
Сегодня на примере резидентной нереляционной базы данных Redis рассмотрим, что представляют собой эти NoSQL-хранилища, а также наполним ее данными, запустив в Google Colab простенький Python-скрипт приложения-потребителя данных из Apache Kafka.
Что такое Redis и где это используется: краткий обзор резидентной NoSQL-СУБД
О том, какие бывают нереляционные базы данных, я уже писала здесь. И даже в отдельных статьях подробно рассказывала про некоторые из них, документо-ориентированные и графовые, на примере MongoDB и Neo4j соответственно. Дошла очередь и до key-value базы данных. В качестве наиболее простого и доступного примера возьмем резидентную NoSQL-СУБД Redis (REmote DIctionary Server), которая работает очень быстро за счет хранения данных в оперативной памяти сервера. Поэтому она и называется резидентная. Впрочем, при необходимости данные из Redis можно сохранить на жесткий диск.
Главным преимуществом Redis является высокая скорость работы, но эта база не предназначена для хранения больших объемов данных из-за примитивного, но очень эффективного принципа хранения данных по типу ключ/значения. Хранение данных в памяти дополнительно ограничивает размер данных. Поэтому Redis не используется как постоянное хранилище, но часто играет роль промежуточного слоя, кэша между приложениями реального времени и большой, но не очень быстрой базой данных типа PostgreSQL. Например, в Redis очень удобно хранить кэши результатов запросов к постоянному хранилищу, пользовательских сессий, веб‑страниц, метаданных и других часто используемых объектов.
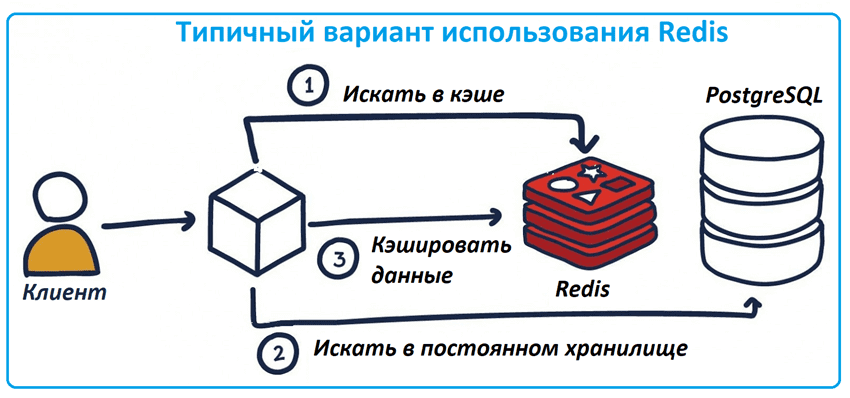
Благодаря миллисекундной задержке в обработке запросов, Redis отлично подходит для аналитики данных в реальном времени, например, когда несколько микросервисов взаимодействуют друг с другом через Apache Kafka или RabbitMQ. Именно этот случай мы и попробуем рассмотреть, насколько это возможно в облачной платформе Upstash. Но перед этим следует сказать про типы данных, которые есть в Redis, поскольку эта нереляционная СУБД использует собственный язык команд для работы с ними вместо стандартного SQL.
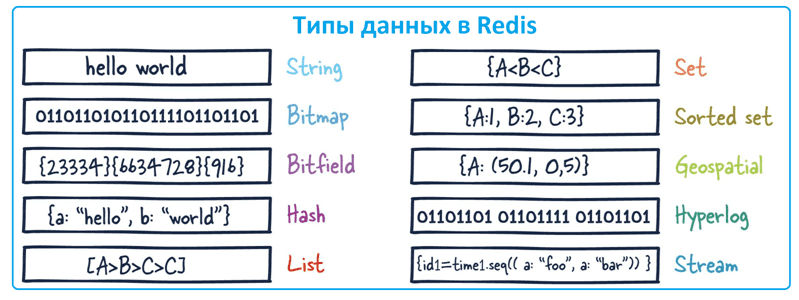
Redis поддерживает следующие типы данных:
- строка (string) – текстовые или двоичные данные до 512 Мб;
- список (list) – набор строк, упорядоченный в порядке добавления с начала или с конца;
- множество (set) – не упорядоченный набор строк, над которыми возможны все математические операции со множествами (вставка, проверка вхождения элемента, пересечение и разность);
- упорядоченное множество (sorted set) – набор уникальных строк, которые сохраняют порядок в соответствии с оценкой, связанной с каждой строкой (score);
- хэш-таблица (hash) – ассоциативный массив с парами ключ/значение;
- битовый массив (bitmap) – массив битов, позволяющий выполнять операции на уровне битов;
- битовое поле (Bitfield), чтобы кодировать несколько счетчиков в строковом значении, обеспечивая атомарные операции получения, установки и увеличения с поддержкой разных политик переполнения.
- HyperLogLog– вероятностная структура данных для оценки количества уникальных элементов в наборе данных;
- Geospatial – геопространственные индексы, полезные для решения геоинформационных и логистических задач, например, поиск местоположений в пределах заданного географического радиуса или координат;
- поток (Stream)– очередь сообщений со структурой данных в виде лога.
Познакомившись с Redis, рассмотрим некоторые принципы ее работы на практическом примере. Для этого развернем собственный инстанс этой NoSQL-СУБД в облачной платформе Upstash и наполним ее данными из Apache Kafka. Как это сделать, я расскажу далее.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
13 июля, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Практический пример с Kafka
Воспользуемся облачным сервером Redis, развернув собственный экземпляр на платформе Upstash. Я уже упоминала про эту замечательную платформу в статье о Kafka. Впрочем, в сегодняшнем примере тоже задействуем Kafka, немного модифицировав приложение-потребитель из топика, чтобы оно отправляло некоторые данные в Redis.
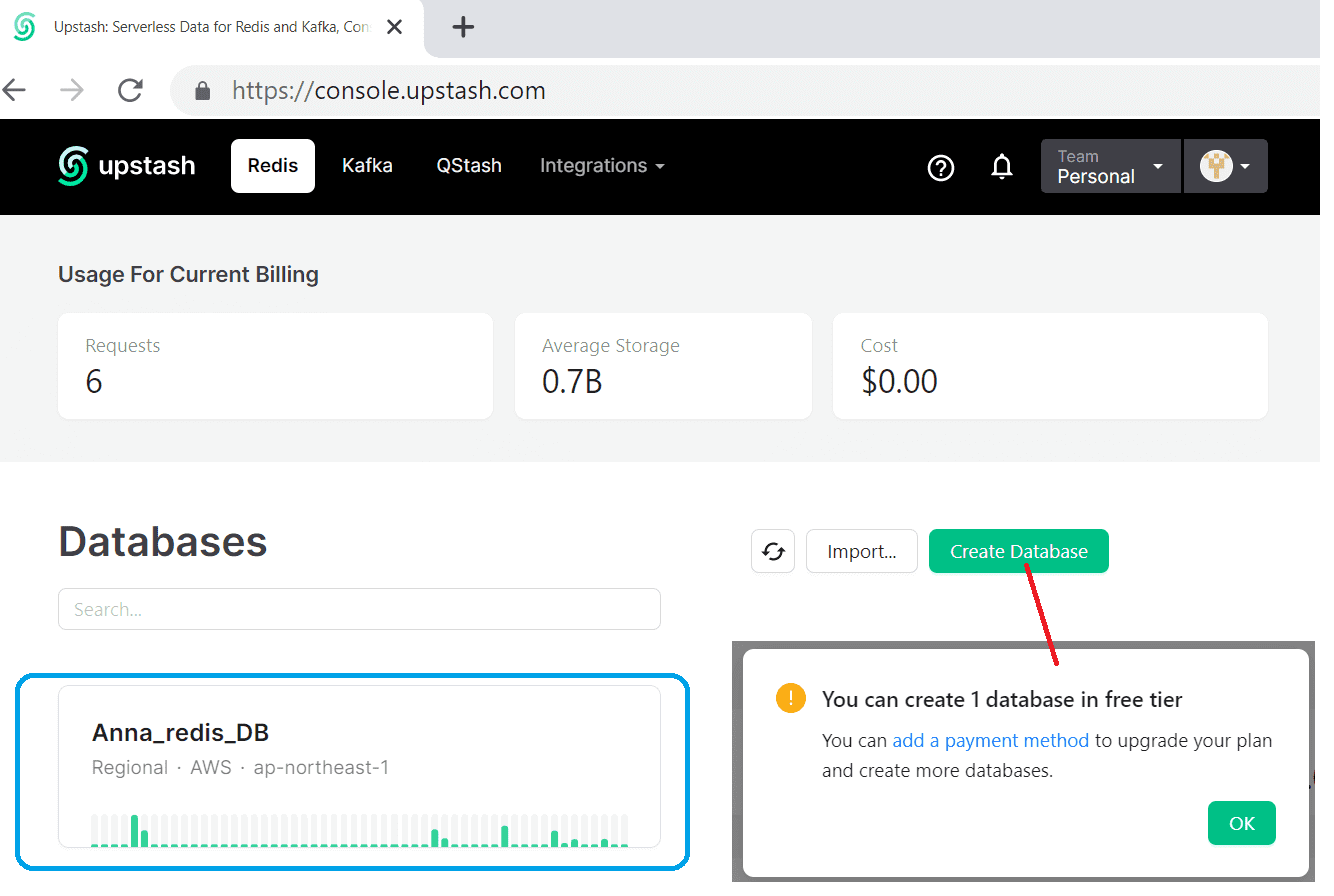
Сперва создадим свою базу данных. На бесплатном тарифе Upstash позволяет создать только 1 экземпляр.
Чтобы не наполнять созданную базу данных вручную, я решила наполнить ее данными, которые сперва поступают в Apache Kafka, также развернутой в Upstash, от приложение-продюсера. Продюсер (умный датчик) создает данные с 2-мя видами измерений (температура и давление) по множеству устройств и отправляет их в Kafka. Эти данные и обрабатывает одно приложение-потребитель, которое отправляет в Redis сведения по ошибкам прибора. Предположим, ошибкой измерения давления считаются показания менее 10 и более 50, а ошибкой измерения температуры – значения менее 20 и более 80.
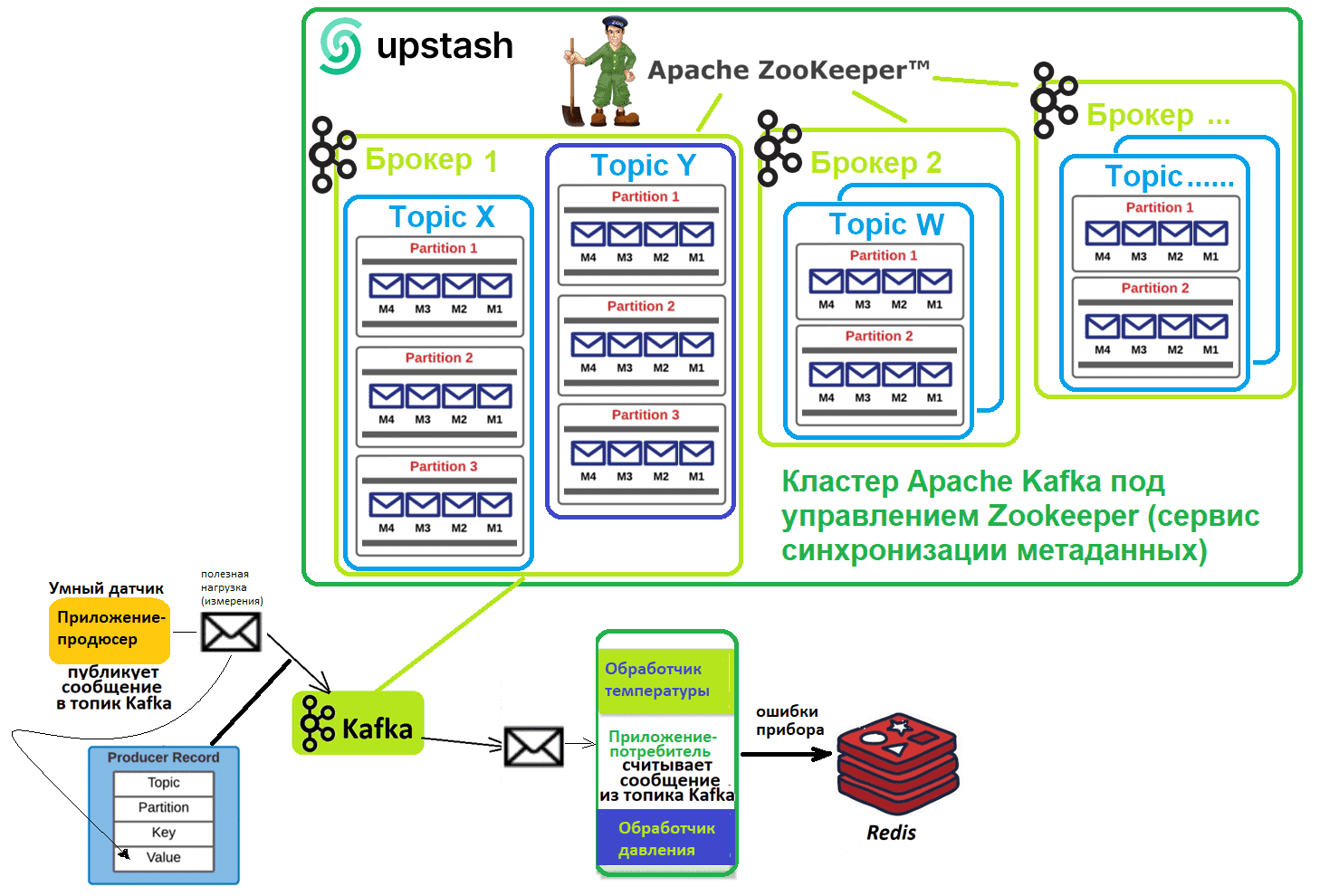
Ключом в Redis будут номера устройств, а значениями – записи об ошибках измерения температуры или давления на этих устройствах. Код приложения-продюсера, которое отправляет измерения в Kafka, не изменился с прошлой статьи. А код приложения-потребителя, которое считывает данные из Kafka и некоторые из них записывает в Redis, пришлось немного модифицировать. Как обычно, я пишу и запускаю Python-код в блокнотах Google Colab – интерактивной легковесной облачной среде разработки. Прежде всего, в ячейку с командами установки библиотек надо добавить клиент Redis:
!pip install kafka-python !pip install redis import json import random import time
Учетные данные для подключения к своей базе сразу в виде кода на нужном языке программирования можно просто скопировать из интерфейса Upstash.
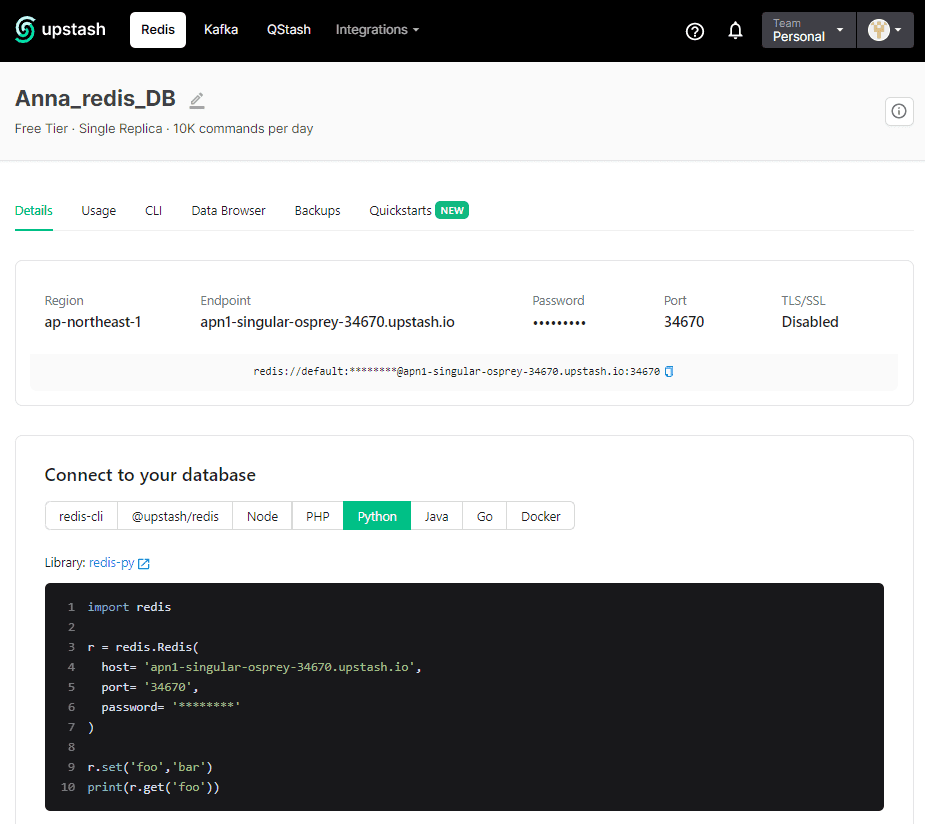
Эти учетные данные я вставила в немного измененный код приложения-консумера:
from kafka import KafkaConsumer
import json
from json import loads
from kafka.structs import TopicPartition
from datetime import datetime, timedelta
import redis
r = redis.Redis(
host= 'здесь должен быть ваш хост, на котором развернут Redis',
port= 'порт для доступа к Redis',
password= 'пароль'
)
consumer = KafkaConsumer(
bootstrap_servers=['URL-адрес_вашего_инстанса_Kafka:порт(обычно_9092)'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='имя_вашего пользователя',
sasl_plain_password='пароль_вашего_пользователя',
group_id='$group',
auto_offset_reset='earliest'
)
consumer.subscribe(['anna_demo_topic'])
for message in consumer:
print (message)
payload=message.value.decode("utf-8")
data=json.loads(payload)
device_state=''
device_measure=''
if (data['measure']== 'pressure'):
device_measure='pressure'
if ((data['value']<= 50) and (data['value'] >= 10)):
device_state='OK'
else:
device_state='ERROR'
else:
device_measure='temperature'
if ((data['value']<= 80) and (data['value'] >= 20)):
device_state='OK'
else:
device_state='ERROR'
if (device_state=='ERROR'):
ts = datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
r.rpush(data["device"], ts + " "+ device_measure +" "+ str(data['value']) +" " + device_state,)
print("Устройство № ", data["device"], device_measure, device_state, "значение ", data['value'])
В этом коде за запись данных об ошибках измерений на устройствах в Redis отвечает функция RPUSH, которая вставляет все указанные значения в конец списка, хранящегося в ключе. Поскольку платформа Upstash не поддерживает тип данных Stream, для логирования событий с ошибками измерения, буду использовать структуру списка — набор строк, упорядоченный в порядке добавления с начала или с конца.
В качестве ключа я задала номер устройства (поле device из JSON-документа полезной нагрузки сообщения, считанного из Kafka), а в качестве значений этого ключа будет строка, содержащая текущее время (ts), вид измерения (device_measure, pressure или temperature), статус измерения (ERROR) и фактическое значение измерения. Справедливости ради стоит отметить, что время, когда фактически произошло событие ошибки, записывается в Kafka и его следовало бы считать оттуда. Но мне уже было лениво писать обработчик отметки времени (timestamp) для сообщения, считанного из топика. Для упрощения эксперимента будем считать, что отправка и считывание данных происходят в режиме реального времени без какой-либо задержки, и фактическое время события равно текущему.
Если ключ в Redis не существует, функция RPUSH создаст пустой список перед записью значений. Это как раз наш случай, т.к. заранее неизвестно, на каких именно устройствах могут случиться ошибки измерений (приложение-продюсер генерирует эти данные случайным образом). В GUI платформы Upstash можно посмотреть, как данные записываются в Redis.
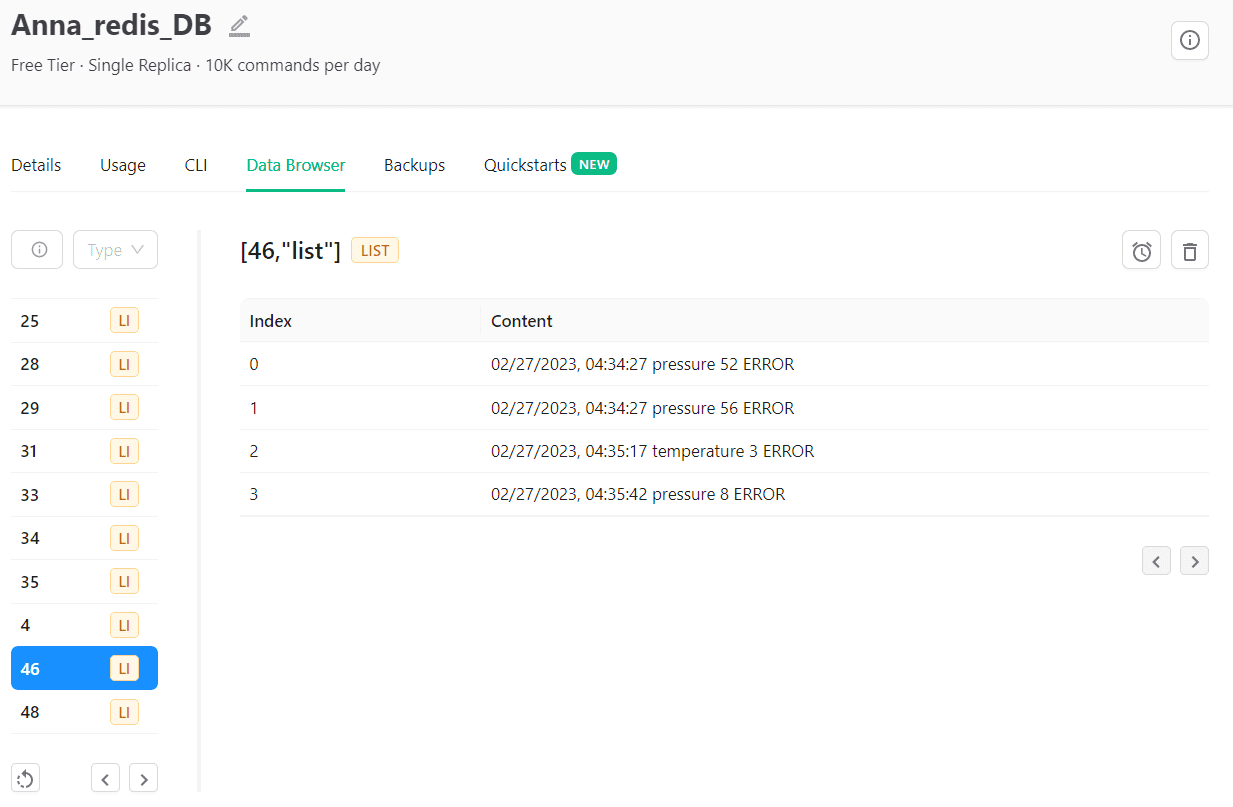
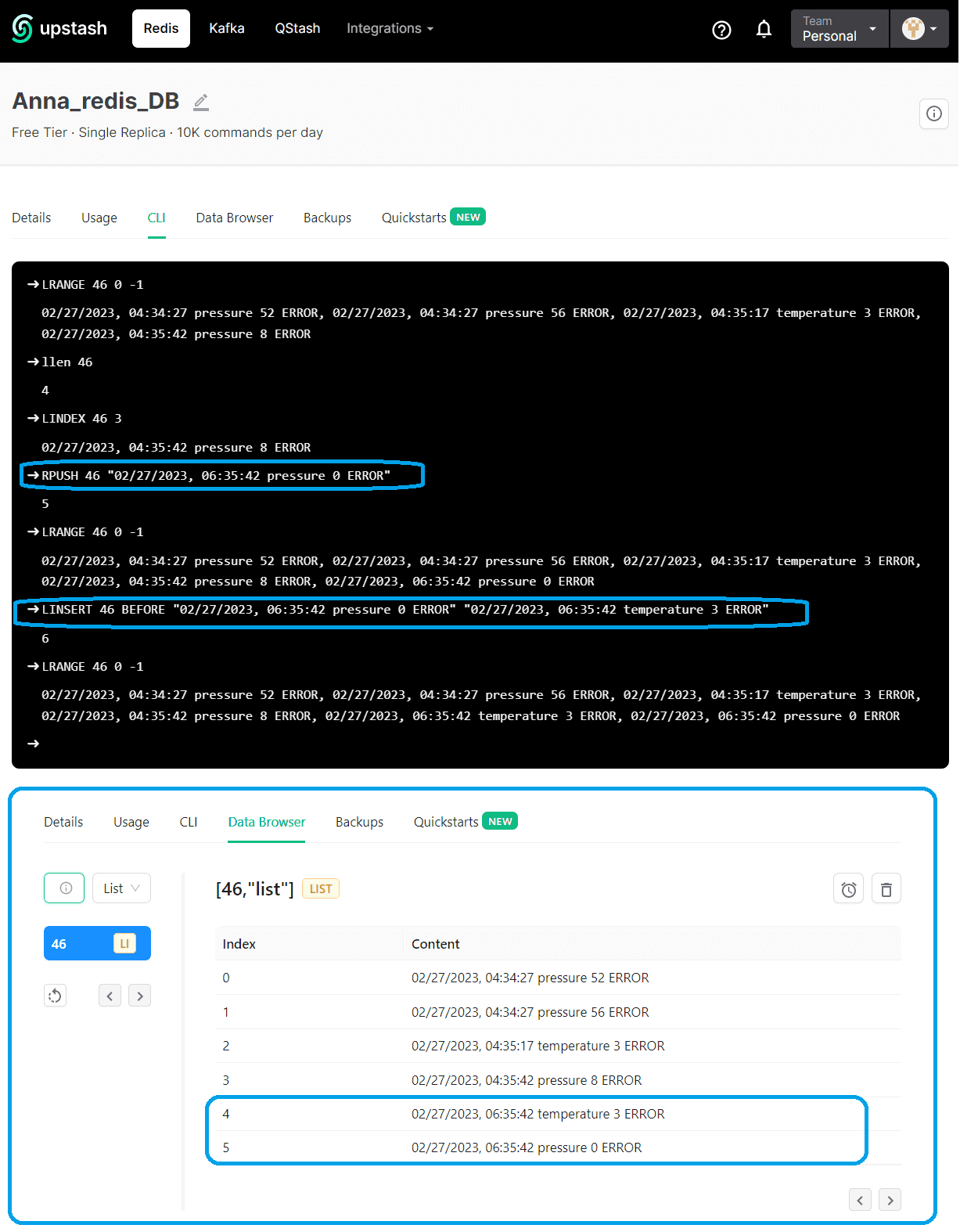
Просмотреть содержимое базы данных также можно в веб-интерфейсе платформы. Например, какие ошибки произошли на устройстве с номером 46.
Впрочем, просмотреть эти данные можно, реализовав вывод из приложения-консумера с помощью следующего кода:
r = redis.Redis( host= 'здесь должен быть ваш хост, на котором развернут Redis', port= 'порт для доступа к Redis', password= 'пароль' ) r.lrange(46, 0, -1)
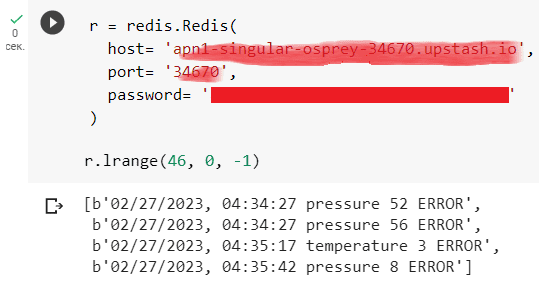
Здесь команда LRANGE возвращает указанные элементы списка, хранящегося в ключе (46) с начального, т.е. элемента с индексом 0 до последнего с индексом -1.
Также платформа Upstash предоставляет интерфейс командной строки для обращения к Redis, где можно напрямую вызывать команды. Например, сперва я посмотрела список значений ключа 46, затем получила длину этого списка с помощью команды LLEN и посмотрела значение списка с индексом 3 (предпоследнее). Далее добавила новое значение в список снова с помощью RPUSH и вставила новое значение перед ним, используя команду LINSERT. Теперь список ошибок устройства 46 содержит больше записей, что отображается как в GUI, так и в CLI-интерфейсах Redis.
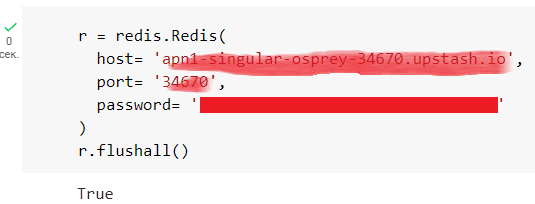
В процессе разработки и тестирования мне требовалось очищать базу данных от прежних записей. Чтобы не удалять по одному ключу за раз, можно сразу очистить все содержимое, вызвав команду FLUSHALL, которая удаляет все ключи всех существующих баз данных Redis. Вызвать эту команду можно как в CLI-интерфейсе, так и в коде Python-приложения.
Разумеется, в этой небольшой статье описаны далеко не все функции Redis. Подробнее о практическом применении Redis также читайте в моем новом материале. Однако, надеюсь, этот небольшой пример позволил вам понять основные нюансы работы этой NoSQL-СУБД и познакомиться с ее возможностями, чтобы описывать хранимые в ней структуры данных при разработке требований к ПО и в проектах интеграции информационных систем.
Основы архитектуры и интеграции информационных систем
Код курса
OAIS
Ближайшая дата курса
13 июля, 2026
Продолжительность
25 ак.часов
Стоимость обучения
60 000 руб.
Подробнее про все эти и другие аспекты архитектуры и интеграции информационных систем, я рассказываю на своих курсах Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
Источники

