
Чем классический ML отличается от генеративного ИИ, как модель машинного обучения делает расчеты: практическая демонстрация бинарной классификации с вероятностной оценкой, от подготовки данных до интерпретации результатов.
Виды и алгоритмы ИИ
Искусственный интеллект (ИИ) – это не только генеративные нейросети, которые создают новый контент на основе имеющихся знаний о распределении похожих данных, но классическое машинное обучение, основанное на матстатистике и теории вероятностей. В отличии от генеративного ИИ (GenAI, Generative Artificial Intelligence), классический ML (Machine Learning) использует меньше данных и потребляет намного меньше ресурсов. При этом классический ML обеспечивает очень высокое качество, т.е. точность и полноту, результатов на структурированных (табличных) данных. Поэтому нецелесообразно использовать дорогую LLM (большую языковую модель, Large Language Model), например, для оценки вероятности того, что заемщик вернет кредит вовремя, расчета ожидаемой выручки или сегментации пользователей. Все 3 перечисленные задачи отлично решаются базовыми алгоритмами классического машинного обучения: классификация, регрессия и кластеризация.
Первые 2 алгоритма относятся к обучению с учителем, когда конечный результат известен, к примеру, благонадежный клиент или потенциальный банкрот, и ML-модель должна отнести клиента к тому или иному классу в задаче классификации, или спрогнозировать LTV клиента в задаче регресии. Кластеризация означает обучение без учителя, когда итоговый результат неизвестен, и цель ML-модели – выявить кластеры, т.е. схожие группы случаев во входной выборке, например, активные покупатели и пассивные посетители сайта, на основе просмотренных страниц, длительности сессии и прочих событий пользовательского поведения. Для этого используют такие математические методы, как линейная и логистическая регрессия, деревья решений, метод опорных векторов, градиентный бустинг и другие подходы к получению результата на основе выявления закономерностей в статистическом распределении данных.
Чтобы показать, как это работает, рассмотрим типовую задачу бинарной классификации на примере входящей заявки клиента на подбор спецтехники от разных поставщиков.
Постановка задачи
Клиенты (юридические и физические лица) отправляют в компанию-посредник розничную заявку подобрать специальную технику (дорожную, строительную и т.д.). Компания ищет поставщика и заключает 2 договора: один – с клиентом, другой – с поставщиком, получая выгоду на разнице цен розничных и оптовых продаж. Входящие платежи поступают на счет компании по договору с клиентом, исходящие платежи означают списание денег со счета компании при их переводе поставщику.
Бинарная классификация значит, что в прогнозе модель должна отнести заявку к одному из 2-х возможных классов: конвертируется она в договор или не конвертируется. Однако, с точки зрения бизнеса, более интересно и полезно не просто отнесение входящей заявки к одному из двух классов (конверсия/не конверсия), а то, с какой вероятностью поступившая заявка конвертируется в продажу. Например, если вероятность конверсии высока, имеет смысл оперативно поручить обработку этой заявки опытному менеджеру по продажам, чтобы быстрее закрыть сделку. И наоборот, понизить приоритет обработки при низкой вероятности конверсии.
Подготовка к обучению ML-модели
Поскольку для прогнозирования ML-модель сперва надо обучить, нужны исторические данные о том, какие клиенты подавали заявки и на какую технику, по каким заявкам заключены договора, какие менеджеры вели эти заявки и другая статистическая информация. Эти структурированные данные можно получить из CRM-системы или Excel-таблиц операционной отчетности. Для этого примера я сгенерировала фейковые данные и структурировала их в наборе CSV-файлов согласно следующей схеме.
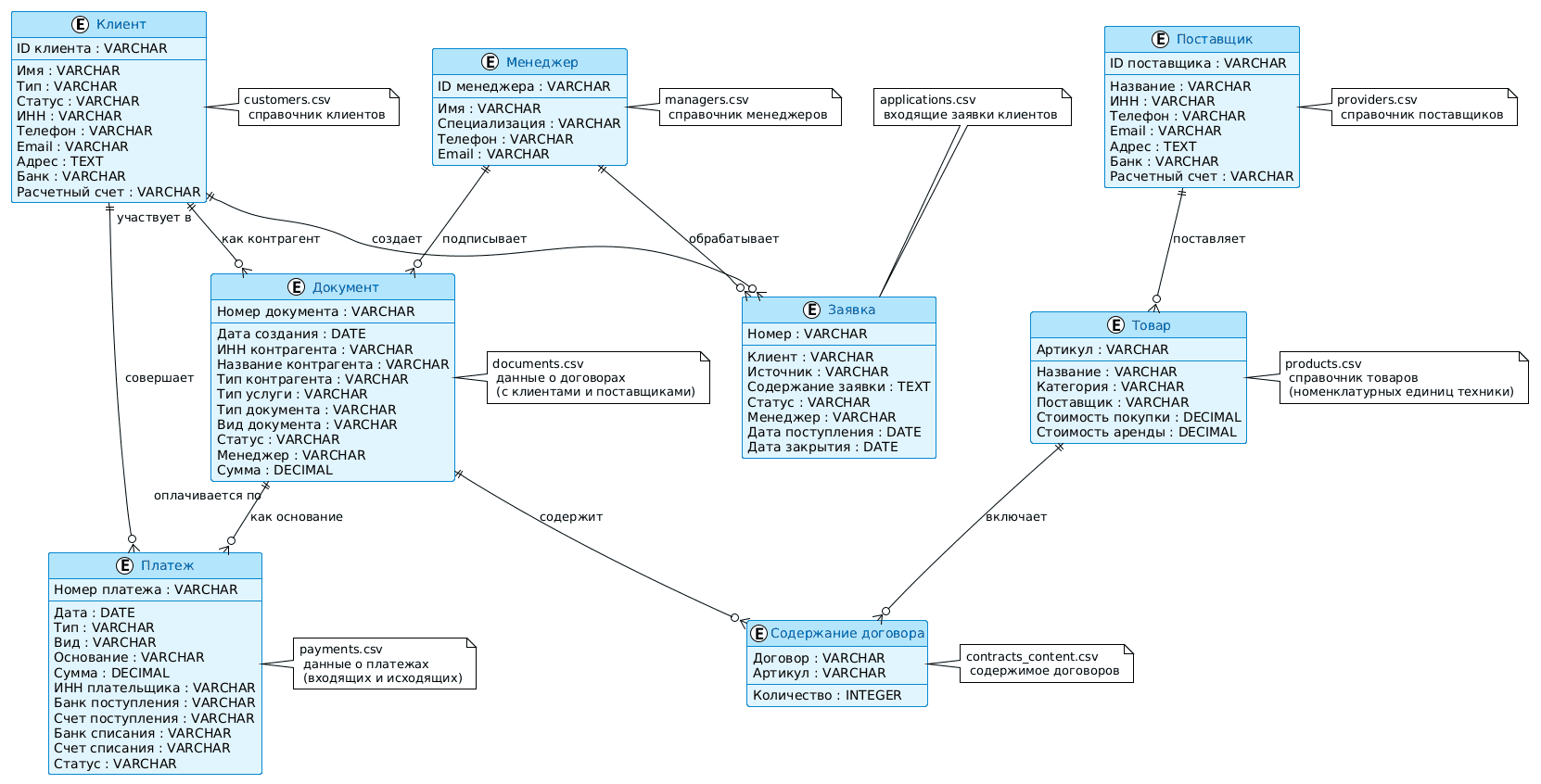
Разумеется, чем больше данных, тем более точной будет ML-модель. Однако, обработка слишком больших наборов данных потребует больше времени и ресурсов. Для этой задачи у меня создано 22 тысячи записей о заявках, около 7500 клиентов и 10000 документов, из которых не все являются договорами: есть и КП (коммерческие предложения), простые информационные письма, дополнительные соглашения, акты и пр. Это означает, что на этапе подготовки данных к обучению модели их нужно предварительно отфильтровать по виду документа, т.к. нас интересуют именно договоры. Помимо этого, надо выделить признаки (features), на основе которых модель выдает прогноз, например, какая имено услуга запрошена в заявке (аренда, покупка или ремонт техники), какая именно техника, какова сумма услуги и т.д.
