Что такое очереди общего доступа в Kafka и зачем они нужны: как KIP-932 расширяет возможности самой популярной платформы потоковой передачи событий, чем группа общего доступа отличается от классической группы потребителей.
Что такое очереди общего доступа в Kafka и зачем они нужны
В недавней статье про потоковые очереди в RabbitMQ я упоминала, что это нововведение расширяет набор сценариев применения популярного брокера сообщений, немного делая его похожим на Apache Kafka. Аналогичное расширение возможностей есть и в Kafka, реализованное в рамках KIP-932 (Kafka Improvement Proposal).
Появившись впервые в 2023 году, очереди или группы общего доступа (share group) введены для совместного потребления данных несколькими потребителями из Kafka. Это меняет типичную модель потребления, когда в группе потребителей с одинаковым значением свойства group.id возможно только эксклюзивное считывание данных по принципу «1 раздел – 1 потребитель». Раздел считается единицей параллелизма в Kafka и представляет собой каталог лог-файлов на одном узле кластера. Сообщения в каждом разделе топика хронологически упорядочены и потребляются только одним потребителем в каждой группе потребителей. Такой однопоточный режим обеспечивает хронологический порядок обработки данных в пределах раздела. Количество разделов ограничено максимальным параллелизмом потребителя.
Монопольное закрепление одного потребителя за одним разделом топика является фундаментальной основой горизонтального масштабирования конвейера потоковой обработки данных через Kafka. Но это не подходит для сценариев с классическими очередями, когда сообщения из любого раздела всего топика должны обрабатываться строго по порядку любым потребителем из всего набора приложений, потребляющих данные.
KIP-932 исключает зависимость от раздела топика: каждое сообщение будет обработано каждым потребителем, даже если оно находится в разделе топика Kafka, на который назначено несколько потребителей. При этом сообщения динамически распределяются между доступными потребителями, что повышает гибкость потоковой системы и повышает эффективность утилизации ресурсов. Таким образом, в группе общего доступа потребители совместно потребляют данные из всех разделов и общее количество потребителей может быть больше, чем количество разделов.
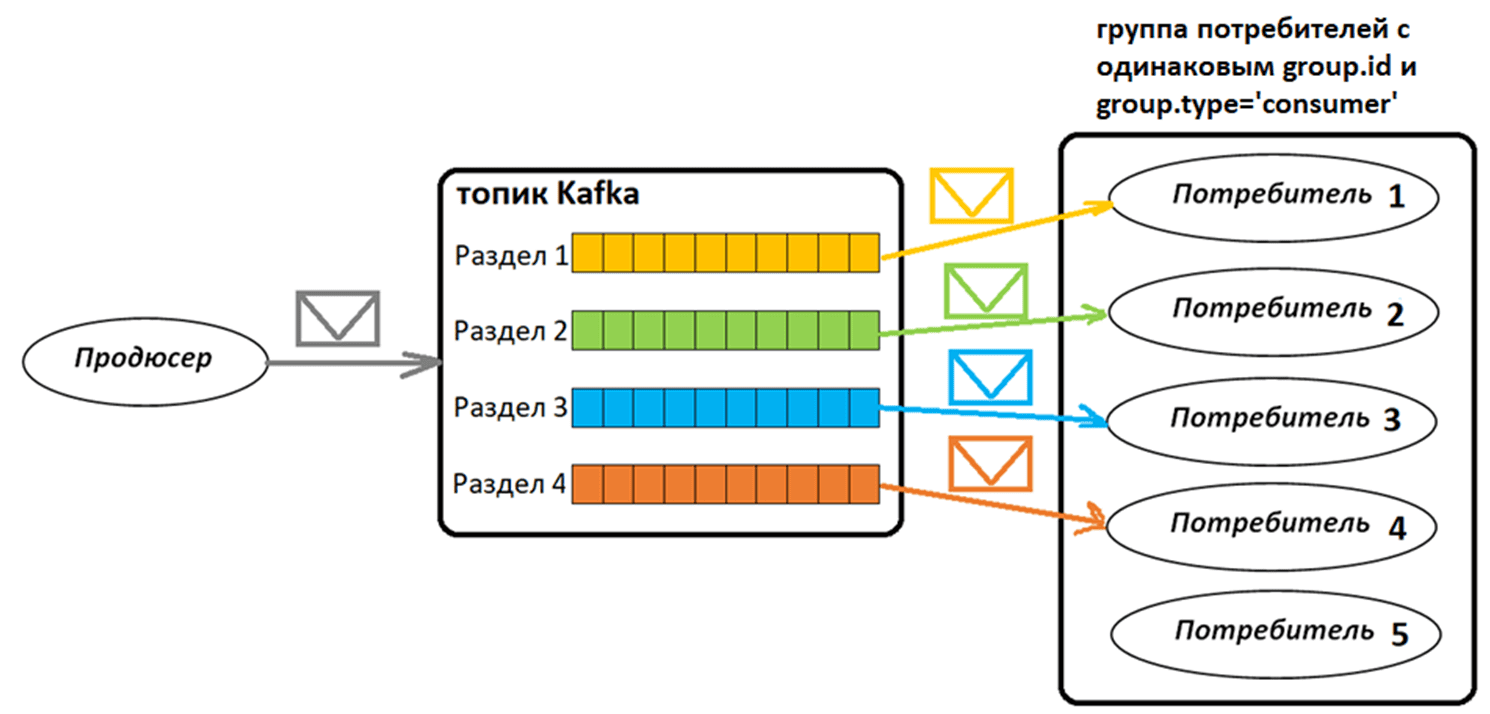
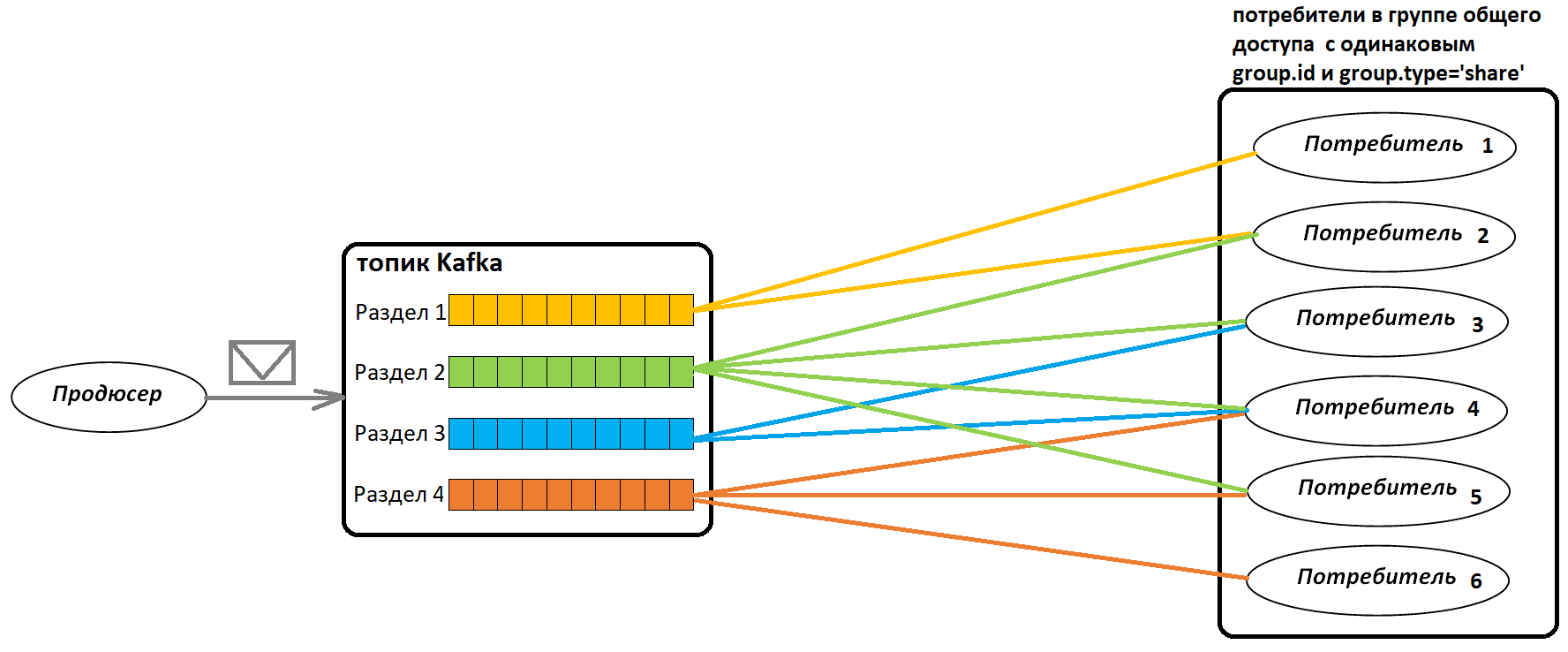
Какую модель потребления использовать, определяет конфигурация потребителя group.type, которая может принимать следующие значения:
- ‘consumer’ – для классической модели потребления с эксклюзивным назначением одного активного потребителя на один раздел топика Kafka из группы потребителей с одинаковым значением параметр group.id;
- ‘share‘ – для групп общего доступа, новой модели потребления с совместным потреблением данных из всех разделов топика Kafka из группы потребителей с одинаковым значением параметр group.id.
По умолчанию group.type=’consumer’. Но даже при изменении значения этого параметра на ‘share‘, задавать значение group.id все равно надо, т.к. именно это определяет, к какой группе относится потребитель.
Классическая группа потребителей с group.type=’consumer‘ – это набор клиентов-потребителей, которые вместе читают сообщения из топика kafka, разделяя потребление по разделам. Каждый раздел читает только один потребитель из группы с одинаковым значением group.id. Это позволяет масштабировать потребление данных и гарантировать, что каждое сообщение будет обработано только одним потребителем из группы, без дублирования данных. Например, несколько экземпляров одного сервиса входят в одну группу потребителей и потребляют данные из разделов топика Kafka. При этом каждый экземпляр читает свою часть данных: сообщения не дублируются.
Группы общего доступа с group.type=’share‘ позволяют потреблять данные из всех разделов одного топика разным потребителям, независимо друг от друга. При этом каждый потребитель получает все сообщения, независимо от того, какие еще системы тоже их получили. У всех потребителей есть своя, полная копия данных. Это полезно, когда нужно изолировать обработку сообщений между разными бизнес-задачами и/или обеспечить отказоустойчивость и независимость потребителей друг от друга.
На практике классические группы потребителей с group.type=’consumer‘ обычно используются для масштабирования потребления внутри одного сервиса. А группы общего доступа с group.type=’share‘ применяются для независимого доступа разных приложений к одному и тому же потоку данных. Аналогичное поведение реализуется, если задать разные значения параметра group.id для разных потребителей. Однако, при использовании разных group.id каждый потребитель фактически становится отдельной группой со своими смещениями, что усложняет администрирование Kafka при большом количестве потребителей.
Особенности реализации и разница групп потребителей
Классические группы потребителей и группы общего доступа находятся в одном пространстве имен в кластере Kafka. Поэтому они должны иметь разные имена. Членство в группе общего доступа контролирует специальный брокер в кластере Kafka, координатор группы. Аналогично классической группе потребителей, потребители в группе общего доступа также используют heartbeat-механизм для присоединения, выхода и подтверждения дальнейшего членства. В группе общего доступа перебалансировка потребителей происходит быстрее и меньше влияет на обработку данных из-за отсутствия жесткого ограничения «1 потребитель на 1 раздел».
Kafka отслеживает, какие сообщения были доставлены и подтверждены каждым потребителем внутри одной группы. В классической группе потребителей смещения, т.е. позиции сообщений в разделе топика, сохраняются в топике смещений __consumer_offsets. Этот топик также имеет разделы и реплики, подобно обычному топику Kafka. Каждое смещение для пары группа потребителей и раздел хранится как отдельное сообщение в этом топике. Такое сообщение имеет следующую структуру:
- ключом является комбинация id, топик и раздел;
- значение – это смещение (номер позиции), метаданные, отметка времени и пр.
Для групп общего доступа смещения сохраняются внутри данных самого топика, как часть его метаданных. Для этого в Kafka появились специальные таблицы, отслеживающие статус каждого сообщения для различных потребителей. Это позволяет отслеживать, какие потребители уже получили какие сообщения, а каким это еще предстоит. Для этого каждый потребитель в группе общего доступа имеет свой уникальный идентификатор, который записывается в метаданные топика, вместе с текущими смещениями потребителей в группе общего доступа и флагом подтверждения обработанного сообщения каждым потребителем.
Также в метаданных сообщения есть счетчик доставки, чтобы лимитировать количество попыток повторной доставки сообщений потребителям. Когда сообщение потребляется потребителем в группе общего доступа, его счетчик доставки инкрементируется на 1. За это отвечает брокер-лидер общего раздела, т.е. раздела, на который подписаны потребители из группы общего доступа.
Потребитель в группе общего доступа потребляет доступные сообщения из любого раздела топика, соответствующего его подпискам. Чтобы гарантировать, что каждое сообщение потребляется только одним потребителем, оно блокируется для других на время, заданное в параметре потребителя или коннектора share.record.lock.duration.ms. По умолчанию длительность блокировки составляет 30 миллисекунд. Эта блокировка автоматически снимается по истечении заданного времени, чтобы сообщение стало доступным для потребления другому потребителю. Но вообще потребитель, удерживающий блокировку, может действовать следующим образом:
- подтвердить успешную обработку сообщения, отправив подтверждение-commit, чтобы проинформировать, до какого смещения он обработал данные;
- освободить блокировку сообщения, сделав его доступным для другой попытки доставки;
- отклонить сообщение, исключив возможность повторной попытки доставки;
- не делать ничего, чтобы снять блокировку автоматически по истечении ее заданного периода.
Количество сообщений, полученных потребителями в группе общего доступа, лимитируется для каждого раздела топика с помощью значения в конфигурации брокера group.share.partition.max.record.locks. Если этот лимит превышается, потребление записей временно прекращается и возобновляется снова естественным образом по истечении времени блокировки. Такая блокировка потребления сообщений и ее автоматическое снятие позволяет Kafka обеспечивать бесперебойную доставку сообщений даже при сбоях потребителей. А хранение смещений, количества попыток доставки и подтверждений в виде метаданных позволяет подтверждать потребление индивидуально на уровне каждого потребителя. Это позволяет повторно передавать сообщение другому потребителю, обеспечивая бесперебойную потоковую обработку данных при сбое отдельных потребителей.
Также благодаря хранению смещений и подтверждений в метаданных очереди, потребители из группы общего доступа могут возвращать в Kafka подтверждения индивидуально для каждого сообщения. Но на практике, для повышения эффективности, потребители обычно возвращают в Kafka подтверждения не индивидуально по каждому сообщению, а по пакету сообщений. Это настраивается в конфигурациях потребителя enable.auto.commit и auto.commit.interval.ms.
Таким образом, KIP-932 расширяет набор сценариев использования Apache Kafka, добавляя возможности репликации и многократного потребления одного и того же потока данных разными приложениями. Это похоже на сценарии широковещательной подписки с классическими очередями, позволяя нескольким независимым приложениям/сервисам быть участниками одной группы потребителей и обрабатывать сообщения параллельно. При сбое одного потребителя другие участники группы продолжают получать свои копии сообщений, не прерывая потоковую обработку.
| Критерий | Классическая группа потребителей | Группа общего доступа |
| Настройка конфигураций | group.type=’consumer‘ и для каждой группы указывается уникальный group.id в настройках потребителя | group.type=’share‘ и для каждой группы указывается уникальный group.id в настройках потребителя |
| Хранение смещений | На брокере Kafka в специальном топике __consumer_offsets | На брокере Kafka в метаданных топика с сообщениями |
| Дублирование сообщений | Каждое сообщение в разделе топика доставляется только одному активному потребителю из группы. В пределах одной группы дублирования данных нет. Если несколько групп потребителей читают один и тот же топик, то каждое сообщение получит один потребитель из каждой группы. Дублирование данных между разными группами потребителей возможно. | Сообщения транслируются всем потребителям в группе. Каждый потребитель получает полный поток сообщений, т.е. происходит дублирование полученных данных между потребителями. |
| Сценарии применения | Горизонтальное масштабирование без дублирования данных. Сбалансированная по нагрузке потоковая обработка событий, где каждое сообщение должно быть обработано только одним экземпляром приложения. | Многократное потребление одного и того же потока данных разными приложениями. Несколько сервисов должны видеть один и тот же поток сообщений. Долгие и повторяющиеся задачи с повторной обработкой, сложные сценарии маршрутизации с разной логикой обработки |
| Примеры применения | Обработка заказов, проведение оплат, принятие решений в реальном времени | Отправка уведомлений, трансляция событий, мониторинг и аналитика |
В заключение отмечу, что KIP-932 хотя и делает Kafka ближе к классическим брокерам сообщений типа RabbitMQ, он не превращает ее в кролика с FanOut-обменником, связанным с несколькими очередями. Подробнее об отличиях между Kafka и RabbitMQ расскажу в следующий раз. А пока рекомендую почитать мою новую статью про гарантии доставки сообщений: почему это задача продюсера и потребителя, а не просто брокера.
Научиться работать с RabbitMQ, а также с другими технологиями проектирования архитектуры и интеграции информационных систем вы сможете на моих курсах Школы прикладного бизнес-анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Apache Kafka для дата-инженера и системного аналитика
- Проектирование потокового конвейера на RabbitMQ с разработкой спецификации AsyncAPI
- Основы архитектуры и интеграции информационных систем