL,
"email" CHAR(255) NOT NULL,
"phone" CHAR(255) NOT NULL,
"state" INTEGER NOT NULL
);
ALTER TABLE
"customer" ADD PRIMARY KEY("id");
CREATE TABLE "delivery"(
"id" INTEGER NOT NULL,
"date" DATE NOT NULL,
"address" TEXT NOT NULL,
"price" DOUBLE PRECISION NOT NULL
);
ALTER TABLE
"delivery" ADD PRIMARY KEY("id");
CREATE TABLE "provider"(
"id" INTEGER NOT NULL,
"name" CHAR(255) NOT NULL,
"phone" CHAR(255) NOT NULL,
"email" CHAR(255) NOT NULL,
"address" TEXT NOT NULL
);
ALTER TABLE
"provider" ADD PRIMARY KEY("id");
ALTER TABLE
"order_product" ADD CONSTRAINT "order_product_order_foreign" FOREIGN KEY("order") REFERENCES "orders"("id");
ALTER TABLE
"product" ADD CONSTRAINT "product_provider_foreign" FOREIGN KEY("provider") REFERENCES "provider"("id");
ALTER TABLE
"orders" ADD CONSTRAINT "orders_delivery_foreign" FOREIGN KEY("delivery") REFERENCES "delivery"("id");
ALTER TABLE
"orders" ADD CONSTRAINT "orders_state_foreign" FOREIGN KEY("state") REFERENCES "order_states"("id");
ALTER TABLE
"customer" ADD CONSTRAINT "customer_state_foreign" FOREIGN KEY("state") REFERENCES "customer_states"("id");
ALTER TABLE
"order_product" ADD CONSTRAINT "order_product_product_foreign" FOREIGN KEY("product") REFERENCES "product"("id");
ALTER TABLE
"orders" ADD CONSTRAINT "orders_customer_foreign" FOREIGN KEY("customer") REFERENCES "customer"("id");
Однако, просто создать таблицы в БД недостаточно, их надо наполнить данными, чтобы делать SQL-запросы к ним. Заполнять 8 таблиц вручную довольно долго, поэтому я написала Python-скрипт, который будет наполнять таблицы случайными данными.
Разработка ТЗ на информационную систему по ГОСТ и SRS
Код курса
TTIS
Ближайшая дата курса
10 августа, 2026
Продолжительность
22 ак.часов
Стоимость обучения
52 800 руб.
Пишем Python-скрипт с INSERT-запросами
Разумеется, сначала я хотела найти готовый инструмент, который будет наполнять мои таблицы данными. Но существующие сервисы предлагают лишь сгенерировать датасет по своей структуре, например, получить 100 строк с названиями компаний, именами людей, емейлами, телефонами и т.д. Синтаксический разбор внешней схемы данных они не делают. Поэтому пришлось изобретать свой велосипед писать собственный код.
Сперва я хотела написать полноценную программу, которая будет на вход принимать DDL-скрипт, определять таблицы и столбцы в них, включая типы данных, и выдавать DML-скрипт с INSERT-запросами для заполнения базы данных. Однако, оказалось это не так просто из-за ограничений, связанных с внешними ключами. Поэтому я решила сделать следующие заготовки, которыми вы тоже можете воспользоваться для наполнения своих БД, предварительно поменяв структуру таблиц и столбцов.
Начнем с наполнения таблиц-справочников со статусами клиентов:
#скрипт наполнения простой таблицы-справочника из ограниченного количества значений
# задаем название таблицы
table_name = 'customer_states'
# задаем столбцы таблицы
column_names = ('id', 'name')
#создаем список данных - справочник значений
states = ['бронзовый', 'серебряный', 'золотой', 'VIP']
# задаем количество строк таблицы, которое хотим заполнить - для таблицы-справочника это количество значений списка данных
k = len(states)
# генерация и запись DML-скрипта в файл
filename = f'{table_name}.sql' # формируем название выходного файла
with open(filename, 'w') as f: #открытие файла для записи
# формируем строку с названиями столбцов
columns_str = ', '.join(f'"{column}"' for column in column_names)
for i in range(k):
# генерируем значения для каждого столбца
# формируем список со значениями
values = [i+1, f"'{states[i]}'"]
# формируем строку со значениями
values_str = ', '.join(str(value) for value in values)
# формируем и записываем DML-запрос в файл
insert_query = f'INSERT INTO "{table_name}" ({columns_str}) VALUES ({values_str});\n'
print(insert_query) #вывод на консоль - для проверки и отладки
f.write(insert_query) #запись в файл
f.close() #закрытие файла
# Скачиваем файл на локальную машину
files.download(filename)
Этот скрипт не только выводит INSERT-запросы на заполнение таблицы со статусами клиентов данными, но и сохраняет файл с расширением .sql и названием таблицы, заданной в переменной table_name. Запустим скрипт в интерактивной среде Google Colab:
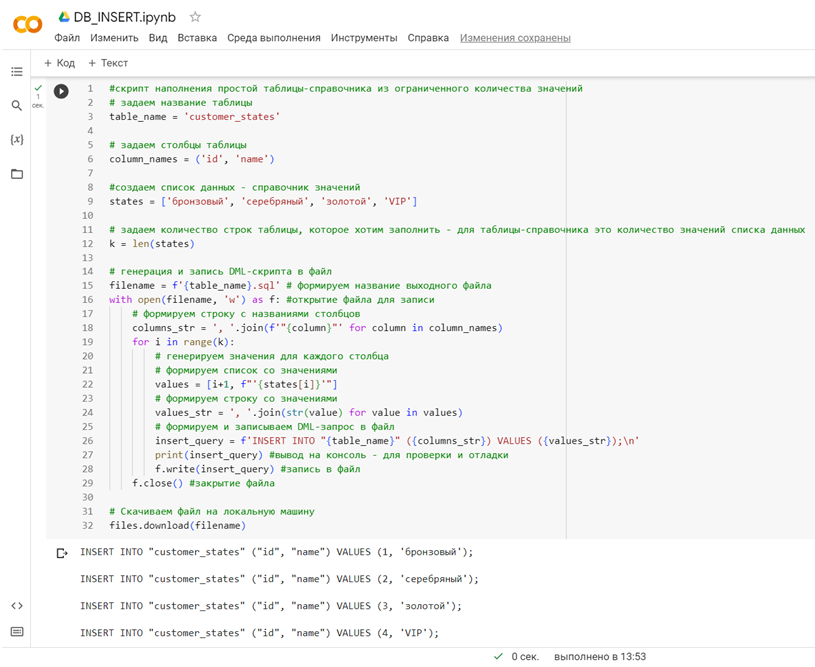
Получим следующий DML-файл:
INSERT INTO "customer_states" ("id", "name") VALUES (1, 'бронзовый');
INSERT INTO "customer_states" ("id", "name") VALUES (2, 'серебряный');
INSERT INTO "customer_states" ("id", "name") VALUES (3, 'золотой');
INSERT INTO "customer_states" ("id", "name") VALUES (4, 'VIP');
Аналогичным образом я получила DML-скрипты для таблицы со статусами заказов, изменив значения списка данных и название таблицы. Для таблицы с доставкой, которая включает адрес, пришлось немного модифицировать скрипт. Чтобы генерировать случайный адрес, я использовала Python-библиотеку Faker с русской локализацией. Код для получения INSERT-запросов для таблицы Доставка выглядит так. Сперва установим необходимые библиотеки и модули:
#############################ячейка №1 в Google Colab - установка библиотек и импорт модулей######################## !pip install Faker import random import datetime from faker import Faker from google.colab import files from faker.providers.address.ru_RU import Provider
Затем напишем сам скрипт наполнения таблицы данными:
#############################ячейка №2 в Google Colab - скрипт наполнения случайными данными таблицы с датой и адресом
# Создание объекта Faker с локализацией для России
fake = Faker('ru_RU')
fake.add_provider(Provider)
# задаем названиие таблицы
table_name = 'delivery'
# задаем столбцы таблицы
column_names = ('id', 'date', 'address', 'price')
# задаем количество строк таблицы, которое хотим заполнить
k = 100
# генерация и запись DML-скрипта в файл
filename = f'{table_name}.sql' # формируем название выходного файла
with open(filename, 'w') as f: #открытие файла для записи
# формируем строку с названиями столбцов
columns_str = ', '.join(f'"{column}"' for column in column_names)
for i in range(k):
# генерируем значения для каждого столбца
# генерируем случайную дату в диапазоне
start_date = datetime.date(2023, 1, 1)
end_date = datetime.date(2023, 12, 31)
random_date = start_date + datetime.timedelta(days=random.randint(0, (end_date - start_date).days))
# преобразуем дату в строку в формате "год-месяц-день"
#для строковых значений обязательно f"'{}'"
date = f"'{random_date.strftime('%Y-%m-%d')}'"
#генерируем случайное значение адреса
address=f"'{fake.address()}'"
#генерируем для суммы денег за доставку случайное вещественное число от 0 до 1000 с двумя знаками после запятой
price=round(fake.pyfloat(right_digits=2, min_value=0, max_value=1000), 2)
# формируем список со значениями
values = [i+1, date, address, price]
# формируем строку со значениями
values_str = ', '.join(str(value) for value in values)
# формируем и записываем DML-запрос в файл
insert_query = f'INSERT INTO "{table_name}" ({columns_str}) VALUES ({values_str});\n'
print(insert_query) #вывод на консоль - для проверки и отладки
f.write(insert_query) #запись в файл
f.close() #закрытие файла
# Скачиваем файл на локальную машину
files.download(filename)
Выполнение этого кода загрузит на ваш компьютер файл с INSERT-запросами, которые можно скопировать и выполнить в интерактивной среде работы с базами данных https://sqliteonline.com/. Все DML и DDL-скрипты для наполнения БД доступны в этой папке моего Github-репозитория
Аналогичным образом я наполнила остальные таблицы. После этого можно их запрашивать, отрабатывая навык написания SQL-запросов на собственной базе данных.
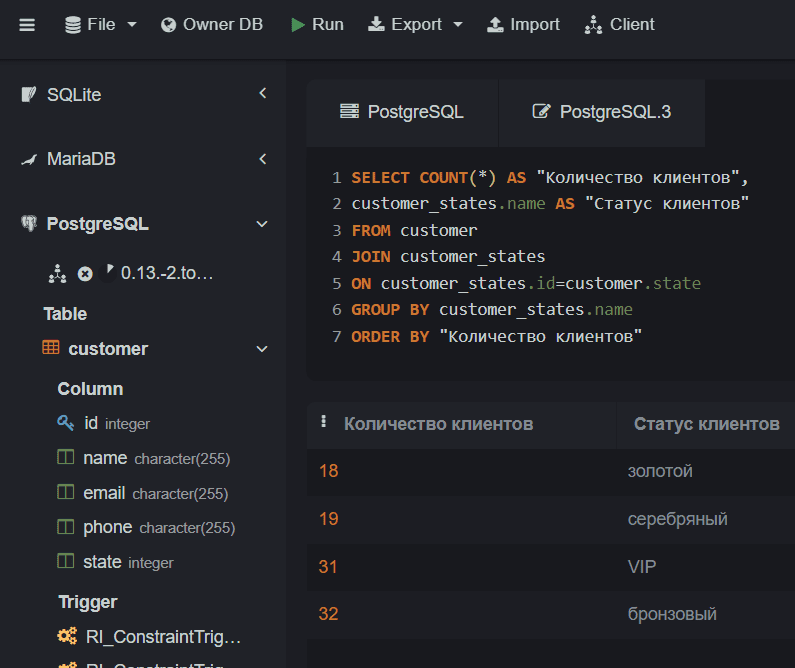
Например, следующий запрос показывает, сколько клиентов у магазина в каком статусе лояльности:
SELECT count(*) AS "Количество клиентов", customer_states.name AS "Статус клиентов" from customer JOIN customer_states on customer_states.id=customer.state GROUP BY customer_states.name ORDER BY "Количество клиентов"
Разумеется, этот пример охватывает не все этапы проектирования базы данных. В частности, здесь я намеренно не стала упоминать про индексы — расскажу в следующий раз. Однако, надеюсь, этот небольшой пример позволил понять некоторые принципы проектирования физической модели данных и ее использования.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
7 сентября, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Подробнее про все эти и другие аспекты архитектуры и интеграции информационных систем, я рассказываю на своих курсах Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Основы архитектуры и интеграции информационных систем
- Разработка ТЗ на информационную систему по ГОСТ и SRS