Иногда помимо прямых признаков, которые есть в исходных данных, нужны производные (косвенные), например, сколько времени прошло до фактического взятия заявки в работу, были ли уже заключенные договоры с этим клиентом и т.д. Этот этап называется инженерией признаков (feature enginering). Он очень важен, т.к. во многом определяет качество результата и стоимость его достижения. При его выполнении инженеру нужны не только навыки оптимизации обработки данных, например, как быстро и недорого отфильтровать таблицу из нескольких млн строк, но и понимание бизнеса: откуда поступают заявки, как именно они приоритизируются, маршрутизируются по менеджерам и т.д. В частности, для рассматриваемого примера может быть важным момент поступления заявки: рабочая смена или выходные, конверсия завок в догворы по менеджеру, по клиенту и т.д.
При отборе этих фичей, т.е. признаков для обучения ML-модели, важно исключить из те, которые слишком близки друг другу по смыслу и методам расчета, например, общее время обработки заявки и время ее ожидания в очереди. Такая линейная зависимость двух переменных друг от друга называется мультиколлинеарностью. Она негативно влияет на обучение модели, не позволяя точно оценить вклад каждого признака в результат. Кроме того, обработка бОльшего количества признаков увеличивает размерность обучающих векторов (матриц) и требует больше ресурсов для вычислений.
Будучи набором вычислительных алгоритмов, ML-модель оперирует численными данными. Поэтому на этапе подготовке к обучению нужно оцифровать все признаки, т.е. выполнить кодирование категориальных (нечисловых) переменных. В моем примере это источники и статусы заявок, документов, специализации менеджеров и т.д.
Кроме такой очистки и подготовки исходных данных для задач классификации особенно важно обеспечить сбалансированный набор данных для обучения модели. Это означает примерно одинаковое количество результирующих случаев для каждого класса. В моей демонстрации это означает, что количество заявок, конвертированных в договор, должно быть равно количеству не конвертированных. Иначе ML-модель при обучении столкнется с дисбалансом классов и не сможет делать корректные прогнозы. Для борьбы с таким неравномерным распределением исходных данных их специально обрабатывают, увеличивая выборку миноритарного (меньшего) класса с помощью подобных записей, сгенерированных синтетически, или уменьшая выборку мажоритарного (большего) класса. Для этого во многих популярных ML-библиотеках есть соответствующие алгоритмы, например, SMOTE в imblearn, что используется в моем скрипте.
Обучение и проверка качества
После полной подготовки данных для обучения ML-модели, нужно сформировать обучающую выборку. Обычно ее размер составляет 75% случаев из всего набора данных. Оставшиеся 25% случаев – тестовая выборка, нужная для проверки качества модели, т.е. валидации настроек ее алгоритма: выбранного метода, его параметров и пр.
Выбор метода зависит от решаемой задачи (классификация, регрессия или кластеризация), а также от распределения и структуры данных: объема выборки и закона случайного распределения значений в ней, частоте пропусков/выбросов/шумов, количества обучающих признаков и их характера (числовые/категориальные). Также важна быстрота и алгоритмическая сложность метода, его интерпретируемость и потребление ресурсов. Наиболее популярные методы для классического ML представлены в таблице.
| Метод | Задача | Особенности данных (объём, тип, пропуски, выбросы, распределение) | Скорость расчётов | Интерпретируемость | Потребление ресурсов | Когда выбирать |
| Линейная регрессия | Регрессия | · Объём: от 10 до 10⁶+ объектов
· Тип: только числовые Пропуски: не допустимы · Выбросы: очень чувствительна, сильно искажают коэффициенты · Распределение: критична к мультиколлинеарности |
Очень быстро | Высокая (коэффициенты, доверительные интервалы, p-value) | Низкое | • Прозрачная оценка влияния признаков • Эконометрика и причинный анализ • Базовый прогноз на очищенных данных • Когда скорость важнее сложной нелинейности |
| Логистическая регрессия | Классификация (бинарная / мультикласс) | · Объём: устойчива от 100 до 1 млн+
· Тип: числовые + категориальные (после кодирования) · Пропуски: не допустимы · Выбросы: умеренно чувствительна · Распределение: важна линейная разделимость в пространстве вероятностей, признаки желательно масштабировать |
Быстро | Высокая (веса, Odds Ratio, калиброванные вероятности) | Низкое | • Риск-скоринг (кредитный, медицинский) • Когда нужны вероятности класса • Бинарная/мультиклассовая классификация с интерпретацией • Базовый бейзлайн для классификации |
| Дерево решений (CART, ID3, C4.5) | Классификация, Регрессия | · Объём: любой (от малого до большого)
· Тип: любые (числовые и категориальные без кодирования) · Пропуски: допускает или требует или заполнения · Выбросы: умеренно чувствительны; без регуляризации сильно переобучается · Распределение: не важно (непараметрический метод) |
Быстро | Очень высокая (визуальные правила If-Then, пути решений) | Низкое–Среднее | • Быстрое прототипирование • Когда нужны понятные правила принятия решений • Смешанные типы признаков без масштабирования • Разведочный анализ важности признаков |
| Случайный лес (Random Forest) | Классификация, Регрессия | · Объём: 10³–10⁶+ (отлично масштабируется)
· Тип: смешанные (числовые и категориальные) · Пропуски: некоторые реализации допускают · Выбросы: высокая устойчивость (усреднение по деревьям) · Распределение: не важно |
Быстро (параллелизуется) | Средняя (важность признаков, но сам ансамбль — «чёрный ящик») | Среднее–Высокое (память под T деревьев) | • Высокая точность без тонкой настройки • Устойчивость к шуму и выбросам • Когда важна оценка важности признаков • Большие табличные данные |
| Градиентный бустинг (XGBoost / LightGBM / CatBoost) | Классификация, Регрессия | · Объём: любой (оптимизирован для больших выборок)
· Тип: табличные данные; CatBoost и LightGBM нативно работают с категориальными данными · Пропуски: XGBoost и LightGBM обрабатывают пропуски · Выбросы: чувствителен без регуляризации · Распределение: не важно |
Средне–Быстро (зависит от глубины и итераций) | Средняя–Низкая (требует SHAP/LIME для детального объяснения) | Среднее–Высокое (оптимизировано под CPU, эффективная память) | • Сложные нелинейные зависимости • Скоринг и прогнозирование с десятками признаков |
| k‑NN (k ближайших соседей) | Классификация, Регрессия, Кластеризация | · Объём: малые и средние выборки (проклятие размерности)
· Тип: числовые (категориальные нужно кодировать) · Пропуски: можно задать метрику, игнорирующую пропуски · Выбросы: очень чувствителен к выбросам · Распределение: не важно, но обязательна нормализация/стандартизация всех признаков |
Медленно на больших выборках (предсказание O
×m)) |
Средняя (объяснение через ближайшие аналоги) | Высокое (хранит всю обучающую выборку) | • Локальные зависимости без явной модели • Маломерные данные (2–10 признаков) • Быстрый бейзлайн для прототипа • Рекомендательные системы (user-based) |
| SVM (опорные векторы) | Классификация, Регрессия (SVR) | · Объём: малые и средние (<50 000 объектов)
· Тип: числовые (категориальные нежелательны) · Пропуски: не допустимы · Выбросы: нужно смягчать · Распределение: не важно, обязательна стандартизация |
Медленно на больших выборках (O(n²)–O(n³)) | Низкая (веса в ядровом пространстве не интерпретируемы) | Высокое (опорные векторы + матрица Грама) | • Высокоразмерные данные (тексты, гены) • Малые выборки (100–10 000) • Сложные нелинейные границы (RBF-ядро) • Классификация с чёткими разделяющими гиперплоскостями |
| k‑Means | Кластеризация | · Объём: большой (хорошо масштабируется)
· Тип: только числовые (евклидово расстояние) · Пропуски: не допустимы · Выбросы: сильно смещают центроиды · Распределение: предполагает сферические кластеры примерно одинакового размера и плотности |
Очень быстро (O(n×k×t)) | Средняя (координаты центроидов) | Низкое | • Быстрая сегментация клиентов / товаров • Сжатие признаков (kMeans для квантования) • Базовый анализ структуры данных • Когда число кластеров известно или подбирается по локтю |
| DBSCAN | Кластеризация, поиск выбросов | · Объём: средний–большой (с индексами)
· Тип: числовые (чувствителен к метрике) · Пропуски: не допустимы |
Средняя (O(n log n) с индексами) | Средняя (группы по локальной плотности) | Низкое–Среднее | • Поиск аномалий и выбросов • Кластеры произвольной формы (не шары) • Зашумленные данные с неоднородной плотностью • Когда число кластеров неизвестно |
| Наивный Байес (Gaussian / Multinomial / Bernoulli) | Классификация | · Объём: любой (отлично работает с большим числом признаков)
· Тип: Gaussian → числовые, Multinomial → частоты (тексты) · Пропуски: игнорируются · Выбросы: мало влияют · Распределение: предполагает условную независимость признаков |
Очень быстро | Высокая (априорные и условные вероятности) | Низкое | • Спам-фильтрация, классификация текстов • Медицинская диагностика (независимые симптомы) • Быстрый бейзлайн с вероятностным выводом • Многомерные данные с независимыми признаками |
| PCA (метод главных компонент) | Снижение размерности (без учителя) | · Объём: любой
· Тип: только числовые · Пропуски: не допустимы · Выбросы: очень сильно искажают главные компоненты · Распределение: работает лучше при гауссовых признаках, обязательна стандартизация |
Средняя (зависит от SVD) | Средняя (нагрузки признаков, дисперсия компонент) | Средняя | • Визуализация многомерных данных (2–3 компоненты) • Уменьшение шума и мультиколлинеарности • Подготовка признаков для других методов • Сжатие данных с минимальной потерей информации |
Для моей задачи бинарной классификации новой заявки с вычислением вероятности ее конверсии в договор подходит градиентный бустинг. По сравнению со случайным лесом (ранее я пробовала алгоритм RandomForest) на таком небольшом объеме структурированных табличных XGBoost лучше выявляет нелинейные зависимости и дает повышенную точность с меньшим числом деревьев. А чтобы результаты прогнозирования были понятны, вклад каждого признака интерпретируем с помощью библиотеки SHAP.
Чтобы оценить результаты обучения на тестовой выборке, надо смотреть метрики качества, которые тоже зависят от решаемой задачи. Например, для задачи классификации это AUC-ROC, Accuracy, Precision, Recall. Что означает каждая метрика и как ее рассчитывать, приведено в таблице.
| Метрика | Формула | Что показывает | Бизнес-смысл | Когда использовать | Ограничения и недостатки метрики |
| Accuracy | (TP + TN) / (TP + TN + FP + FN) | Доля всех правильных ответов (и договоры, и отказы) | Насколько модель в целом права, предсказывая исход заявки | Только при сбалансированных классах (50/50) | При редкой конверсии (например, 5%) можно получить 95%, предсказывая отказ на все заявки |
| Balanced Accuracy | (TPR + TNR) / 2 | Средняя точность по каждому классу отдельно | Насколько модель хорошо предсказывает и договоры, и отказы с учётом их разного количества | При дисбалансе классов, когда оба класса одинаково важны | Не фокусируется на редком классе (заявке, конвертирующейся в договор); модель с TPR=0 и TNR=100 даст 50%точности, как подбрасывание монетки |
| Precision (точность) | TP / (TP + FP) | Из предсказанных договоров — сколько реально состоялось | Когда модель предсказывает договор, в каком проценте случаев она права | Дорого ошибиться (ложное срабатывание): ограниченные ресурсы на
обработку заявок |
Не показывает, сколько договоров упущено (можно найти 1 договор с Precision=100%, но потерять 99) |
| Recall (полнота, sensitivity) | TP / (TP + FN) | Из всех реальных договоров — сколько модель нашла | Какую долю потенциальных клиентов не упустили? | Дорого потерять клиента: каждый договор приносит прибыль | Не показывает долю ложных срабатываний |
| F1‑score | 2 × (Precision × Recall) / (Precision + Recall) | Гармоническое среднее между точностью и полнотой | Баланс между тем, чтобы не ошибаться и не упускать клиентов | Когда нужен единый показатель, учитывающий и Precision, и Recall | При сильном дисбалансе может быть неинформативна |
| AUC‑ROC (Area Under ROC‑curve) | Площадь под кривой TPR (Recall) от FPR: чем ближе к 1, тем лучше | Способность модели отличать класс конверсионной заявки от отказной (без договора) | Насколько хорошо модель ранжирует заявки: договоры выше, отказы ниже | Когда важна ранжирующая способность, а не фиксированный порог | Не чувствительна к абсолютным значениям вероятностей |
| Average Precision (AP) | Площадь под кривой Precision‑Recall | Средняя точность по всем уровням полноты | Как суммарно хорошо модель находит договоры без ложных срабатываний | При сильном дисбалансе (редкий класс договора) — лучше чем AUC‑ROC | Менее интуитивна, чем AUC‑ROC; требует понимания PR‑кривой |
Как выглядят графики некоторых из рассмотренных метрик качества, показано на следующих рисунках. Высокое значение AUC‑ROC (более 90%) говорит о приемлемом качестве модели, что подтверждается и другими метриками.
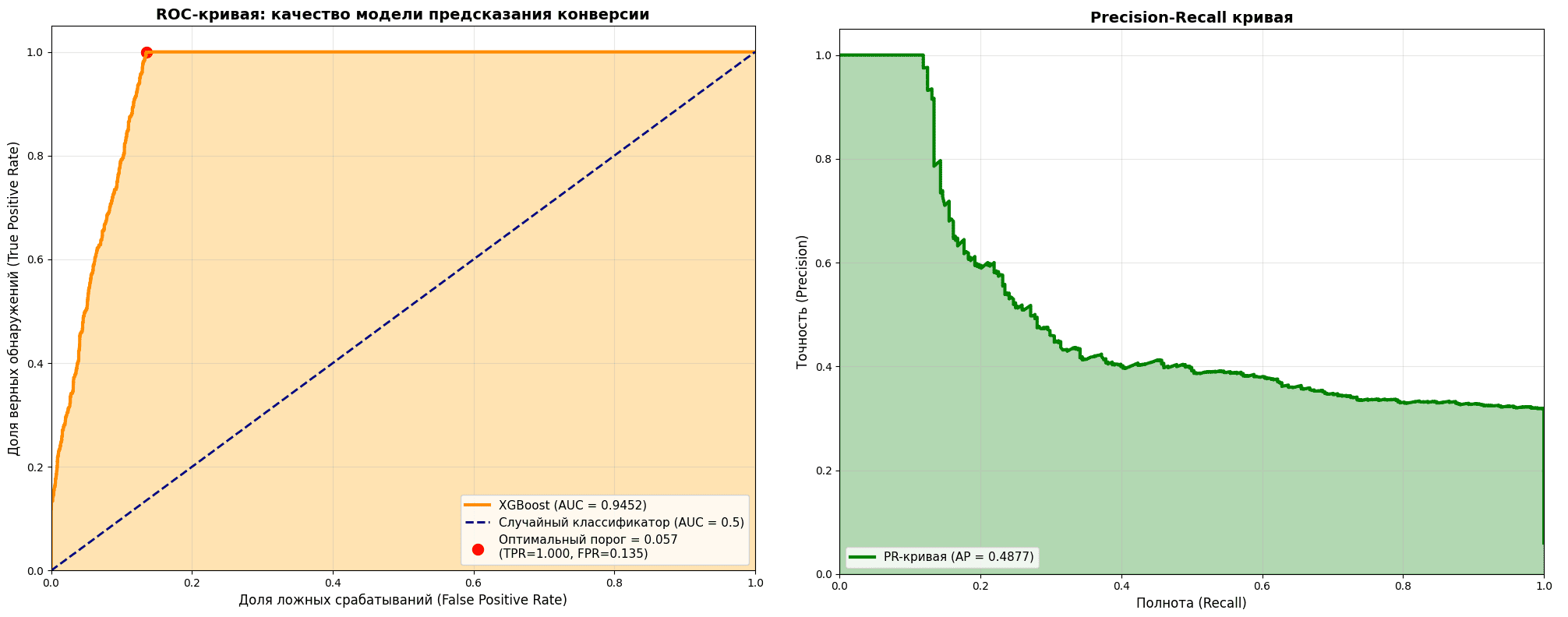
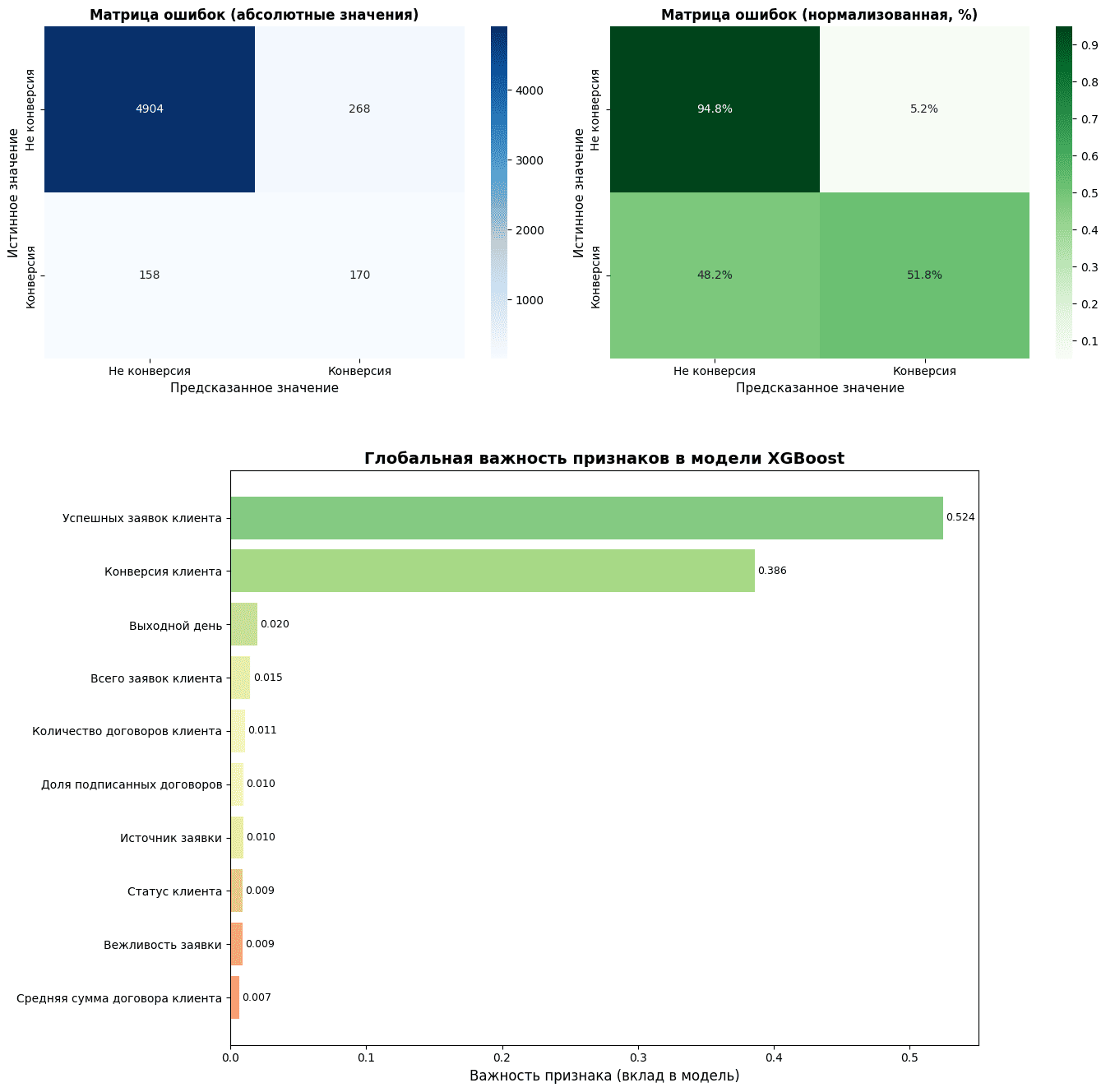
Сам Python-скрипт, как обычно, приведен в моем Gihub-репозитории: вы можете запустить его в Gooogle Colab или локальной IDE, предварительно подготовив исходные данные в виде CSV-файлов согласно вышеуказанной ER-схеме данных.
После обучения модели наступает самый интересный и полезный этап ее жизненного цикла — развертывание и эксплуатация. Например, ниже представлен результат прогнозирования по новой входящей заявке.
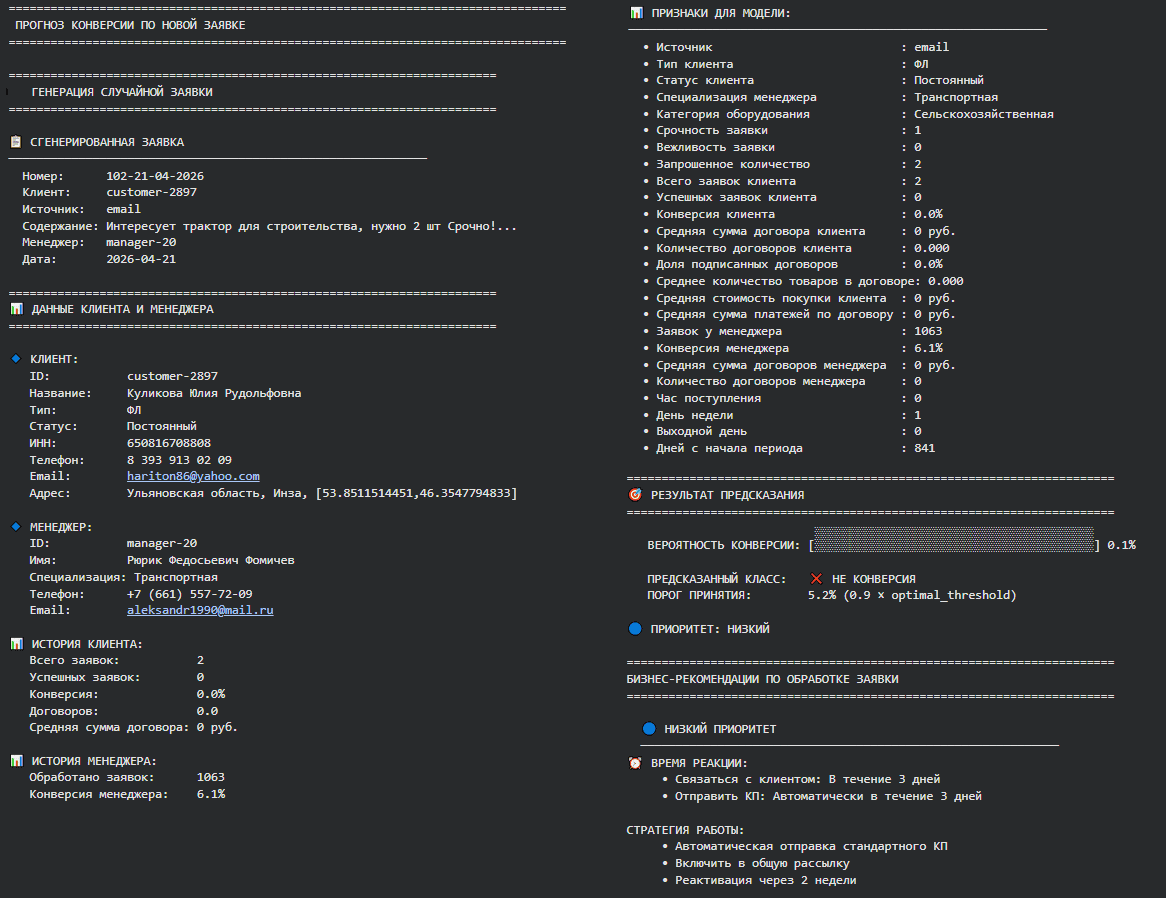
Об архитектуре и инфраструктуре производственного использования ML-систем я расскажу в следующий раз.
Узнайте больше про практическое применение классического и генеративного ИИ на моих курсах Школы анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации в Москве:

