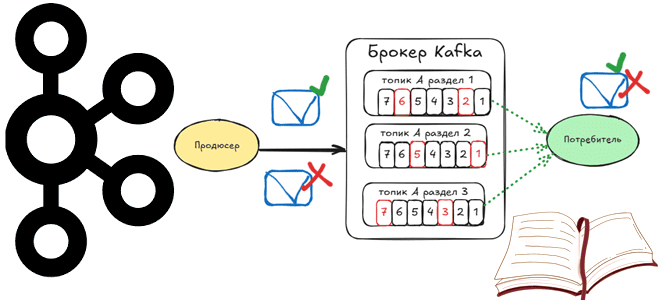
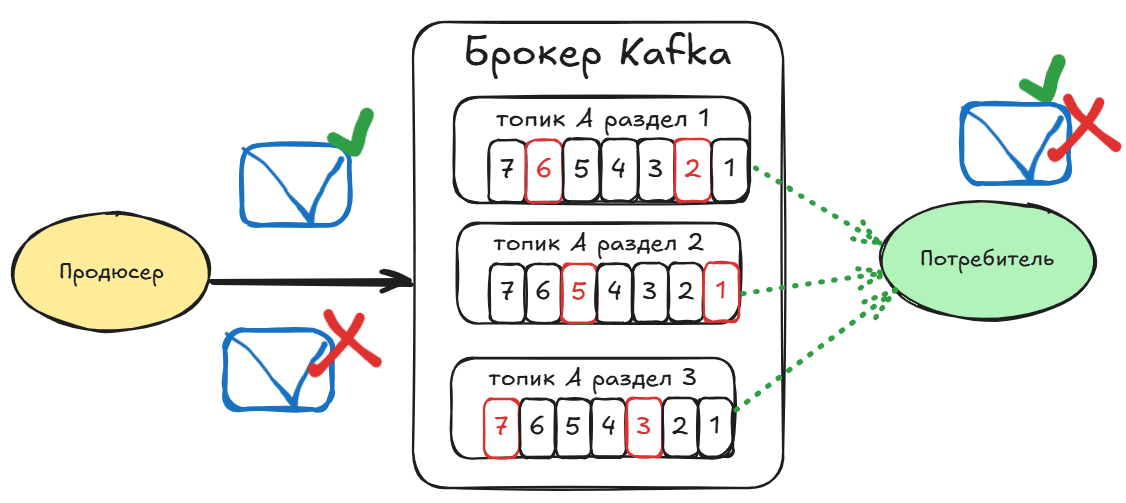
Аномалии грязного чтения незафиксированных транзакций в Apache Kafka: как потребители могут читать данные, которых не видно в топике, почему это происходит и что обеспечивает гарантию exactly once без дублей и потери сообщений.
Транзакционный продюсер
Одним из достоинств Apache Kafka принято считать гарантии доставки сообщений с семантикой exactly once, когда каждое опубликованное сообщение будет обработано приложением-потребителем только один раз, даже при сбоях потоковой системы. Это особенно важно для финансовых операций или бронирований ограниченных ресурсов, где повторы или пропуски недопустимы. Однако, на самом деле, это реализуется не брокером сообщений, а обеспечивается верными настройками продюсеров и потребителей.
На стороне приложения-продюсера, которое публикует данные в Kafka, надо обеспечить идемпотентность и транзакционность отправки данных. А на стороне приложения-потребителя, которое потребляет сообщения и обрабатывает их, следует настроить такой уровень изоляций транзакций, чтобы исключить возможность так называемого «грязного чтения», когда результаты одной незафиксированной транзакции становятся видны другим. Да, несмотря на то, что Apache Kafka – это не БД, понятие транзакции есть и здесь. Чтобы продемонстрировать, как это работает, я написала 2 небольших Python-скрипта:
- идемпотентный транзакционный продюсер отправляет сообщения в топик Kafka, случайным образом фиксируя или отменяя некоторые транзакции публикации данных. При этом сгенерированные для отправки данные сперва сохраняются в текстовый CSV-файл, чтобы сравнить разницу между отправленными и потребленными сообщениями;
- потребитель с уровнем изоляции транзакций read_uncommited видит и потребляет все сообщения из топика, в т.ч. те, что еще не были зафиксированы. Потребленные сообщения группируются по отправившим их пользователям и агрегированный результат сохраняется в CSV-файл.
Код продюсера:
#импорт библиотек
from kafka import KafkaProducer
from dataclasses import dataclass, asdict
import random
import asyncio
import json
from datetime import datetime
from faker import Faker
import csv
# Название Kafka топика, в который будем публиковать сообщения
topic = "InputsTopic"
# Адрес Kafka брокера
kafka_url = 'localhost:29092'
# Используем dataclass для структуры сообщения
@dataclass
class RequestData:
moment: str # Время создания сообщения в формате строки
name: str # Имя отправителя сообщения
# Количество сообщений для генерации
messages_quantity = 15
# Количество уникальных имён для генерации случайных сообщений
uniq_names_quantity = 5
# Инициализация Faker с локализацией для генерации имён
fake = Faker("ru_RU")
# Создание списка уникальных имён
limited_names = [fake.name() for _ in range(uniq_names_quantity)]
# Функция генерации случайного сообщения с текущим временем и случайным именем
def generate_fake_data() -> RequestData:
now = datetime.now()
moment = now.strftime("%m/%d/%Y %H:%M:%S") # Форматируем время в строку
name = random.choice(limited_names) # Выбираем случайное имя из списка
return RequestData(moment=moment, name=name)
# Создание KafkaProducer с конфигурацией для транзакций и идемпотентности
producer = KafkaProducer(
bootstrap_servers=kafka_url, # Адрес Kafka брокера
transactional_id='transactional-producer-1', # Уникальный ID для транзакционного продюсера
enable_idempotence=True, # Включаем идемпотентность для предотвращения дубликатов
acks='all', # Ожидаем подтверждения от всех реплик
max_in_flight_requests_per_connection=1, # Для сохранения порядка сообщений
retries=5, # Количество повторных попыток при ошибках
value_serializer=lambda v: json.dumps(v, ensure_ascii=False).encode('utf-8') # Сериализация сообщений в JSON
)
producer.init_transactions() # Инициализация транзакционного режима
# Функция записи сообщения в CSV (добавляет в конец файла)
def write_to_csv(message: RequestData, filename="to_send.csv"):
# Открываем CSV файл в режиме добавления, с UTF-8 и корректным переносом строк
with open(filename, mode='a', encoding='utf-8', newline='') as file:
writer = csv.DictWriter(file, fieldnames=["moment", "name"])
# Если файл пустой, пишем заголовок
file.seek(0, 2) # Переходим в конец файла
if file.tell() == 0:
writer.writeheader()
# Записываем данные сообщения как словарь
writer.writerow(asdict(message))
# Асинхронная функция отправки сообщения транзакционно с записью в CSV
async def transactional_producer(message: RequestData):
try:
write_to_csv(message) # Сначала сохраняем сообщение в CSV
producer.begin_transaction() # Начинаем Kafka транзакцию
producer.send(topic, asdict(message)) # Отправляем сериализованные данные
producer.flush() # Ждём фактической отправки
# Случайный выбор — коммит или откат транзакции
if random.choice([True, False]):
producer.commit_transaction()
print(f"Публикация зафиксирована: {message}")
else:
producer.abort_transaction()
print(f"Публикация отменена: {message}")
except Exception as e:
print(f"Ошибка транзакции публикации: {e}")
producer.abort_transaction() # При ошибке откатываем транзакцию
# Асинхронная функция последовательной генерации и отправки сообщений с паузой 0.5 с
async def produce_messages():
for _ in range(messages_quantity):
data = generate_fake_data() # Генерируем сообщение
await transactional_producer(data) # Отправляем его транзакционно
await asyncio.sleep(0.5) # Задержка для имитации нагрузки
# Точка входа — запуск асинхронного цикла отправки сообщений
if __name__ == "__main__":
try:
asyncio.run(produce_messages())
except KeyboardInterrupt:
print("Программа прервана пользователем") # Корректное завершение при прерывании
Этот Python-код реализует асинхронного Kafka-продюсера, который генерирует с помощью библиотеки faker и транзакционно отправляет JSON-сообщения от фейковых клиентов, сохраняя перед отправкой каждое сообщение в CSV-файл to_send.
Как видно из кода, реализация идемпотентности и транзакционности отправки полностью на стороне продюсера, задается настройками его конфигурации в параметрах transactional_id, enable_idempotence, acks, max_in_flight_requests_per_connection и retries, а также с помощью метода init_transactions() класса KafkaProducer в библиотеке kafka-python. Транзакции позволяют группировать сообщения, чтобы зафиксировать их (commit) или отменить (abort) все вместе. Благодаря этому даже при сбоях продюсер может повторно отправлять все сообщения без потерь, т.к. транзакция гарантирует атомарность отправки: видимы будут все опубликованные в транзакции сообщения, или ни одно из них. Это реализуется благодаря транзакционным меткам сообщения, от которых зависит видимость сообщений для потребителей. Незафиксированные сообщения не должны быть видимы потребителям, они логически скрываются или игнорируются. А идемпотентность обеспечит отсутствие дублей из-за повторной отправки одного и того же сообщения.
Для наглядности в выводе терминала посмотрим отмененные, т.е. не зафиксированные транзакции публикации данных
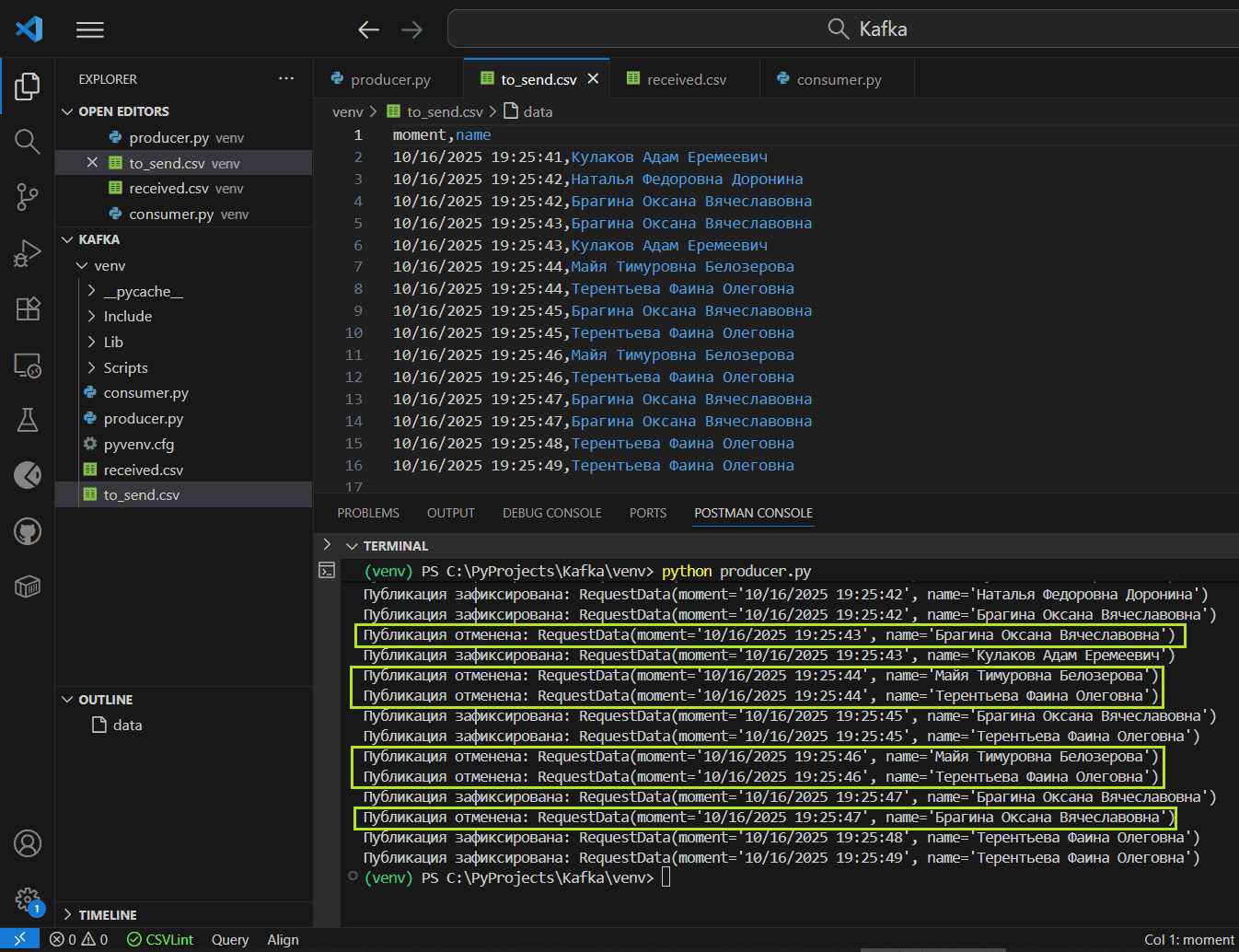
При этом в топике Kafka визуально видны только зафиксированные сообщения. Их всего 9, а не 15, как было опубликовано, поскольку 6 из 15 транзакций были отменены, не зафиксированы. Также интересно посмотреть на изменение порядка смещений (offset) в разделах топика Kafka, которые постоянно инкрементируются для каждого следующего, даже незафиксированного сообщения. Смещение увеличивается линейно и непрерывно, даже если сообщение относится к отмененной транзакции.
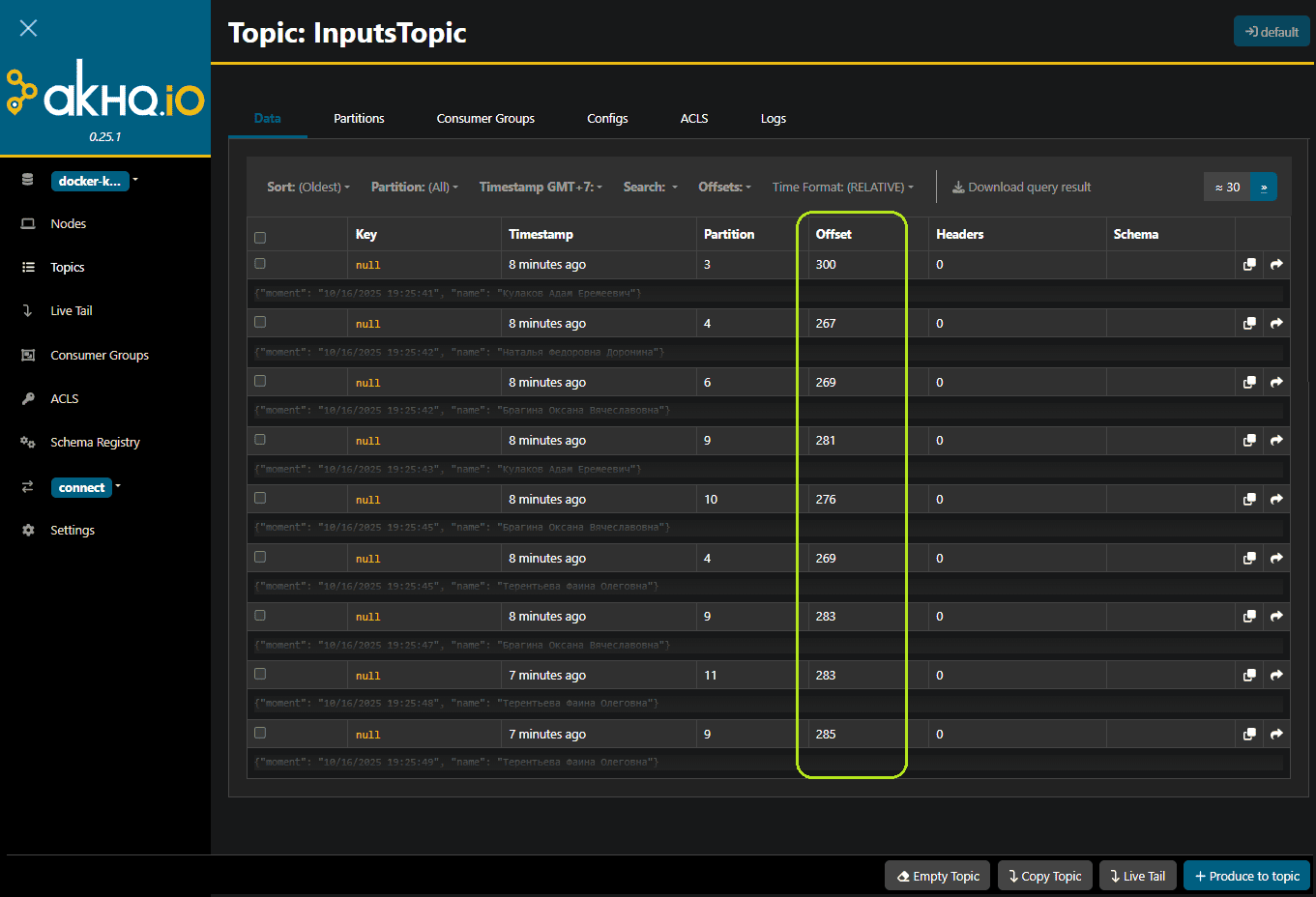
Параллельно с публикацией запущен скрипт потребления «грязных» данных, который рассмотрим далее.
Грязное чтение из Kafka: нарушение изоляции потребления данных
По умолчанию у потребителя Kafka уровень изоляции транзакций isolation.level установлен в значение read_uncommitted. Это означает, что вызов poll() будет возвращать все сообщения, даже те, которые не зафиксированы. Сообщения всегда возвращаются в порядке смещения. При уровне изоляции read_committed вызов poll() возвращает только сообщения до последнего стабильного (LSO, Last Stable Offset), которое меньше смещения первой открытой транзакции. Любые сообщения после тех, которые принадлежат к текущим транзакциям, будут задерживаться их до завершения. Поэтому потребители с уровнем изоляции read_committed не смогут читать незафиксированные сообщения, т.е. до верхней границы при наличии текущих транзакций.
Чтобы продемонстрировать аномалию грязного чтения (dirty read) с поведением потребителей по умолчанию read_uncommitted, явно зададим это в настройках потребителя. Приложение-потребитель подписывается на топик Kafka и потребляет из него все сообщения, даже те, которые не зафиксированы продюсером. В CSV-файл записывается количество сообщений от каждого клиента, по его имени. Python-код этого потребителя:
# Импорт библиотек
import csv # Для работы с CSV-файлами
import json # Для парсинга JSON-строк
import asyncio # Для асинхронного программирования
from collections import defaultdict # Для удобного подсчёта количества
from aiokafka import AIOKafkaConsumer # Асинхронный Kafka потребитель
# Название топика Kafka для подписки
topic = "InputsTopic"
# Адрес Kafka брокера
kafka_url = 'localhost:29092'
# Словарь для подсчёта количества сообщений по имени отправителя
usage_counts = defaultdict(int)
# Имя файла для сохранения подсчётов
csv_file = 'received.csv'
# Функция записи подсчётов в CSV-файл (перезаписывает файл каждый раз)
def write_counts_to_csv(counts):
with open(csv_file, 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
writer.writerow(['name', 'count']) # Записываем заголовки колонок
for name, count in counts.items():
writer.writerow([name, count]) # Записываем имя и количество сообщений
# Асинхронная функция для потребления сообщений из Kafka
async def consume():
consumer = AIOKafkaConsumer(
topic,
bootstrap_servers=kafka_url, # Адрес Kafka брокера
group_id="my-group", # Идентификатор группы потребителей
auto_offset_reset="earliest", # Считать сообщения сначала, если смещение неизвестно
isolation_level="read_uncommitted" # Позволяет "грязное" чтение незафиксированных транзакций
)
await consumer.start() # Запускаем подключение к брокеру
try:
# Асинхронно перебираем полученные сообщения
async for msg in consumer:
data = json.loads(msg.value.decode('utf-8')) # Десериализация JSON
name = data.get('name', 'unknown') # Получаем имя отправителя
usage_counts[name] += 1 # Увеличиваем счётчик
print(f"Получено сообщение от {name}, всего: {usage_counts[name]}")
write_counts_to_csv(usage_counts) # Записываем в CSV
finally:
await consumer.stop() # Корректно завершаем работу потребителя
# Главная асинхронная функция запуска процесса потребления
async def main():
task = asyncio.create_task(consume()) # Запускаем задачу потребления в фоне
try:
await task # Ждём завершения задачи
except asyncio.CancelledError:
print("Потребление прервано") # Обработка отмены задачи
# Основная точка входа программы
if __name__ == "__main__":
try:
asyncio.run(main()) # Запускаем асинхронный цикл событий
except KeyboardInterrupt:
print("Программа прекращена пользователем") # Обработка прерывания
Поскольку уровень транзакций read_uncommitted позволяет читать даже незафиксированные сообщения, в выходном файле потребителя видны все данные.
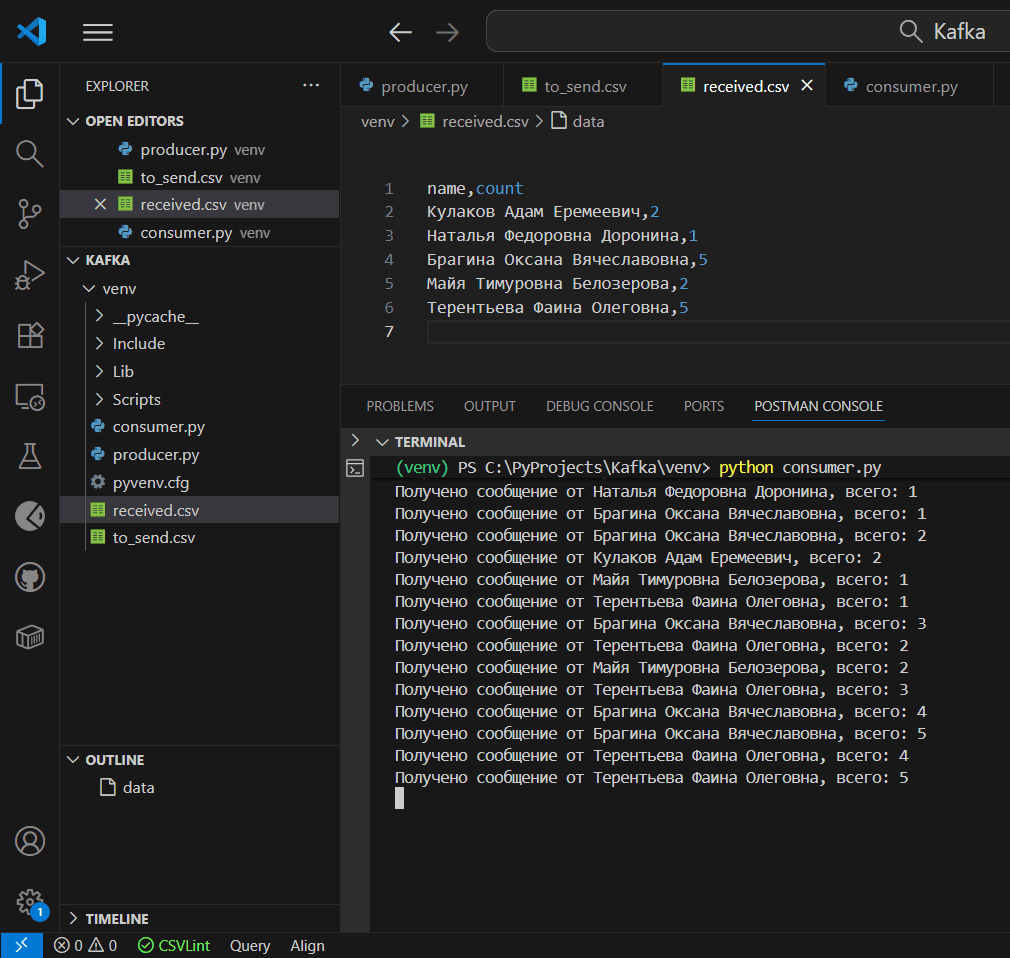
И тут возникает логичный вопрос: почему, если продюсер отменяет публикацию, т.е. не фиксирует транзакцию, и сообщение не видно в топике Kafka, потребитель с уровнем изоляции read_uncommited все равно потребляет его? Такое аномальное поведение возникает по следующим причинам из-за асинхронного характера публикации данных. Транзакции в Kafka работают асинхронно. Поэтому, даже если продюсер вызвал метод abort_transaction(), сообщение, опубликованное в рамках этой транзакции в топик, физически было уже отправлено брокеру и попало в топик. При этом оно остается незафиксированным, и потенциально может быть прочитано потребителями с уровнем изоляции read_uncommitted, что и демонстрирует вышеприведенный пример.
Со временем незафиксированные сообщения в топике скрываются или удаляются, но в реальности из-за сбоев Kafka они могут сохраняться до момента срабатывания политики очистки топика, порог которой задан в параметре retention.time или retention.size. Задержка удаления незафиксированных сообщений может привести к ошибкам потребления данных даже у потребителей с уровнем изоляции read_committed: задержкам обработки данных, пропускам смещений и исключению OffsetOutOfRangeException, когда потребитель пытается читать сообщение со смещением, которое уже удалено с брокера из-за политики очистки.
Поэтому возникает второй вопрос: если уровень изоляции read_uncommitted чреват ошибками, почему именно он используется в потребителях по умолчанию? Как говорится, так исторически сложилось по следующим причинам:
- высокая производительность: не нужна дополнительная фильтрация и контроль состояния транзакций, потоковая передача и обработка данных происходит максимально быстро и с минимальными накладными расходами;
- обратная совместимость: транзакции впервые появились в Kafka 0.11.0, до этого все сообщения публиковались моментально и были сразу доступны. Чтобы новый механизм не ломал ранее существующие системы, по умолчанию разработчики оставили уровень изоляции read_uncommitted.
- распространенность некритичных сценариев: во многих случаях Kafka используется для потоковой передачи промежуточных событий и логов, где просто нужна высокая скорость без гарантии exactly once, а дубли и потери данных не критичны.
Таким образом, чтобы брокер сообщений был надежен, «как швейцарские часы», помимо использования его внутренних механизмов отказоустойчивости, следует тщательно настраивать и другие звенья потоковой системы, т.е. приложений-продюсеров и потребителей, ведь именно они обеспечивают ту самую гарантию exactly once.
Подробнее познакомиться с Apache Kafka, а также с другими технологиями проектирования архитектуры и интеграции информационных систем вы сможете на моих курсах Школы прикладного бизнес-анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации аналитиков и дата-инженеров в Москве:
- Apache Kafka для дата-инженера и системного аналитика
- Основы архитектуры и интеграции информационных систем