От чего зависит производительность потокового конвейера на RabbitMQ и как ее увеличить: масштабирование с балансировкой нагрузки и предел предварительной выборки канала.
Масштабирование потокового конвейера
С ростом нагрузки, т.е. количества обращений и объема данных, приходится задумываться о масштабировании информационной системы. Когда речь идет о классической трехзвенной или двухзвенной архитектуре, масштабирование обычно сводится к увеличению количества экземпляров серверного приложения и сервера базы данных с балансировкой нагрузки и репликацией изменений между ними. Однако, в случае потокового конвейера, когда одни приложения (продюсеры) непрерывно генерируют данные, обработать которые должны другие приложения (потребители), процесс масштабирования немного сложнее из-за большего количества элементов. Говоря в терминах AsyncAPI — спецификации описания асинхронных API, продюсеры публикуют сообщения в канал сервера – системы обмена сообщениями. Потребители подписываются на канал сервера, потребляют новые сообщения и обрабатывают их на своей стороне. Так реализуется паттерн асинхронной интеграции приложений через посредника. Продюсеры и потребители являются клиентами, а брокер сообщений, например, RabbitMQ или Apache Kafka, — сервером.

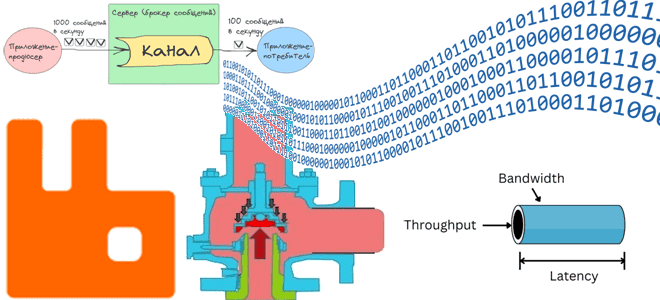
Общая пропускная способность такой потоковой системы из продюсеров, потребителей и брокера сообщений равна пропускной способности самого медленного звена. Например, если приложение-продюсер публикует 1000 сообщений в секунду, а приложение-потребитель может обработать только 100 сообщений в секунду, производительность всей системы равна 100 сообщений в секунду.

Современные брокеры сообщений имеют довольно высокую пропускную способность. Например, RabbitMQ может справиться с передачей 30-40 тысяч сообщений в секунду, а Apache Kafka – с миллионами. Поэтому масштабирование потокового конвейера, в основном сводится к увеличению количества экземпляров приложения-потребителя.
Возьмем в качестве брокера сообщений RabbitMQ, где канал реализуется очередью – FIFO-структурой данных, где в порядке публикации хранится опубликованное продюсером сообщение до тех пор, пока его не получит потребитель. Чтобы увеличить пропускную способность всего потокового конвейера, надо повысить скорость работы его самого медленного звена, т.е. потребителя. Увеличив количество потребителей в 10 раз, можно довести пропускную способность конвейера до 1000 сообщений в секунду.
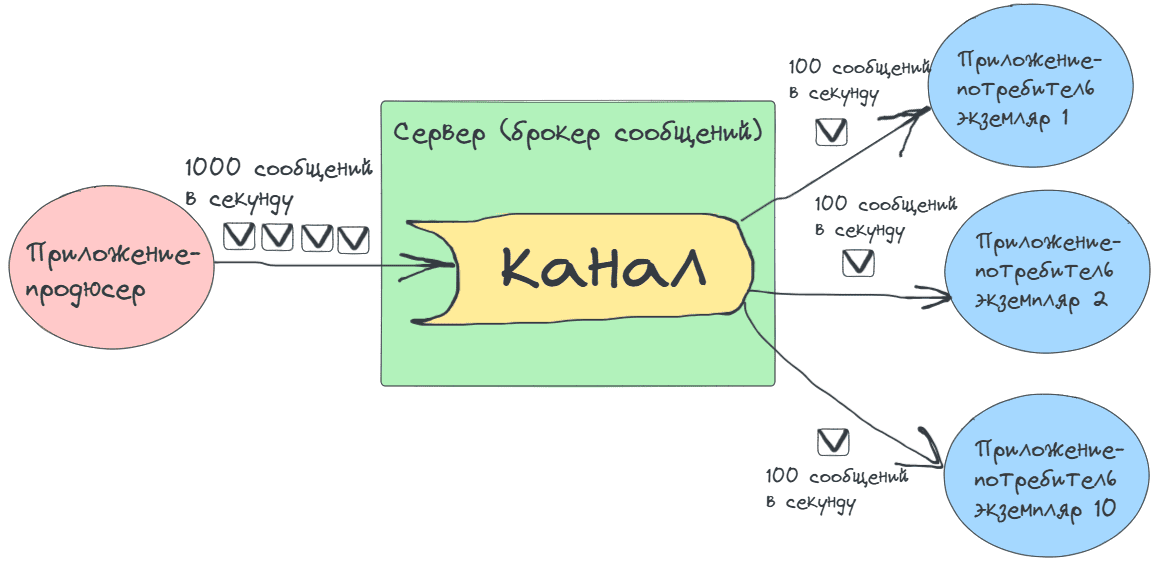
В RabbitMQ, когда несколько потребителей подписаны на одну очередь, сообщений между ними распределяются по принципу кругового перебора (Robin Round): 1-ое отправляется первому потребителю, 2-ое – второму, 3-е –третьему, 4-ое – снова первому и т.д. Таким образом, брокер сообщений сам реализует балансировку нагрузки, распределяя сообщения между потребителями. Такой способ отлично подходит для случаев, когда не нужно маршрутизировать сообщения по какому-то признаку, например, запросы с одного города направлять одному потребителю, а из другого – другому. Если нужна более сложная маршрутизация сообщений, в RabbitMQ она реализуется с помощью обмениников разных типов, нескольких очередей и правил привязки очереди и обменника. Подробно об этом я рассказывала здесь и здесь. В Apache Kafka каналом является топик, который может быть разделен на несколько разделов, чтобы аналогичным образом распределить нагрузку между набором потребителей.
Разумеется, помимо добавления экземпляра приложения-потребителя, надо подумать о масштабировании хранилища данных на стороне потребления, если обработка полученных сообщений предполагает сохранение их результатов. Обычно это реализуется с помощью репликации и балансировщика нагрузки для базы данных. Например, для PostgreSQL это может быть Pgpool-II, HAProxy или расширение Citus.
Обратное давление с установкой предела предварительной выборки
Вышерассмотренный пример масштабирования с добавлением экземпляров потребителей и каналов подходит для довольно простых случаев с постоянной и предсказуемой публикацией сообщений. На практике поток публикации может иметь непредсказуемые всплески, когда нагрузка становится неожиданно высокой. Приложения-потребители не успевают справиться с ростом объема данных. Растет задержка обработки скопившихся в канале сообщений. В случае RabbitMQ это даже может привести к потере данных, если при настройке очереди заранее определен ее размер и/или время жизни сообщения (message TTL).
Динамическое добавление нового экземпляра не всегда можно сделать автоматически. Поэтому приходится искать другие механизмы выравнивания производительности потокового конвейера. Одним из них является обратное давление (backpressure), который можно реализовать различными стратегиями.
Чтобы избежать перегрузки потребителя, в RabbitMQ можно настроить предел предварительной выборки (prefetch). Он определяет, сколько сообщений может получить потребитель до того, как подтвердит обработку предыдущих сообщений. Предел предварительной выборки устанавливается для каждого канала с помощью метода basic_qos(prefetch_size=0, prefetch_count=0, global_qos=False, callback=None):
- prefetch_size— размер окна предварительной выборки в байтах. Сервер отправит сообщение заранее, если его размер равен или меньше доступного размера предварительной выборки. Например, qos(prefetch_count=1) означает, что потребитель будет получать только одно сообщение за раз, пока не подтвердит его обработку (вручную или автоматически). Этот параметр не учитывается потребителями, которые автоматически отправляют RabbitMQ подтверждения об успешном потреблении сообщения из-за установки параметра auto_ack в значение True в методе basic_consume(queue, on_message_callback, auto_ack=False, exclusive=False, consumer_tag=None, arguments=None, callback=None), независимо от того, было ли оно успешно обработано. Примеры использования этого метода в коде приложения-потребителя я показывала здесь и здесь.
- prefetch_count – размер окна предварительной выборки в количестве сообщений. Этот параметр может использоваться вместе с prefetch-size. Сообщение будет отправлено приложению-потребителю только в том случае, если оба окна предварительной выборки (и на уровне канала, и на уровне соединения) это позволяют. Prefetch-count игнорируется потребителями, которые установили параметр auto_ack в значение True.
- global_qos — глобальная настройка предела предварительной выборки для всех потребителей на этом канале;
- callback(callable) – обратный вызов, функция, которая будет вызываться после выполнения текущего метода. Обычно не задается.
Установка предела предварительной выборки позволяет избежать ситуаций, когда один потребитель загружен слишком большим количеством сообщений. Это поможет оптимально использовать ресурсы и улучшить отзывчивость потокового конвейера на RabbitMQ в условиях переменной нагрузки. Читайте в моей новой статье, как описать потоковый конвейер на RabbitMQ в спецификации AsyncAPI 3.0.
Подробнее все эти и другие связанные темы по проектированию информационных систем разбираются на моих курсах Школы прикладного бизнес-анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Проектирование потокового конвейера на RabbitMQ с разработкой спецификации AsyncAPI
- Основы архитектуры и интеграции информационных систем