Зачем нужны альтернативные обменники в RabbitMQ, где настроить очередь недоставленных сообщений и как этот JMS-брокер обеспечивает альтернативную маршрутизацию. Пример топологии потокового конвейера и пара Python-сервисов, запущенных в Google Colab для публикации и потребления сообщений из очередей облачной платформы cloudamqp.com.
Постановка задачи и проектирование потокового конвейера на RabbitMQ
В отличие от Apache Kafka, JMS-брокер сообщений RabbitMQ реализует подход «умный сервер, тупой клиент», позволяя облегчить код потребителя за счет настроек самой платформы. Например, можно направлять сообщения, которые не смог обработать потребитель, в специализированный обменник-сборщик недоставленных сообщений. К этому обменнику будет привязана очередь недоставленных сообщений, на которую подписывается обработчик.
Аналогично можно настроить сбор сообщений, неотправленных в очередь из-за несоответствия правилам привязки. Например, если приложение-продюсер отправляет в обменник типа direct, headers или topic сообщение, которое не соответствует правилам привязки очереди к обменнику, оно будет отклонено. А, поскольку обменник не накапливает сообщения, а только маршрутизирует их, отклонение означает фактическую потерю данных.
Избежать этого можно, привязав к обменнику не только очередь с правилами привязки, но и альтернативный обменник, связанный с очередью для накопления отклоненных сообщений.
Чтобы продемонстрировать, как это работает, я написала и запустила в интерактивной среде Google Colab 2 небольших Python-сервиса для публикации и потребления сообщений из очередей RabbitMQ. Экземпляр брокера сообщений RabbitMQ у меня развернут в облачной платформе cloudamqp.com с бесплатным планом. Как она устроена, и какие возможности предоставляет пользователю, смотрите в прошлой статье.
Рассмотрим пример, когда на обменник типа direct, который маршрутизирует сообщения в очередь по точно заданному ключу маршрутизации, приложение-продюсер отправляет сообщения. Причем ключ маршрутизации не всегда устанавливается верно. Кроме того, иногда полезная нагрузка сообщения формируется не в том виде, на который рассчитывает приложение-потребитель.
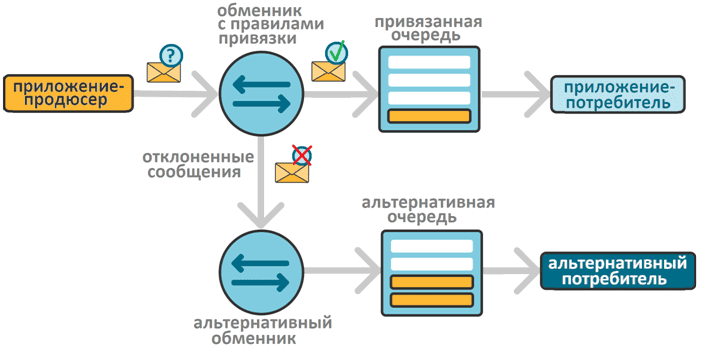
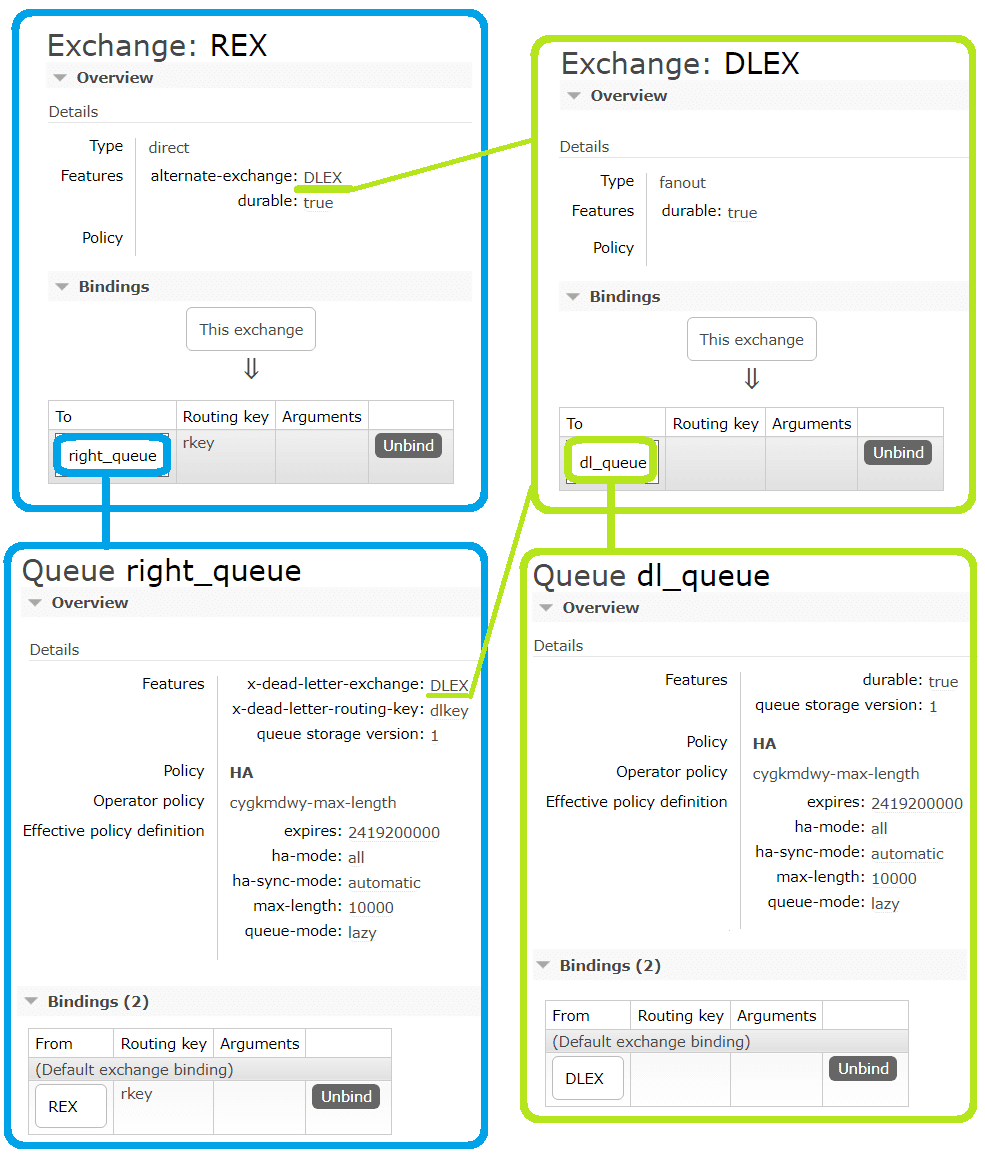
Чтобы реализовать это поведение, надо создать в GUI serverless-платформы RabbitMQ необходимые обменники и очереди. «Правильным» обменником, который принимает правильные сообщения у меня является обменник с названием REX типа direct. К нему привязана очередь right_queue по точно заданному ключу маршрутизации rkey. Альтернативным обменником для REX является обменник DLEX типа fanout, который просто перенаправляет сообщения в привязанную очередь dl_queue без проверки каких-либо правил. Помимо привязки альтернативного обменника к самому обменнику, я также привязала к очереди right_queue альтернативный обменник DLEX с альтернативным ключом dlkey. Это значит, что ключ маршрутизации будет переназначаться, если сообщение маршрутизируется на обменник DLEX из очереди right_queue. Такое возможно, если сообщение не может быть обработано приложением-потребителем, истек срок жизни сообщения или достигнут предел очереди.
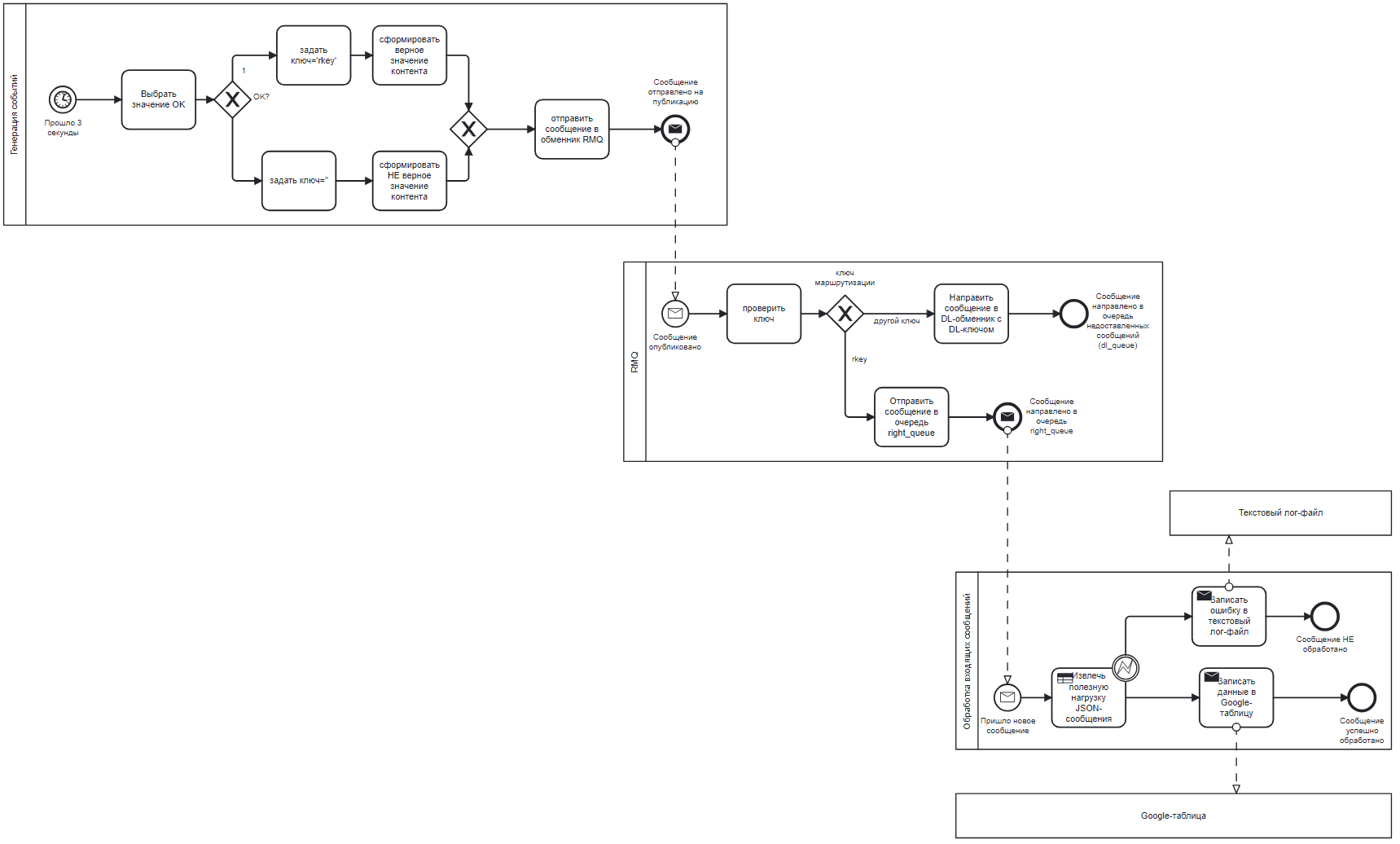
BPMN-диаграмма процессов работы с сообщениями выглядит так.
Далее рассмотрим реализацию Python-сервисов публикации и потребления сообщений по этой топологии потокового конвейера.
Пример реализации Python-сервисов потокового конвейера
Код приложения-продюсера, который каждые 3 секунды формирует и публикует в RabbitMQ сообщение, выглядит так:
################################### новая ячейка Colab ####################################################
#установка библиотеки
!pip install pika
#импорт модулей
import pika
import json
import random
from datetime import datetime
import time
import os
################################### новая ячейка Colab ####################################################
# Подключение к серверу RabbitMQ server в облачной платформе cloudamqp.com
connection = pika.BlockingConnection(pika.URLParameters('amqps://username:password@v-host.rmq.cloudamqp.com:port/username'))#учетные данные
channel = connection.channel()
# объявление обменника
exch='REX'
exch_type='direct'
alt_exh = 'DLEX'
channel.exchange_declare(exchange=exch, exchange_type=exch_type, durable=True, arguments={'alternate-exchange': alt_exh})
number=0 #начальный номер события
#бесконечный цикл публикации данных
while True:
start_time = time.time() # запоминаем время начала отправки сообщения
#подготовка данных для публикации в JSON-формате
producer_publish_time = time.strftime("%m/%d/%Y %H:%M:%S", time.localtime(start_time))
number=number+1
#задаем ключ маршрутизации (верный или для dlq)
OK = random.choice([1,0])
if OK==1:
rk='rkey'
content=f'ВСЕ НОРМАЛЬНО, произошло событие номер {number}'
#создаем полезную нагрузку в JSON
data = {'producer_publish_time': producer_publish_time,'content': content}
else :
rk=''
content='НЕКОРРЕКТНОЕ измерение'
data = {'event_time': producer_publish_time,'content': content}
message = json.dumps(data)
#отправка сообщения в обменник RabbitMQ с ключом маршрутизации и свойствами (заголовок)
channel.basic_publish(exchange=exch, routing_key=rk, body=message)
#вывод отладочной информации
print(f' ключ маршрутизации {rk} Сообщение {number} отправлено {message}')
#повтор через 3 секунды
time.sleep(3)
################################### новая ячейка Colab ####################################################
#закрываем канал и соединение
channel.close()
connection.close()
Код приложения-потребителя, который считывает данные из «правильной» очереди right_queue и записывает данные в Google-таблицу, выглядит так:
################################### новая ячейка Colab ####################################################
#установка библиотек
!pip install pika
#импорт модулей
import pika
import json
import random
import requests
from datetime import datetime
#импорт модулей для GS
from google.colab import auth
auth.authenticate_user()
import gspread
from google.auth import default
creds, _ = default()
################################### новая ячейка Colab ####################################################
# Подключение к серверу RabbitMQ server в облачной платформе cloudamqp.com
connection = pika.BlockingConnection(pika.URLParameters('amqps://username:password@v-host.rmq.cloudamqp.com:port/username'))#учетные данные
channel = connection.channel()
#объявление очереди RQM
dlrk='dlkey'
alt_exh = 'DLEX'
my_queue='right_queue'
questions_queue = channel.queue_declare(queue=my_queue, arguments={'x-dead-letter-exchange': alt_exh, 'x-dead-letter-routing-key': dlrk})
#Google Sheets Autentificate
gc = gspread.authorize(creds)
#Открытие заранее созданного файла Гугл-таблицы по идентификатору (взять из его URL, например, у меня это https://docs.google.com/spreadsheets/d/1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM)
sh = gc.open_by_key('1ZQuotMVhaOuOtnZ56mvd1zX-5JOhsXc1WTG6GTBjzzM')
wks = sh.worksheet("test_0") #в какой лист гугл-таблиц будем записывать
#начальный номер строки для записи данных
x=1
def on_inputs_message(ch, method, properties, body):
global x
try:
# распаковка сообщения
data = json.loads(body)
# парсинг сообщения
producer_publish_time = data['producer_publish_time']
content = data['content']
now = datetime.now()
consuming_time = now.strftime("%m/%d/%Y %H:%M:%S")
# вывод распарсенных данных в консоль
print(f'{json.dumps(data)}')
# обновление данных в Google Sheets
print(x)
x += 1
wks.update_cell(x, 1, producer_publish_time)
wks.update_cell(x, 2, consuming_time)
wks.update_cell(x, 3, content)
except Exception as e:
# запись ошибок в лог-файл на Google Диске
error_str = f"Error: {str(e)}, Value: {data}\n"
with open("dlq.txt", "a") as f:
f.write(error_str)
print(f"Error: {str(e)}")
#потребляем данные из RabbitMQ
while True:
print('Waiting for messages. To exit press CTRL+C')
#привязка к очереди headers-обменника RQM
channel.basic_consume(queue=questions_queue.method.queue, on_message_callback=on_inputs_message, auto_ack=True)
channel.start_consuming()
################################### новая ячейка Colab ####################################################
#закрываем канал и соединение
channel.close()
connection.close()
В коде потребителя команды обработки считанного сообщения заключены в конструкцию try-except. Это предупреждает сбой потребления из-за исключений, возникающих, если схема данных потребленного сообщения не совпадает с заложенным алгоритмом синтаксического разбора,. Такие сообщения записываются в текстовый лог-файл dlq.txt, расположенный в рабочей директории сеансового пространства среды Google Colab. В данном примере этот файл остается пустым по той причине, что в очередь потребления right_queue сообщения с «неправильно» структурой данных просто-напросто не попадают из-за алгоритма формирования полезной нагрузки точно в соответствии с ключом маршрутизации маршрутизации.
Результат работы представлен на картинке.
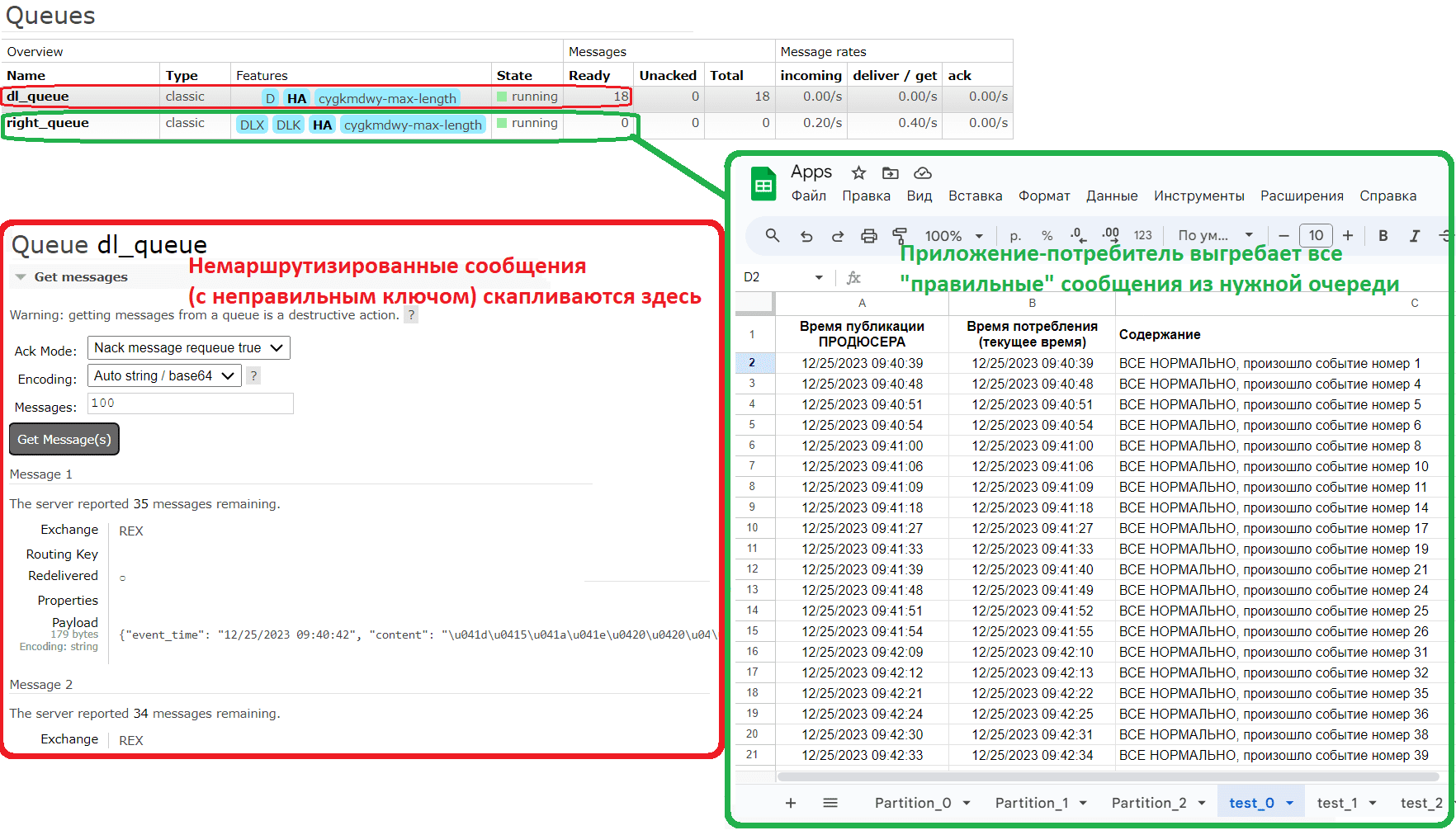
Весь код, приведенный в этой статье, работает. Можно повторить все действия, настроив свой облачный экземпляр брокера сообщений и подставив нужные учетные данные. Надеюсь, после этого краткого ликбеза стали понятные принципы работы RabbitMQ, что часто используется для интеграции ИС и асинхронного взаимодействия микросервисов в виде приложений-потребителей и продюсеров.
Подробнее все эти и другие связанные темы по проектированию информационных систем разбираются на моих курсах Школы прикладного бизнес-анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Проектирование потокового конвейера на RabbitMQ с разработкой спецификации AsyncAPI
- Основы архитектуры и интеграции информационных систем