
Чем MCP-сервер отличается от обычного API: почему недостаточно просто определить инструменты, ресурсы и промпты, для чего надо подробно описывать возможности и поля данных, зачем подозревать ИИ-клиентов в недобросоветных намерениях и как снижать риски утечки и потери данных.
Что такое MCP и зачем это нужно: краткий ликбез
До 2025 года, чтобы превратить чат-бот с LLM в полноценного ИИ-агента, который не только «знает», но и «умеет», т.е. может выполнять нужные действия через самостоятельные вызовы внешних сервисов, нам, ИТ-специалистам, приходилось проектировать и реализовывать все эти межсистемные интеграции.
Например, аналитик определяет требования к API нового REST-сервиса, затем с помощью LLM пишет на него спецификацию OpenAPI и проверяет ее в Swagger UI или импортирует в Postman. После ручного тестирования находит ошибки или несоответствие корпоративным стандартам, уточняет промпт и, наконец, публикует приемлемую документацию в общую базу знаний или систему управления требованиями, чтобы потом поставить задачи на разработку по этому проектному артефакту. Тестировщик, опять же, с использованием нейросетевого бота, проектирует и пишет тест-кейсы, по которым потом проводит функциональное тестирование. Эта проверка на соответствие полезной нагрузки запросов и ответов OpenAPI-контракту может проводиться с помощью Pre- и Post-скриптов в том же Postman или другом специализированном инструменте (Apidog, Bruno, Insomnia и пр.). По результатам тестирования в корпоративном таск-трекере формируются задачи на исправление найденных ошибок.
Разумеется, в большинстве компаний подобный SDLC-конвейер был автоматизирован в части прямой интеграции между системами по точным сценариям, например, рассылка уведомлений командам клиентов при выпуске новой версии API сервера и т.д. Однако, активное использование нейросетей в процессы жизненного цикла ПО привело к парадоксу: интеллектуальную работу по проектированию и разработке делают за секунды нейросети, а квалифицированный ИТ-специалист становится оператором, выполняющим простые операции копировать-вставить. Кроме неэффективного использования человеческого ресурса, такие ручные действия – потенциальные точки возникновения ошибок, когда скопирован и вставлен не тот участок кода, или в публичную LLM случайно утекли конфиденциальные данные. Поэтому, чтобы обеспечить переход от автоматизации локальных задач к изменению процессов и бесшовной интеграции ИИ с прикладными инструментами, в конце 2024 года компания Antropic, разработчик многих современных языковых моделей и чат-бота Claude, выпустила протокол MCP (Model Context Protocol). В 2025 году он стал стандартом взаимодействия LLM-клиентов (Claude Desktop, Cursor и пр.) с внешними серверами и инструментами через обмен сообщениями по протоколу JSON-RPC 2.0.
Сегодня MCP-протокол называют USB для ИИ-мира, т.к. он решает проблему совместимости, объединяя внешние инструменты и источники данных одним универсальным стандартом подключения. Таким образом, ИИ-модель теперь может не просто сгенерировать текст, спецификацию или код по пользовательскому промпту, но и выполнить с ним активные действия (опубликовать, развернуть и пр.) без участия человека. Такой уровень автономного принятия решений и совершения действий соответствует агентскому ИИ. А чтобы подобная самостоятельность нейросети не превратилась в «нашествие машин» с непоправимыми последствиями, когда утекли или потеряны важные данные, нужно обеспечить строгий контроль безопасности через изоляцию среды, проверку полномочий и обязательное подтверждение критических действий человеком. Этот подход называется Human—in—the—Loop и реализуется с помощью инженерных практик и организационных приемов: ограничение доступа к данным, их анонимизация, изоляция среды, непрерывный мониторинг и аудит всех действий, а также постоянное повышение квалификации пользователей ИИ-инструментов в области инфобеза.
Чтобы понять, как это влияет на MCP-серверы, и почему их проектирование отличается от разработки другого API (REST, GraphQL, SOAP или gRPC-приложения), сперва вспомним, как работает MCP-протокол.
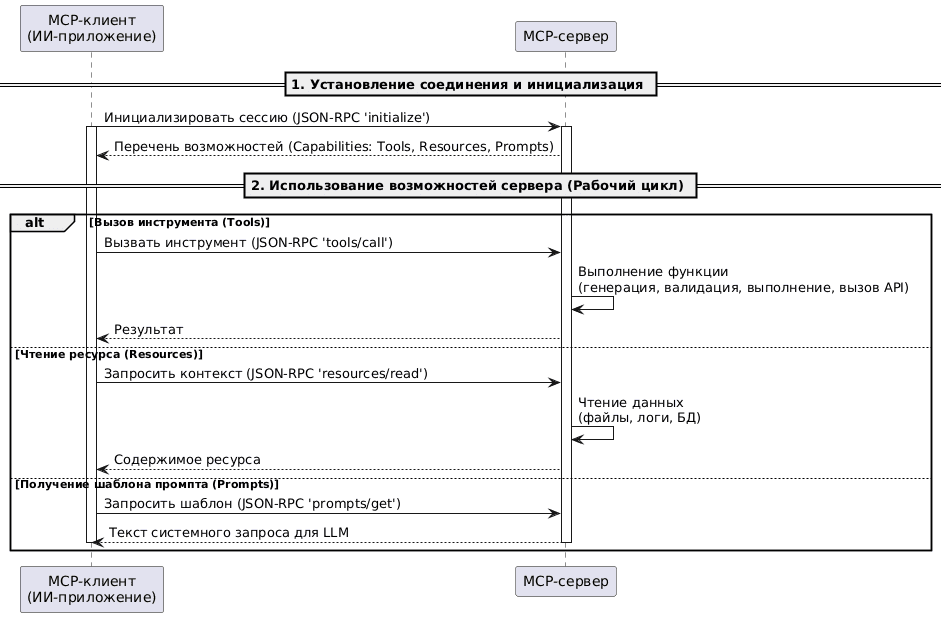
Клиент-серверное взаимодействие через MCP-протокол реализуется следующим образом:
- MCP-клиент подключается к MCP-серверу и отправляет JSON-RPC сообщениеinitialize. При локального общения, когда клиент и сервер запущены на одном и том же компьютере, для передачи данных используется протокол STDIO (стандартный ввод-вывод) – базовый механизм в операционных системах, который позволяет программам напрямую обмениваться данными через оперативную память. Для распределенной интеграции, когда клиент и сервер расположены на разных хостах, в качестве транспорта используется HTTP-протокол: клиент отправляет серверу POST-запросы, передавая JSON-RPC сообщение в теле. А сервер общается с клиентом через SSE (Server-Sent Events) – технологию HTML5, позволяющую отправлять данные клиенту в реальном времени по HTTP-протоколу без постоянных запросов с клиентской стороны.
- В ответ на сообщение инциализации, MCP-сервер возвращает клиенту свои возможности (capabilities):
- Инструменты (Tools) – исполняемые функции, которые можно вызвать удалённо для выполнения действий, например, сгенерировать файл, провалидировать схему, отправить запрос внешнему приложению и пр.
- Ресурсы (Resources) – данные, доступные клиенту для чтения в качестве контекста — актуальные файлы стандартов, логи, живые данные из хранилищ и т.д.
- Промпты (Prompts) – предустановленные шаблоны системных запросов, которые помогают правильно поставить задачу перед LLM.
- Далее клиент использует эти возможности MCP-сервера, отправляя JSON-RPC сообщение с вызовом tools/call для обращения к инструменту, resources/read для доступа к нужному ресурсу или prompts/get для подходящего промпта.
Почему MCP-сервер это не просто очередной API
На первый взгляд, может показаться, что, с учетом основных концепций MCP-протокола, проектирование MCP-сервера сводится к определению его возможностей, т.е. ресурсов, промптов и инструментов:
- зафиксировать в ТЗ перечень функций как список инструментов, добавить к ним действия по отображению ресурсов и промптов, определить контракты данных для сообщений по стандарту JSON-RPC;
- задать нефункциональные требования в измеримых показателях для производительности, безопасности, надежности и доступности сервера.
Однако, в отличие от API обычного веб-приложения, основным клиентом MCP-сервера является не человек или система с четко определенными сценариями (фронтенд или бэкенд внешнего сервиса), а LLM. Нейросеть сама решает в какой момент, с какими параметрами и в какой последовательности вызывать возможности MCP-сервера, с учетом системного промпта и текущего диалога с пользователем. Эта особенность нечеткой постановки задач на естественном языке принципиально меняет проектирование, смещая фокус от подхода SpecFirst к декларативному риск-ориентированному текстовому описанию правил клиент-серверного взаимодействия:
- семантика становится важнее строгого контракта. Заполнение свойства description для описания инструмента или поля в схеме данных не опционально, а обязательна, чтобы ИИ-модель могла его правильно интерпретировать и корректно использовать. Однако, с учетом ограничений контекстного окна и проблемы «потери середины», о чем я еще скажу дальше, описание должно быть достаточным для понимания, но не избыточным: «пиши, сокращай».
- определение границ применения. В описании инструмента важно указывать не только то, что он делает, но и когда его НЕЛЬЗЯ вызывать. Например: «Используй этот инструмент только если пользователь явно указал, в каком окружении разворачивать этот контейнер, не пытайся его угадать».
- дополнительная защита от галлюцинаций. В отличии от обычного межсистемного взаимодействия по точным сценариям, генеративный характер LLM приводит к тому, что нейросеть может ошибиться в формате данных, перепутать названия или порядок аргументов, придумать несуществующие факты и пр. Поэтому для MCP-сервера нужны гибкие парсеры, способные очищать данные от таких галлюцинаций: убирать лишние кавычки, преобразовывать форматы, валидировать аргументы и т.д.
- ответы сервера с учетом итеративной генерации. MCP-сервер должен не просто отдавать корректные статусы ответа по HTTP-протоколу (200 ОК, 201 Created и пр.), а возвращать детальный текстовый контекст, который подскажет модели её следующий шаг. Понятное описание поможет LLM выполнить повторную генерацию и/или вызвать другой, более подходящий инструмент или промпт. Например, «Пользователь с номером +7xxxxxxxxx не найден в текущей базе CRM. Попробуй найти его по адресу электронной почты, используя инструмент find_user_by_email». Получив такой ответ, нейросеть сама исправит свой запрос в следующей итерации.
- предупреждение бесконечных циклов (Agentic Loops), когда автономный ИИ-агент, получив ошибку вызова инструмента или неполные данные ресурса, уходит в непрерывную саморефлексию, пытаться вызывать ту же возможность MCP-сервера снова и снова, тратя токены и перегружая сервер. Для этого нужна идемпотентность повторных вызовов, кэширование результатов и лимиты обращений (rate limiting) от одного ИИ-агента в рамках одной сессии.
- ограниченность контекстного окна. Для обычного API объем ответа ограничен возможностями сети и памяти. В MCP слишком большой ответ сервера (например, дамп логов на 50 Мб через resources/read) может мгновенно заполнить контекстное окно нейросетевого клиента. Хотя контекстные окна современных нейросетей стремительно растут с помощью механизмов компрессионной памяти или гибридных архитектур со сменяемым состоянием, долгий диалог с LLM приводит к феномену «потери середины». Это значит, что ИИ-модель отлично помнит начало разговора и его конец, но начинает путаться в фактах, которые находились в середине большого массива передаваемых данных. Кроме того, каждый большой запрос стоит денег и времени обработки, т.к. приходится пересчитывать огромные массивы данных. Поэтому, MCP-сервер должен поддерживать пагинацию, чтобы возвращать данные частями, агрегировать и фильтровать их, удаляя избыточный шум, например, HTML-теги, опциональные комментарии и пр. Для этого, например, вызовы к должны по умолчанию подставлять аргументы ограничения выборки, например, добавляя параметры limit (количество строк/записей) и offset (смещение). Если ИИ-клиент запрашивает ресурс без них, сервер принудительно возвращает только первые 100 строк данных и добавляет в ответ подсказку: «Показаны строки 1-100. Для получения следующих строк вызови инструмент с параметром offset: 101». Или вместо передачи сырого массива логов на 50 МБ, MCP-сервер должен принимать от ИИ-клиента точные параметры поиска: временной интервал (timestamp), уровень логирования (ERROR, WARN) или ключевые слова (keyword), чтобы найти нужные данные локально и вернуть модели несколько целевых строк. Если же нейросеть запрашивает полный массив данных, MCP-сервер должен предварительно обработать его и вернуть аналитическую выжимку, например, «Лог-файл содержит 5000 записей о сбоях. Из них 90% связаны с таймаутом базы данных, 8% — ошибки авторизации. Вот примеры трех типичных ошибок: …». Подобное резюме делается с помощью алгоритмов токенизации, поиска по регулярным выражениям и статистического анализа. Наконец, чтобы сэкономить токены, MCP-сервер перед отправкой данных клиенту должен очистить их от лишнего шума и перевести в максимально компактный, но семантически понятный LLM вид в формате JSON или плоский Markdown.
- принцип нулевого доверия. В обычном API сервер доверяет клиенту, если тот аутентифицирован через передачу корректных логина и пароля, ключа или токена. Однако, MCP-сервер не знает, как именно ИИ-клиент будет использовать полученные данные. Поэтому сервер должен валидировать бизнес-логику входящих запросов так, будто они пришли от потенциального злоумышленника. Для этого используется правило минимальных привилегий, например, возможность чтения конкретной папки с документами или определенных таблиц БД. Все секреты (логины и пароли, API-ключи сторонних сервисов и доступы к базам данных и пр.) должны быть изолированы и недоступны для передачи клиенту в виде ресурсов, промптов или вызовов инструментов. Любой сгенерированный моделью код и команды его публикации/развертывания/запуска должны выполняться MCP-сервером исключительно в изолированных песочницах: Docker-контейнерах или виртуальных средах, чтобы не повредить реальную ИТ-инфраструктуру.
Помимо этих особенностей ИИ, при проектировании MCP-сервера следует определить механизм аутентификации клиентов. Здесь тоже не все так однозначно. В частности, официальная спецификация MCP от ноября 2025 года описывает сложную схему авторизации на базе OAuth 2.1 для HTTP-транспорта. Однако, по текущей версии MCP-стандарта это не обязательная функция, а опциональная рекомендация. Например, в собственном MCP-сервере для нужд своей команды, нет смысла связываться с OAuth-аутентификацией, работая со сторонними серверами выдачи токенов и динамической регистрацией клиентов. Можно использовать механизм API-ключей, который позволяет серверу аутентифицировать клиента, не нарушает текущую спецификацию MCP-протокола и поддерживается большинством современных ИИ-клиентов. Именно такое решение я выбрала для собственного MCP-сервера управления OpenAPI-спецификациями, о котором подробно расскажу в следующей статье.
Поработать с MCP-сервером и узнать другие особенности ИИ-систем вы сможете на моих курсах Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:

