Как оценить необходимость применения CQRS с учетом RPS, и какие еще факторы, кроме нагрузки, влияют на выбор этого архитектурного паттерна. Примеры и схемы.
Еще раз про CQRS и Polyglot Persistence
Недавно я показывала, как рассчитать нагрузку на систему, чтобы задать точные требования к ее производительности в значения RPS (Request Per Second). Полученные значения этого показателя для разных профилей нагрузки (на чтение и на запись) позволяют принять решение о необходимости разделять единое хранилище данных на несколько разных. Это соответствует подходу Polyglot Persistence, предложенному Мартином Фаулером еще в начале 2010-хх гг. В этом подходе одна система использует несколько технологий хранения и организации данных, каждая из которых оптимизирована под конкретные сценарии использования. Например, реляционные базы данных подходят для ACID-транзакций над данными в связанных таблицах со строгой схемой, а для примитивных структур типа ключ-значение можно использовать соответствующие key-value хранилища.
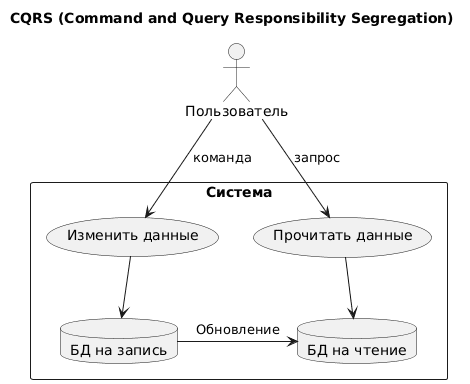
Аналогичную мысль о профилировании хранилищ данных реализует и архитектурный паттерн CQRS (Command and Query Responsibility Segregation), согласно которому запросы на чтение данных отделяются от команд на мутации. Такое разделение позволяет оптимизировать хранилище данных под конкретный профиль нагрузки, повысить масштабируемость системы, ее быстродействие и безопасность. За команды, т.е. мутации данных обычно отвечает реляционная БД, обеспечивая ACID-требования к транзакциям, а быстрый ответ на запросы, в т.ч. аналитические, реализуется с помощью NoSQL-решений с высокой доступностью.
Технологии реализации и их влияние на архитектуру системы
Синхронизация изменений, чтобы данные в разных хранилищах были согласованы между собой, реализуется с помощью CDC-инструментов (Change Data Capture). Например, можно настроить триггерную функцию на таблицы PostgreSQL, которая будет вызывать службу экспорта изменений в другую БД при INSERT, UPDATE и DELETE-операциях. При большом потоке таких событий обычно настраивается логическая репликация и используется комбинация коннекторов Debezium с Apache Kafka или аналогичным брокером сообщений. Например, так можно передать изменения из реляционной PostgreSQL (БД на запись) в документо-ориентированный Elasticsearch (БД на чтение). Практическую реализацию такого ETL-конвейера я показывала в блоге нашей Школы Больших Данных здесь и здесь.

В итоге команды и запросы могут обрабатываться асинхронно, что повышает производительность и масштабируемость системы в целом. Однако, увеличение количества элементов в системе снижает ее надежность. В частности, для маршрутизации команд и запросов к соответствующим сервисам, которые будут затем обращаться к разным хранилищам, часто используется специальный шлюз (API Gateway) в виде готового или самописного решения. Для сохранения историчности данных в архитектуре может появиться хранилище событий (паттерн Event Sourcing), куда записываются все изменения, чтобы откатить систему к исходному состоянию при необходимости.
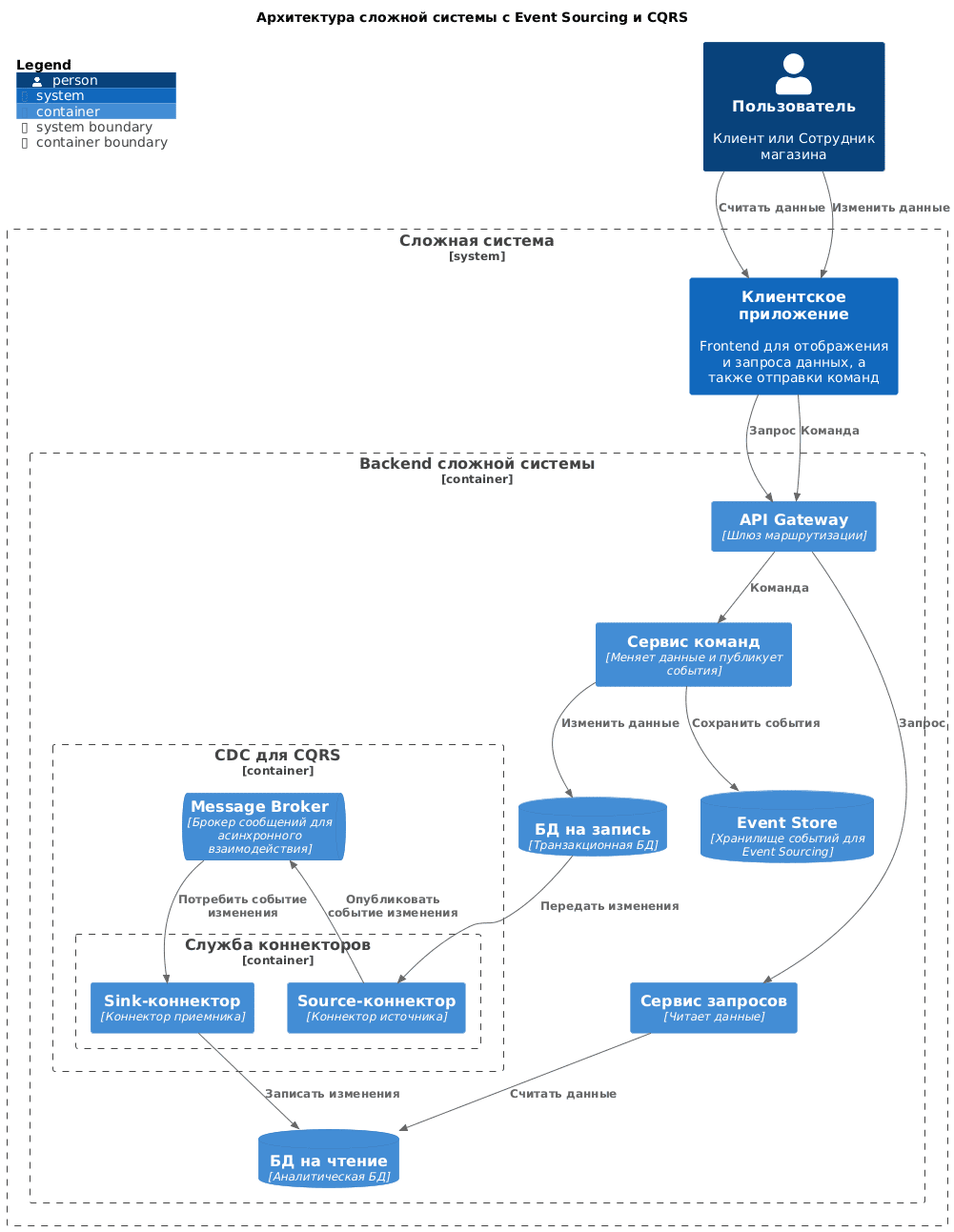
PlantUML-код для этой диаграммы С4:
@startuml
!include <C4/C4_Container>
title Архитектура сложной системы с Event Sourcing и CQRS
Person(U, "Пользователь", "Клиент или Сотрудник магазина ")
System_Boundary(S, "Сложная система") {
System(F, "Клиентское приложение", "Frontend для отображения и запроса данных, а также отправки команд")
Container_Boundary(c2, "Backend сложной системы") {
Container(AG, "API Gateway", "Шлюз маршрутизации")
Container(QS, "Сервис запросов", "Читает данные")
Container(CS, "Сервис команд", "Меняет данные и публикует события")
ContainerDb(RDB, "БД на чтение", "Аналитическая БД")
ContainerDb(WDB, "БД на запись", "Транзакционная БД")
ContainerDb(ES, "Event Store", "Хранилище событий для Event Sourcing")
Container_Boundary(c3, "CDC для CQRS") {
Container_Boundary(c4, "Служба коннекторов") {
Container(SoC, "Source-коннектор", "Коннектор источника")
Container(SiC, "Sink-коннектор", "Коннектор приемника")
}
ContainerQueue(MB, "Message Broker", "Брокер сообщений для асинхронного взаимодействия")
}
}
}
Rel(U, F, "Считать данные")
Rel(U, F, "Изменить данные")
Rel(F, AG, "Запрос")
Rel(F, AG, "Команда")
Rel(AG, QS, "Запрос")
Rel(AG, CS, "Команда")
Rel(QS, RDB, "Считать данные")
Rel(CS, ES, "Сохранить события")
Rel(CS, WDB, "Изменить данные")
Rel(WDB, SoC, "Передать изменения")
Rel(SoC, MB, "Опубликовать событие изменения")
Rel(MB, SiC, "Потребить событие изменения")
Rel(SiC, RDB, "Записать изменения")
SHOW_LEGEND()
@enduml
Но увеличение архитектурной сложности системы приводит к росту затрат. Поэтому нужно понять, насколько польза от усложнения системы превышает возможные риски и их последствия для бизнеса. Например, что хуже для интернет-магазина: неактуальные цены в каталоге товаров или увеличение времени отклика на пользовательские запросы? Оценив последствия каждого риска в деньгах, можно сопоставить эту сумму со стоимостью мероприятий по их предотвращению. К примеру, при увеличении времени отклика на 20% средняя выручка в день снижается на 45%, что составляет 500 000 рублей недополученной прибыли ежедневно. Чтобы ускорить работу системы, придется увеличить расходы на ИТ-инфраструктуру на 250 000 тысяч в месяц, разделив хранилища данных по CQRS и добавив компоненты их синхронизации. Сравнив суммы потерь и затрат, можно посчитать это решение довольно выгодным. Однако, для полноценных выводов надо также рассчитать, какие потери понесет магазин, если изменения в БД на запись не отразятся в БД на чтение из-за отказа какого-то звена (службы коннекторов, брокера и т.д.). Поэтому высокие значения RPS (от 1000) для разных профилей нагрузки совершенно не являются однозначной рекомендацией к внедрению CQRS или отказу от него.
Как обычно, при сравнении альтернатив для принятия архитектурных решений надо оценить плюсы, минусы и последствия каждого варианта. Причем, это нужно сделать не только в текущий момент, но с прицелом на будущее, ответив на следующие вопросы:
- как будет развиваться бизнес, насколько будет расти число пользователей, и как будет меняться их взаимодействие с системой?
- каковы тенденции в изменении подходов к разработке и сопровождению системы? Например, планируется перейти на эластичную облачную инфраструктуру, или, наоборот, вернуться к собственным серверам.
Кроме этого, при выборе решений также надо учитывать ограничения/рекомендации корпоративных архитектурных документов: техрадара, а также каталога (справочника) стандартов и шаблонов проектирования. Также стоит рассмотреть другие подходы к масштабированию, например, партиционирование и шардирование, которым посвящена моя новая статья.
Про это и другие архитектурные компромиссы, связанные с проектированием информационных систем и баз данных, я рассказываю на моих курсах Школы прикладного бизнес-анализа в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве: