Как хранить данные в памяти без развертывания сервера СУБД: ликбез по реляционным и нереляционным In-Memory хранилищам на примере SQLLite, NebulaGraph Lite, DuckDB и Redis.
Зачем нужны резидентные БД и какие они бывают
Хотя главное назначение базы данных – персистентное, т.е. долговременное хранение информации, есть особая категория встраиваемых СУБД, которые хранят данные в оперативной памяти, а не на диске. Они называются резидентные и работают, будучи встроенными в вычислительный процесс, запущенный внутри приложения. Благодаря отсутствию операций дискового ввода-вывода, резидентные БД позволяют работать с данными практически в реальном времени, с минимальной задержкой. Это полезно для для приложений, где важен мгновенный отклик: торговые системы, финансовые платформы, онлайн-игры и мобильные приложения.
Сегодня наиболее популярными примерами резидентных баз данных считаются следующие:
- SQLLite – компактная встраиваемая однофайловая реляционная СУБД, которая не имеет сервера и хранит всю базу локально на одном устройстве. SQLite не требует отдельного серверного процесса. Все данные хранятся в одном файле на диске, что упрощает развертывание и управление. SQLite обеспечивает ACID-требования к транзакциям, а для работы с данными использует API SQL-запросов. Она не обладает широким набором возможностей, который есть у PostgreSQL и не подходит для высоконагруженных серверных приложений с большим количеством одновременных записей. Тем не менее, библиотека SQLite занимает всего несколько сотен килобайт, что делает эту СУБД идеальной для мобильных и встроенных систем.
- NebulaGraph Lite — облегченная версия графовой базы данных NebulaGraph, разработанная для упрощения развертывания и использования в небольших проектах или на этапе разработки. Она предоставляет основные функции полнофункциональной версии NebulaGraph, но с упрощенной конфигурацией и меньшими системными требованиями, предоставляя возможности мощной графовой базы данных на малых ресурсах.
- DuckDB – колоночная аналитическая СУБД с векторизированным механизмом обработки SQL-запросов. Как и SQLLite, она не требует выделенного сервера и работает внутри хост-процесса. Например, благодаря привязкам для интерпретатора Python можно напрямую размещать данных в массивах NumPy. DuckDB предназначена для встраивания в приложения на различных языках программирования, включая Python, R, C++, и другие. Колоночная архитектура позволяет эффективно сжимать данные и ускорять выполнение аналитических запросов, поскольку доступ к данным происходит по столбцам, а не по строкам. DuckDB ориентирована на бессерверные приложения быстрой аналитики больших объемов данных в интерактивном режиме. Она хорошо подходит для мобильных Data Science приложений и систем, которым нужна высокая производительность аналитической обработки больших объемов данных при ограниченных ресурсах.
- Redis (REmote DIctionary Server) – высокопроизводительное хранилище данных в памяти с открытым исходным кодом. Это БД часто используется в качестве внешнего кэша и брокера сообщений. В отличие от многих других key-value хранилищ, Redis поддерживает различные структуры данных: строки, хэши, списки, множества, отсортированные множества, битмапы, гиперлоглоги и геопространственные индексы. Это позволяет выбирать наиболее подходящий тип данных для конкретных задач. Примеры работы с Redis на Python я показывала здесь и здесь.
Чтобы показать резидентный характер перечисленных баз данных, далее я выполню небольшую демонстрацию, запустив их с движком исполнения in-memory в Python-процессе на интерактивной виртуальной машине Google Colab.
SQLLite
В качестве примера напишем Python-скрипт, который создаёт временную базу данных, добавляет в неё случайных клиентов и их заказы. Затем получим агрегированную информацию о том, сколько каждый клиент потратил денег, вычислив LTV (Live Time Value) и сколько заказов у него было.
Сперва установим библиотеки и импортируем модули.
# установка библиотек
!pip install faker
# импорт модулей
import sqlite3
import os
import random
from faker import Faker
from faker.providers.address.ru_RU import Provider
from datetime import datetime
# инициализация Faker
fake = Faker("ru_RU")
Установим подключение к SQLLite, запущенной в памяти. Данные будут храниться только во время выполнения программы и исчезнут после её окончания. Создадим таблицы, определив столбцы и их типы данных. Для удобства вставки данных используем автоинкрементацию первичного ключа.
# подключение к базе данных
conn = sqlite3.connect(':memory:') #БД в памяти
cursor = conn.cursor()
# создаем таблицы в БД
cursor.executescript('''
CREATE TABLE IF NOT EXISTS customers (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL
);
CREATE TABLE IF NOT EXISTS orders (
id INTEGER PRIMARY KEY AUTOINCREMENT,
amount INTEGER NOT NULL,
moment TIMESTAMP NOT NULL,
customer INTEGER NOT NULL,
FOREIGN KEY (customer) REFERENCES customers(id)
);
''')
conn.commit()
Определим функции вставки данных и подсчета агрегаций
# функция добавления клиента
def add_customer(name, email):
try:
cursor.execute('''
INSERT INTO customers (name, email) VALUES (?, ?)
''', (name, email))
conn.commit()
print(f'Клиент {name} добавлен.')
except sqlite3.IntegrityError:
print('Ошибка: Такой email уже существует')
# функция добавления заказа
def add_order(amount, customer_id):
try:
current_time = datetime.now()
cursor.execute('''
INSERT INTO orders (amount, moment, customer) VALUES (?, ?, ?)
''', (amount, current_time, customer_id))
conn.commit()
except sqlite3.IntegrityError:
print('Ошибка: такой клиент НЕ существует')
# функция получения агрегатов заказов по клиентам
def get_customer_orders():
cursor.execute('''
SELECT
customers.name AS "Имя клиента",
customers.email AS "Email клиента",
SUM(orders.amount) AS "LTV",
COUNT(orders.id) AS "Количество заказов"
FROM orders
JOIN customers ON customers.id = orders.customer
GROUP BY customers.id
''')
rows = cursor.fetchall()
for row in rows:
print(row)
Вставим данные, сгенерировав значения с помощью библиотеки Faker:
# добавляем клиентов
customers_quantity = random.randint(1, 10)
for _ in range(customers_quantity):
name = fake.name()
email = fake.unique.free_email()
add_customer(name, email)
# получаем список существующих клиентов
cursor.execute('SELECT id FROM customers')
customer_ids = [row[0] for row in cursor.fetchall()]
# добавляем заказы
if customer_ids:
orders_quantity = random.randint(1, 10) * len(customer_ids)
for _ in range(orders_quantity):
amount = random.randint(1, 1000)
customer_id = random.choice(customer_ids)
add_order(amount, customer_id)
else:
print('Нет клиентов для добавления заказов')
Наконец, подсчитаем агрегаты и выведем результат:
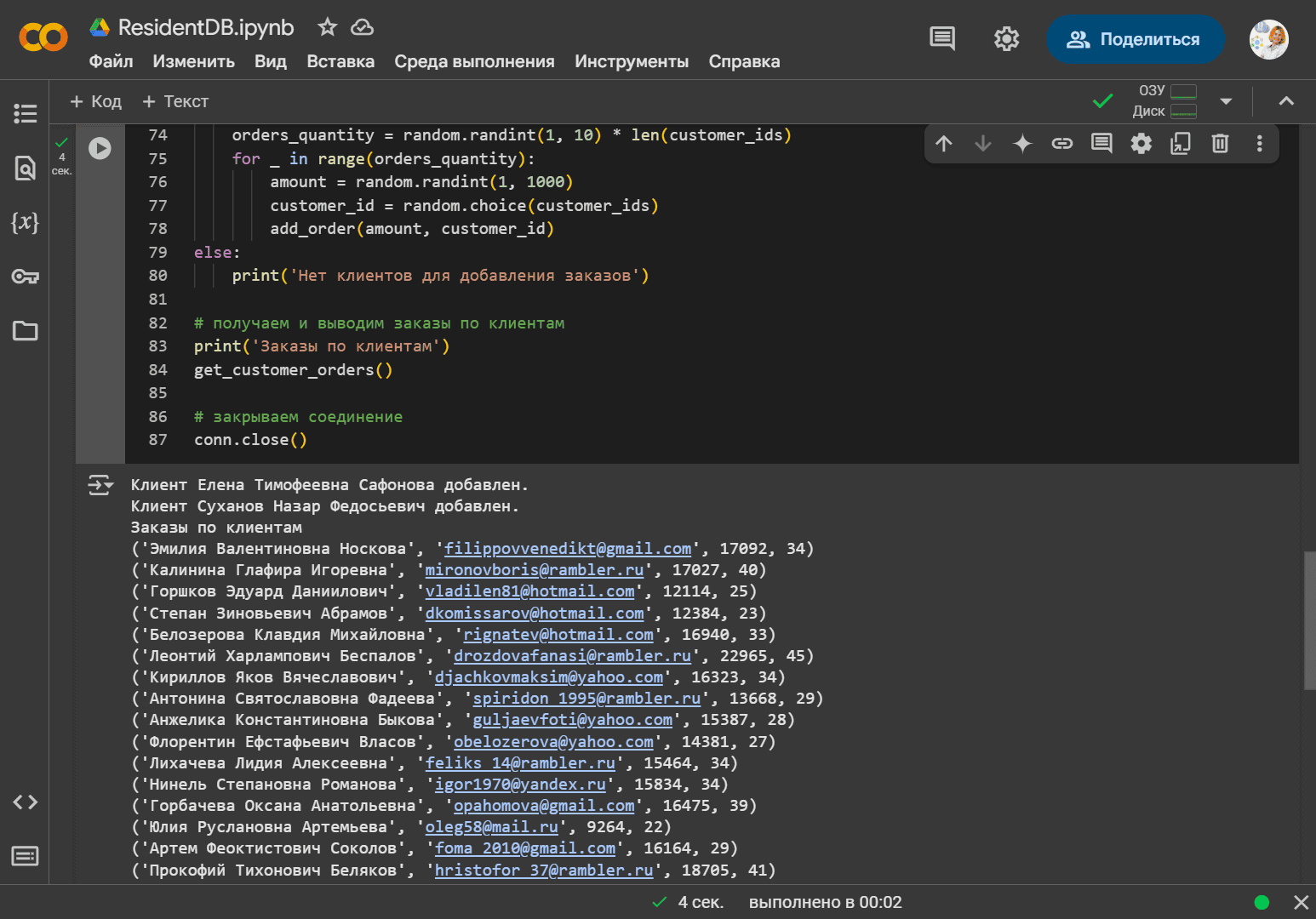
# получаем и выводим заказы по клиентам
print('Заказы по клиентам')
get_customer_orders()
# закрываем соединение
conn.close()
DuckDB
Продолжая пример с ритейл-доменом, в DuckDB создадим таблицы с товарами и поставщиками. Сперва установим библиотеки и импортируем модули
!pip install duckdb import duckdb import random from faker import Faker from faker.providers.address.ru_RU import Provider
Установим подключение к DuckDB, развернутой в памяти и создадим последовательность для автоинкрементации первичного ключа в каждой таблицы. В отличие от PostgreSQL, MySQL и SQLLite, в DuckDB нет заранее созданных последовательностей, которые можно использовать при объявлении типа данных столбца.
# создание подключения (используем in-memory базу данных)
con = duckdb.connect(':memory:')
# последовательность для автоинкремента ключа
con.execute("""CREATE SEQUENCE id_sequence START 1;""")
# создание таблиц DuckDB
con.execute("""
CREATE TABLE IF NOT EXISTS providers (
id INTEGER PRIMARY KEY DEFAULT nextval('id_sequence'),
name TEXT NOT NULL,
email TEXT NOT NULL,
phone TEXT
);
""")
con.execute("""
CREATE TABLE IF NOT EXISTS products (
id INTEGER PRIMARY KEY DEFAULT nextval('id_sequence'),
name TEXT NOT NULL,
price DECIMAL NOT NULL,
provider INTEGER NOT NULL,
FOREIGN KEY (provider) REFERENCES providers(id)
);
""")
Определим функции добавления фейковых данных в таблицы и вычисления агрегаций по поставщикам – какое количество товаров поставл каждый из них.
# функция добавления поставщика
def add_provider(name, email, phone):
try:
con.execute("INSERT INTO providers (name, email, phone) VALUES (?, ?, ?)", (name, email, phone))
print(f'Поставщик {name} добавлен.')
except duckdb.Error as e:
print(f'Ошибка при добавлении поставщика: {e}')
# функция добавления товара
def add_product(name, price, provider):
try:
con.execute("INSERT INTO products (name, price, provider) VALUES (?, ?, ?)", (name, price, provider))
print(f'Валюта {name} стоимостью {price} добавлена')
except duckdb.IntegrityError:
print('Ошибка: такого поставщика НЕ существует')
except duckdb.Error as e:
print(f'Ошибка при добавлении товара: {e}')
# добавляем поставщиков
providers_quantity = random.randint(1, 10)
for _ in range(providers_quantity):
name = fake.company()
email = fake.unique.email()
phone = fake.phone_number()
add_provider(name, email, phone)
# получаем список существующих поставщиков
provider_ids = con.execute('SELECT id FROM providers').fetchall()
provider_ids = [row[0] for row in provider_ids]
# добавляем товары
if provider_ids:
products_quantity = random.randint(1, 5)
for _ in range(products_quantity):
name = fake.currency_name()
price = random.uniform(10.0, 10000.0) # float для цены
provider = random.choice(provider_ids)
add_product(name, price, provider)
else:
print('Нет поставщиков для добавления товара')
# функция получения агрегатов товаров по поставщикам
def get_providers_products():
try:
result = con.execute('''
SELECT
providers.name AS "Provider Name",
providers.email AS "Provider Email",
COUNT(products.id) AS "Product Count"
FROM products
JOIN providers ON providers.id = products.provider
GROUP BY products.provider, providers.name, providers.email
ORDER BY "Product Count" DESC
''').fetchall()
for row in result:
print(row)
except duckdb.Error as e:
print(f'Ошибка при получении аналитики: {e}')
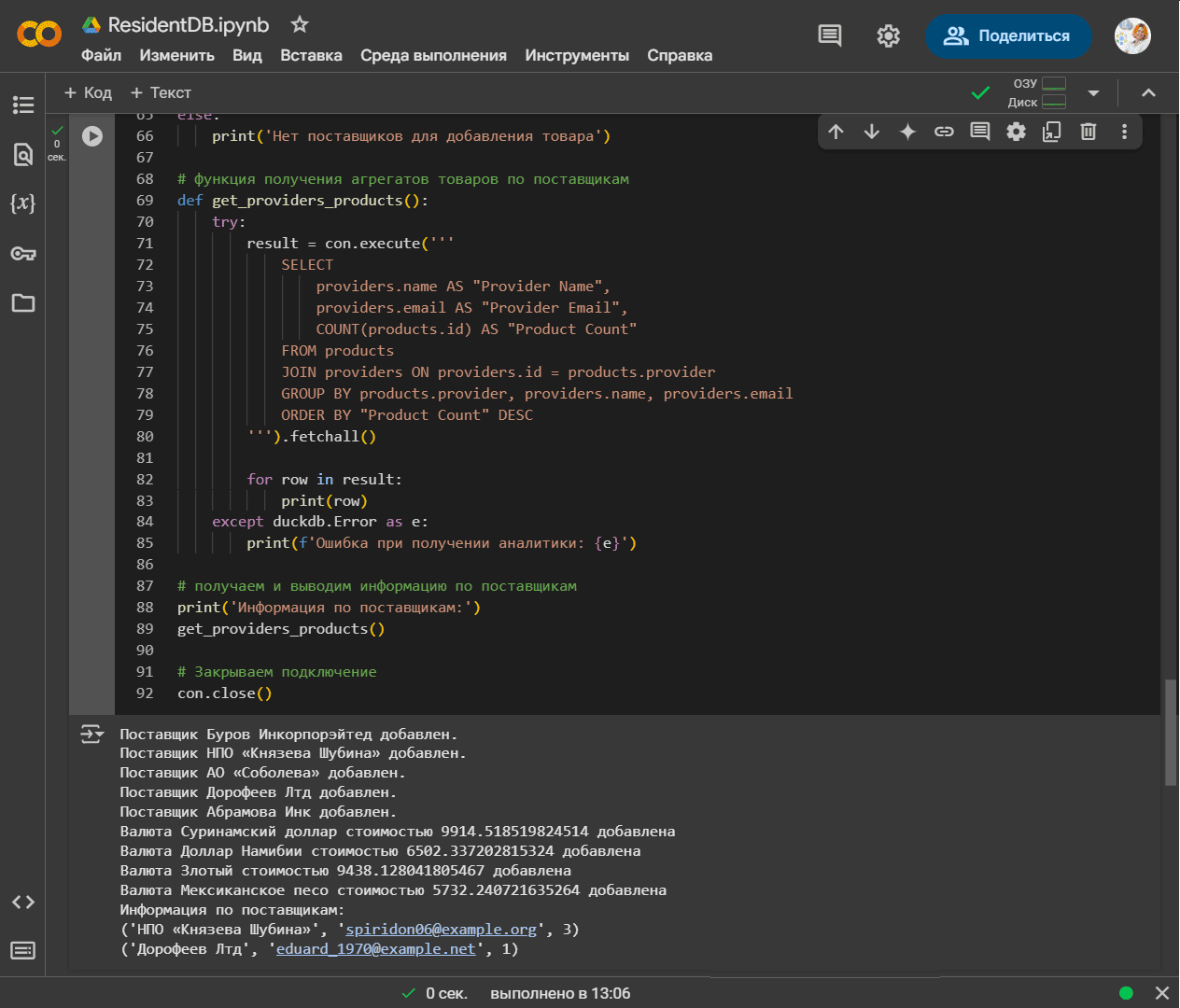
Наконец, вычислим результат агрегации и выведем его в консоль.
# получаем и выводим информацию по поставщикам
print('Информация по поставщикам:')
get_providers_products()
# закрываем подключение
con.close()
NebulaGraph Lite
Для NebulaGraph Lite я решила не писать собственный набор данных, а использовать демо-граф игроков в командах. Впрочем, чтобы работать с этим легковесным хранилищем, надо сперва установить нужные библиотеки и пакеты. Например, для интерактивной визуализации графа в консоли Colab пришлось установить библиотеку pyvis и NetworkX, а также ng_nx для интеграции между Nebula Graph и NetworkX. БД запускается в Docker-контейнере, чтобы использовать автоматически настроенные сервисы и запустить их в среде Colab. Помимо уже настроенных зависимостей, этот Docker-контейнер с базой содержит сами данные, т.е. граф знаний об игроках.
# Установка библиотеки nebulagraph-lite для работы с графами !pip install nebulagraph-lite # Установка библиотек jupyter_nebulagraph и pyvis для визуализации графов в Jupyter Notebook !pip install jupyter_nebulagraph pyvis # Установка библиотеки ng_nx для интеграции Nebula Graph с NetworkX !pip install ng_nx # Импорт функции nebulagraph_let из пакета nebulagraph_lite from nebulagraph_lite import nebulagraph_let # Импорт классов NebulaReader и NebulaWriter из пакета ng_nx для чтения и записи данных в Nebula Graph from ng_nx import NebulaReader from ng_nx import NebulaWriter # Импорт класса NebulaGraphConfig из утилит ng_nx для настройки подключения к Nebula Graph from ng_nx.utils import NebulaGraphConfig # Импорт библиотеки NetworkX для создания и управления графами import networkx as nx # Инициализация объекта nebulagraph_let с отключенным режимом отладки n = nebulagraph_let(debug=False) # Запуск сервиса Nebula Graph n.start() # Вывод списка запущенных Docker-контейнеров, связанных с Nebula Graph n.docker_ps() # загружаем расширение ngql для выполнения запросов к базе данных Nebula Graph %load_ext ngql %ngql --address 127.0.0.1 --port 9669 --user root --password nebula # установка соединения с сервером Nebula Graph по адресу 127.0.0.1 и порту 9669, используя имя пользователя root и пароль nebula %ngql SHOW HOSTS; # отобразим список хостов в кластере Nebula Graph
Сделаем запрос к графу
# ищем все ребра (отношения) между любыми двумя узлами в графе, возвращаем результаты и ограничиваем вывод первыми 10 ребрами %%ngql MATCH ()-[e]->() RETURN e LIMIT 10 # визуализация графа %ng_draw
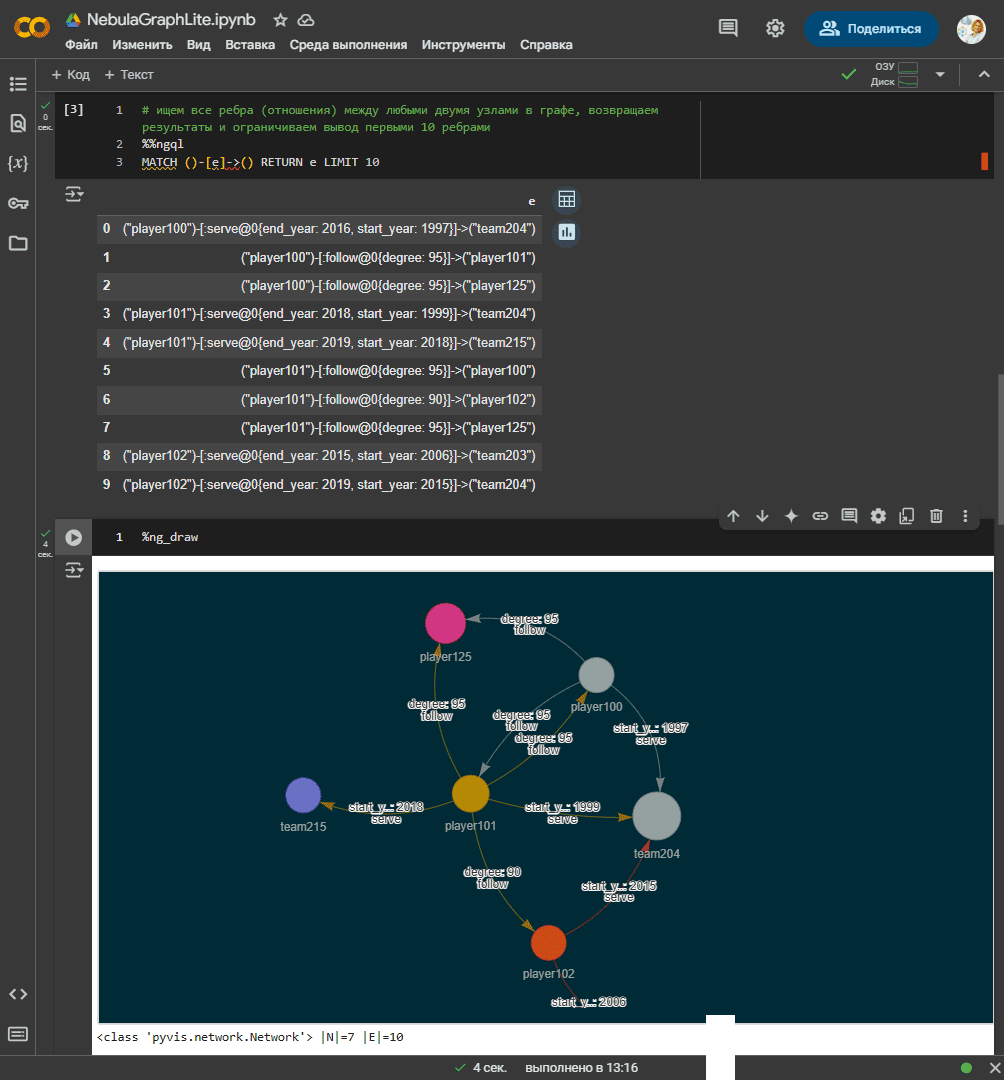
Визуализацию графа можно сохранить как отдельное изображение.
Таким образом, если нужно что-то быстро разработать для проверки гипотезы или знакомства с технологией без развертывания отдельного сервера, резидентные базы данных – отличный выбор. При промышленном использовании резидентной БД стоит помнить о том, что вся информация потеряется при остановке вычислительного хост-процесса, в который встроено это хранилище данных. Для долговременного хранения этих данных их следует выгрузить на диск, используя встроенные механизма In-Memory хранилища (моментальные снимки, логирование операций) или внешние инструменты: системы резервного копирования или собственные скрипты.
Подробнее про хранение и обработку данных в информационных системах вы узнаете на моих курсах в Школе прикладного бизнес-анализа на базе нашего лицензированного учебного центра обучения и повышения квалификации системных и бизнес-аналитиков в Москве: