Что такое каталог данных, какова роль этого артефакта в архитектуре и инженерии данных, что говорит DAMA DMBOK про управление метаданными и как быстро провести каталогизацию и визуализацию метаданных из систем источников: Python-прототип для PostgreSQL и PlantUML.
Зачем управлять метаданными и что такое каталог данных
Самым известным сводом знаний по управлению данными считается DAMA DMBOK. В области архитектуры и инженерии данных эта книга является аналогом BABOK®Guide для бизнес-анализа. DAMA DMBOK определяет области знаний по управлению данными, а также подходы, лучшие практики и инструменты их реализации. Рекомендации DAMA DMBOK используются при создании и внедрении платформ данных для автоматизации и системного управления процессами сбора, хранения, преобразования, консолидации и аналитики данных.
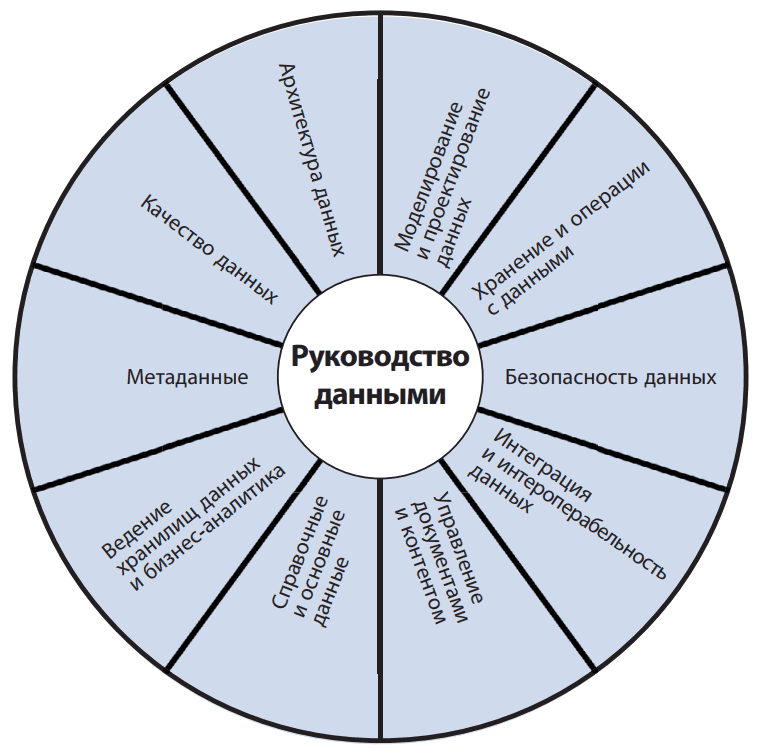
Чтобы чем-то управлять, об этом нужно, прежде всего, знать. Соответственно, для управления данными, необходимы подробные данные об этих данные, т.е. метаданные. Поэтому DAMA DMBOK выделяет «Управление метаданными» (Metadata Management) как самостоятельную область знаний, направленную на создание и ведение реестров, каталогов и словарей данных для эффективного управления данными. Управление метаданными означает их упорядоченное хранение и систематическое обновление, чтобы они были точными, единообразными и полными. Это необходимо для обеспечения качества данных, их целостности и согласованного выполнения инженерных процессов. Метаданные необходимы для построения корпоративного хранилищ и озер данных, т.к. они описывают фактические данные из оперативных (транзакционных) систем:
- перечень таблиц в реляционных БД, документов в документо-ориентированных хранилищах и т.д.
- схемы данных, т.е. структура таблиц или определения полей в документах, включая названия и типы данных;
- ограничения и связи, например, первичные и внешние ключи, NULL-значения, значения по умолчанию, вычисляемые поля и пр.;
- владельцы структур данных и описания преобразований из системы-источника в систему-приемник, информацию об обновлении и т.д.
Все эти и другие метаданные хранятся в так называемом репозитории или каталоге (Data Catalog). Сегодня на рынке есть множество готовых решений для комплексного управления метаданными, например, Open Metadata, о котором я расскажу в другой раз. Также есть инструменты только каталогизации данных, например, Unity Catalog, Hive Metastore, AWS Glue Data Catalog, Google Cloud Data Catalog и пр. Подробнее про Unity Catalog я рассказываю здесь, в блоге нашей Школы Больших Данных. Разумеется, развертывание такого сервиса является отдельным проектом, который требует довольно много времени и ресурсов. В целом внедрение сервиса каталогизации данных в ИТ-ландшафт будет включать следующие шаги:
- предпроектное обследование для определения источников метаданных, т.е. описание информационных систем и бизнес-процессов, которые они поддерживают, наборов данных и их владельцев;
- разработка требований к периодичности обновления метаданных в каталоге;
- выбор решения, которое будет удовлетворять требованиям и ограничениям, т.е. поддерживать интеграцию с источниками метаданных;
- разработка шаблонов и регламентов ведения метаданных на стороне источников, например, правила аннотирования (комментирования), именования и атрибутирования данных для формирования метаданных по определенному шаблону;
- развертывание сервиса каталогизации;
- интеграция сервиса каталогизации с источниками метаданных. Обычно это сводится к настройке существующих коннекторов, но иногда приходится писать собственные решения, обеспечивающие передачу метаданных из систем-источников в каталог.
- организация мониторинга процессов управления метаданными, включая отслеживание их качества и информирование ответственных при отклонении показателей этого качества от плановых значений. Например, если в системах-источниках создаются новые структуры данных без должного аннотирования.
Чтобы упростить и ускорить выполнение 2-х первых этапов, можно автоматизировать выгрузку сведений о данных, хранящихся в системах-источниках. Например, многие СУБД хранят информация о схемах, таблицах, столбцах и других объектах в специальных системных таблицах. Поэтому для сбора сведений о данных, т.е. первичного сбора метаданных из систем-источников для наполнения каталога метаданных, следует обращаться к системным таблицам СУБД. Как это сделать, разберем далее на примере моей любимой PostgreSQL.
Пример сбора и визуализации метаданных из PostgreSQL
В PostgreSQL метаданные хранятся в системном каталоге, т.е. схема pg_catalog, а также информационной схеме information_schema. В системных каталогах, которые представляют собой обычные таблицы, хранятся метаданные схемы данных: информация о таблицах и столбцах, а также служебные сведения. Информационная схема включает набор представлений с информацией об объектах в текущей базе данных. В отличие от системных каталогов, которые специфичны для PostgreSQL, информационная схема – это общее решение, которое соответствует ANSI SQL, а потому переносимо и стабильно.
Предположим, для понимания структуры данных, хранящихся в БД PostgreSQL, и первичного наполнения каталога данных, я хочу получить перечень всех таблиц рабочих схема данных, их владельцев, комментарии к таблицам и их связи с другими таблицами. Также по каждой таблице необходимо получить перечень столбцов, их типы данных, комментарии, значения по умолчанию и ограничения, такие как возможность иметь пустые значения (NULL), принадлежность к первичному (PK, Primary Key) или внешнему ключу (FK, Foreign Key), а также соответствующий этому ограничению столбец внешней таблицы. В PostgreSQL эти метаданные можно взять из следующих таблиц:
- tables – список всех таблиц и представлений;
- columns — список всех столбцов таблиц и их типов;
- table_constraints — ограничения таблиц (PK, FK и т.д.);
- pg_class — низкоуровневая информация о таблицах, индексах, представлениях и других объектах;
- pg_attribute — информация о табличных столбцах;
- pg_constraint — информация обо всех ограничениях.
Получается, нужно написать SQL-запрос выборки данных из этих таблиц. Однако, мне нужны только пользовательские схемы и базы данных, а не системные или резервные. Также, из-за того, что моя БД развернута в облачном сервисе Aiven, я исключаю БД с названием _aiven. Таким образом, для получения перечня пользовательских баз данных, комментариев к ним, названий пользовательских схем и непустых комментариев к этим схемам, можно написать следующий запрос:
SELECT
d.datname AS database_name,
pg_catalog.shobj_description(d.oid, 'pg_database') AS database_comment,
n.nspname AS schema_name,
pg_catalog.obj_description(n.oid, 'pg_namespace') AS schema_comment
FROM pg_database d
LEFT JOIN pg_catalog.pg_namespace n ON pg_catalog.obj_description(n.oid, 'pg_namespace') IS NOT NULL
WHERE d.datistemplate = false
AND d.datname <> '_aiven'
AND pg_catalog.obj_description(n.oid, 'pg_namespace') NOT IN (
'standard public schema',
'reserved schema for TOAST tables',
'system catalog schema'
)
ORDER BY d.datname, n.nspname;
В этом запросе условие JOIN соединяет БД из pg_database со схемами, у которых заданы описания, т.е. добавлены комментарии из pg_namespace.
Получив название БД и схемы данных, с заданными комментариями, далее нужно получить список таблиц, их столбцов с типами данных, ограничениями и связями между таблицами. Для этого подойдет следующий запрос:
SELECT DISTINCT
cols.table_schema || '.' || cols.table_name AS table_full_name,
pg_class.relowner::regrole::text AS owner,
obj_description(pg_class.oid, 'pg_class') AS table_comment,
cols.column_name AS column_name,
cols.data_type AS data_type,
cols.column_default AS default_value,
(cols.is_nullable = 'NO') AS NOT_NULL,
col_description(pg_class.oid, cols.ordinal_position) AS column_comment,
tc.constraint_type AS constraint_type,
fk.foreign_table_schema || '.' || fk.foreign_table_name AS foreign_table_full_name,
fk.foreign_column_name AS foreign_column_name
FROM information_schema.columns cols
LEFT JOIN pg_class
ON pg_class.relname = cols.table_name
AND pg_class.relkind = 'r'
LEFT JOIN pg_namespace nsp
ON nsp.oid = pg_class.relnamespace
AND nsp.nspname = cols.table_schema
LEFT JOIN pg_stat_all_tables
ON pg_stat_all_tables.relid = pg_class.oid
LEFT JOIN (
SELECT
tc.table_schema,
tc.table_name,
kcu.column_name,
tc.constraint_type
FROM information_schema.table_constraints tc
JOIN information_schema.key_column_usage kcu
ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
AND tc.table_name = kcu.table_name
WHERE tc.constraint_type IN ('PRIMARY KEY', 'UNIQUE')
) tc ON cols.table_schema = tc.table_schema
AND cols.table_name = tc.table_name
AND cols.column_name = tc.column_name
LEFT JOIN (
SELECT
kcu.table_schema,
kcu.table_name,
kcu.column_name,
ccu.table_schema AS foreign_table_schema,
ccu.table_name AS foreign_table_name,
ccu.column_name AS foreign_column_name
FROM information_schema.table_constraints tc
JOIN information_schema.key_column_usage kcu
ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
AND tc.table_name = kcu.table_name
JOIN information_schema.constraint_column_usage ccu
ON ccu.constraint_name = tc.constraint_name
AND ccu.table_schema = tc.table_schema
WHERE tc.constraint_type = 'FOREIGN KEY'
) fk ON cols.table_schema = fk.table_schema
AND cols.table_name = fk.table_name
AND cols.column_name = fk.column_name
LEFT JOIN (
SELECT
source_ns.nspname AS table_schema,
source_table.relname AS table_name,
string_agg(DISTINCT dep_view.relname, ', ') AS view_names
FROM pg_depend dep
JOIN pg_rewrite rw ON rw.oid = dep.objid
JOIN pg_class dep_view ON dep_view.oid = rw.ev_class AND dep_view.relkind = 'v'
JOIN pg_class source_table ON source_table.oid = dep.refobjid AND source_table.relkind = 'r'
JOIN pg_namespace source_ns ON source_table.relnamespace = source_ns.oid
GROUP BY source_ns.nspname, source_table.relname
) dependent_views ON dependent_views.table_schema = cols.table_schema
AND dependent_views.table_name = cols.table_name
WHERE cols.table_schema NOT IN ('pg_catalog', 'information_schema', 'hdb_catalog');
Такой SELECT-запрос вернет нужные метаданные в табличном виде. Однако, для визуального представления этого недостаточно. Поэтому я решила еще сформировать скрипт для PlantUML, который будет описывать ER-диаграмму схемы данных моей БД PostgreSQL по извлеченным метаданным. Разумеется, писать буду на Python. Принцип моей разработки визуально выглядит так.
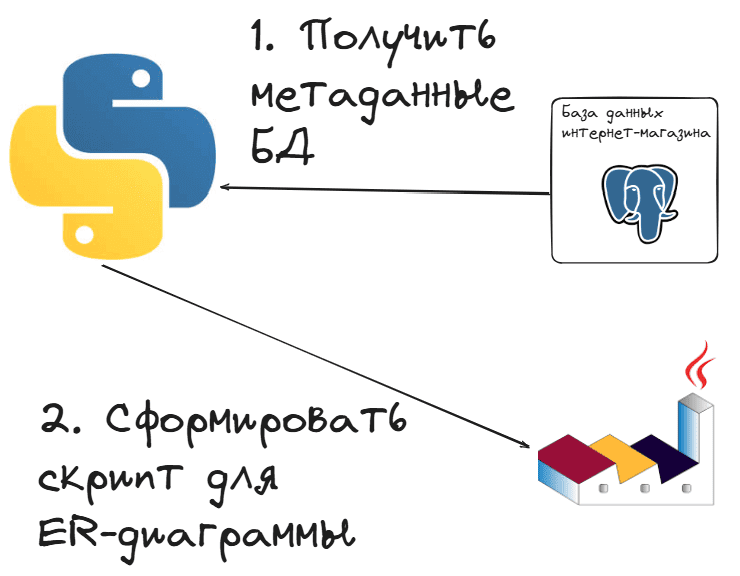
Чтобы вы могли повторить это упражнение на своей БД PostgreSQL без установки дополнительного ПО, приведу Python-код для запуска в интерактивной среде Google Colab:
################# ячейка 1 в Google Colab ########################
# Импорт модулей и библиотек
import traceback #для вывода информации об исключениях и записей трассировки стека
import threading
import pandas as pd #для датафреймов
import os #для работы с операционной системой, файловым пространством ВМ Google Colab
import psycopg2 #для работы с PostgreSQL
from google.colab import userdata #для импорта секретов
from google.colab import files #для работы с файлами
from datetime import date, datetime, timedelta #для работы с датой и временем
################# ячейка 2 в Google Colab #################
# Строка подключения к БД
global db_pg_connection_string
connection_string = userdata.get('db_pg_connection_string') #добавить строку подключения db_pg_connection_string в секреты Google Colab или явно указать здесь
# Функция получения метаданных о текущей БД
def get_db_metadata(connection_string):
query = """
SELECT
d.datname AS database_name,
pg_catalog.shobj_description(d.oid, 'pg_database') AS database_comment,
n.nspname AS schema_name,
pg_catalog.obj_description(n.oid, 'pg_namespace') AS schema_comment
FROM pg_database d
LEFT JOIN pg_catalog.pg_namespace n ON pg_catalog.obj_description(n.oid, 'pg_namespace') IS NOT NULL
WHERE d.datistemplate = false
AND d.datname <> '_aiven'
AND pg_catalog.obj_description(n.oid, 'pg_namespace') NOT IN (
'standard public schema',
'reserved schema for TOAST tables',
'system catalog schema'
)
ORDER BY d.datname, n.nspname;
"""
try:
with psycopg2.connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute(query)
results = cursor.fetchall()
df_db_meta = pd.DataFrame(results, columns=[
'Название БД',
'Комментарий к БД',
'Название схемы',
'Комментарий к схеме'
])
print(df_db_meta)
return df_db_meta
except Exception as e:
traceback.print_exc()
return pd.DataFrame()
# Функция получения списка таблиц, колонок с типами данных, ограничениями и связями между таблицами
def get_tables_metadata_db(connection_string):
query = """
SELECT DISTINCT
cols.table_schema || '.' || cols.table_name AS table_full_name,
pg_class.relowner::regrole::text AS owner,
obj_description(pg_class.oid, 'pg_class') AS table_comment,
cols.column_name AS column_name,
cols.data_type AS data_type,
cols.column_default AS default_value,
(cols.is_nullable = 'NO') AS NOT_NULL,
col_description(pg_class.oid, cols.ordinal_position) AS column_comment,
tc.constraint_type AS constraint_type,
fk.foreign_table_schema || '.' || fk.foreign_table_name AS foreign_table_full_name,
fk.foreign_column_name AS foreign_column_name
FROM information_schema.columns cols
LEFT JOIN pg_class
ON pg_class.relname = cols.table_name
AND pg_class.relkind = 'r'
LEFT JOIN pg_namespace nsp
ON nsp.oid = pg_class.relnamespace
AND nsp.nspname = cols.table_schema
LEFT JOIN pg_stat_all_tables
ON pg_stat_all_tables.relid = pg_class.oid
LEFT JOIN (
SELECT
tc.table_schema,
tc.table_name,
kcu.column_name,
tc.constraint_type
FROM information_schema.table_constraints tc
JOIN information_schema.key_column_usage kcu
ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
AND tc.table_name = kcu.table_name
WHERE tc.constraint_type IN ('PRIMARY KEY', 'UNIQUE')
) tc ON cols.table_schema = tc.table_schema
AND cols.table_name = tc.table_name
AND cols.column_name = tc.column_name
LEFT JOIN (
SELECT
kcu.table_schema,
kcu.table_name,
kcu.column_name,
ccu.table_schema AS foreign_table_schema,
ccu.table_name AS foreign_table_name,
ccu.column_name AS foreign_column_name
FROM information_schema.table_constraints tc
JOIN information_schema.key_column_usage kcu
ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
AND tc.table_name = kcu.table_name
JOIN information_schema.constraint_column_usage ccu
ON ccu.constraint_name = tc.constraint_name
AND ccu.table_schema = tc.table_schema
WHERE tc.constraint_type = 'FOREIGN KEY'
) fk ON cols.table_schema = fk.table_schema
AND cols.table_name = fk.table_name
AND cols.column_name = fk.column_name
LEFT JOIN (
SELECT
source_ns.nspname AS table_schema,
source_table.relname AS table_name,
string_agg(DISTINCT dep_view.relname, ', ') AS view_names
FROM pg_depend dep
JOIN pg_rewrite rw ON rw.oid = dep.objid
JOIN pg_class dep_view ON dep_view.oid = rw.ev_class AND dep_view.relkind = 'v'
JOIN pg_class source_table ON source_table.oid = dep.refobjid AND source_table.relkind = 'r'
JOIN pg_namespace source_ns ON source_table.relnamespace = source_ns.oid
GROUP BY source_ns.nspname, source_table.relname
) dependent_views ON dependent_views.table_schema = cols.table_schema
AND dependent_views.table_name = cols.table_name
WHERE cols.table_schema NOT IN ('pg_catalog', 'information_schema', 'hdb_catalog');
"""
try:
with psycopg2.connect(connection_string) as conn:
with conn.cursor() as cursor:
cursor.execute(query)
results = cursor.fetchall()
df_tables_meta = pd.DataFrame(results, columns=[
'Таблица',
'Владелец',
'Комментарий к таблице',
'Столбец',
'Тип данных',
'Значение по умолчанию',
'NOT_NULL',
'Комментарий к столбцу',
'Тип ограничения',
'Связанная таблица',
'Столбец связи'
])
return df_tables_meta
except Exception as e:
traceback.print_exc()
return pd.DataFrame()
df_meta = get_db_metadata(connection_string)
# Выбираем название первой БД из DataFrame для примера
if not df_meta.empty:
db_name = df_meta.iloc[0]['Название БД']
db_comment = df_meta.iloc[0]['Комментарий к БД']
schema_name = df_meta.iloc[0]['Название схемы']
schema_comment = df_meta.iloc[0]['Комментарий к схеме']
else:
print("Метаданные о БД не найдены.")
# Функция генерации PlantUML-кода
def create_plantuml_ie_diagram(df_db_meta, df_tables_meta):
diagram = "@startuml\n\n"
diagram += f"header БД {db_name} {db_comment}\n"
diagram += f"title Схема данных {schema_name} {schema_comment}\n\n"
diagram += "skinparam linetype ortho\n\n"
tables = df_tables_meta.groupby('Таблица')
table_entities = {}
for table_name, group in tables:
alias = table_name.replace('.', '_').replace('-', '_')
table_entities[table_name] = alias
diagram += f'entity "{table_name}" as {alias} {{\n'
# Определяем первичные и внешние ключи
pk_cols = group[group['Тип ограничения'] == 'PRIMARY KEY']['Столбец'].tolist()
fk_cols = group[group['Столбец связи'].notnull()]['Столбец'].tolist()
# Сначала добавляем первичные ключи
for _, row in group.iterrows():
col_name = row['Столбец']
if col_name in pk_cols:
data_type = row['Тип данных']
annotations = "<<PK>>"
diagram += f" {col_name} : {data_type} {annotations}\n"
# Если есть первичные ключи, добавляем разделитель
if pk_cols:
diagram += " --\n"
# Затем добавляем остальные столбцы
for _, row in group.iterrows():
col_name = row['Столбец']
if col_name not in pk_cols:
data_type = row['Тип данных']
annotations = "<<FK>>" if col_name in fk_cols else ""
nullable_str = "" if row['NOT_NULL'] else " [Nullable]"
diagram += f" {col_name} : {data_type} {annotations}{nullable_str}\n"
diagram += "}\n\n"
# Добавляем комментарий к таблице (если есть)
table_comment = group['Комментарий к таблице'].iloc[0]
if pd.notnull(table_comment):
diagram += f"note top of {alias}\n"
diagram += f"{table_comment}\n"
diagram += "end note\n\n"
# Добавляем комментарии к столбцам (значение по умолчанию и комментарий столбца)
for _, row in group.iterrows():
col_notes = []
if pd.notnull(row['Значение по умолчанию']):
col_notes.append(f"default: {row['Значение по умолчанию']}")
if pd.notnull(row['Комментарий к столбцу']):
col_notes.append(row['Комментарий к столбцу'])
if col_notes:
notes_str = "\n".join(col_notes)
diagram += f"note right of {alias}::{row['Столбец']}\n"
diagram += f"{notes_str}\n"
diagram += "end note\n\n"
# Добавляем связи между таблицами
relationships = df_tables_meta[df_tables_meta['Связанная таблица'].notnull()]
for _, row in relationships.iterrows():
source_alias = table_entities[row['Таблица']]
target_alias = table_entities[row['Связанная таблица']]
# IE нотация: Родительская таблица || (обязательно) или |o (необязательно), дочерняя — o{ (необязательно много) или |{ (обязательно много)
diagram += f"{target_alias} ||..o{{ {source_alias}\n"
diagram += "@enduml"
return diagram
###################### ячейка 3 в Google Colab #######################
# Получаем метаданные по таблицам
tables_meta_df = get_tables_metadata_db(connection_string)
print("Метаданные таблиц")
print(tables_meta_df)
# Формируем имя выходного файла с текущими датой и временем в нужном формате
filename_csv= 'db_metadata_' + datetime.now().strftime('%Y%m%d_%H%M%S') + '.csv'
db_metadata_csv=tables_meta_df.to_csv(filename_csv)
# Скачиваем созданный файл
files.download(filename_csv)
# Используем ранее полученный датафрейм tables_meta_df для формирования PlantUML-диаграммы
plantuml_diagram = create_plantuml_ie_diagram(df_meta, tables_meta_df)
# Формируем имя выходного файла с текущими датой и временем в нужном формате
filename_diagram = 'er_plantuml_' + datetime.now().strftime('%Y%m%d_%H%M%S') + '.txt'
# Записываем PlantUML-код в CSV-файл
with open(filename_diagram , "w", encoding="utf-8") as file:
file.write(plantuml_diagram)
# Скачиваем созданный файл
files.download(filename_diagram)
В результате выполнения этого Python-скрипта получаем CSV-файл с метаданными, который можно открыть в Excel для просмотра.
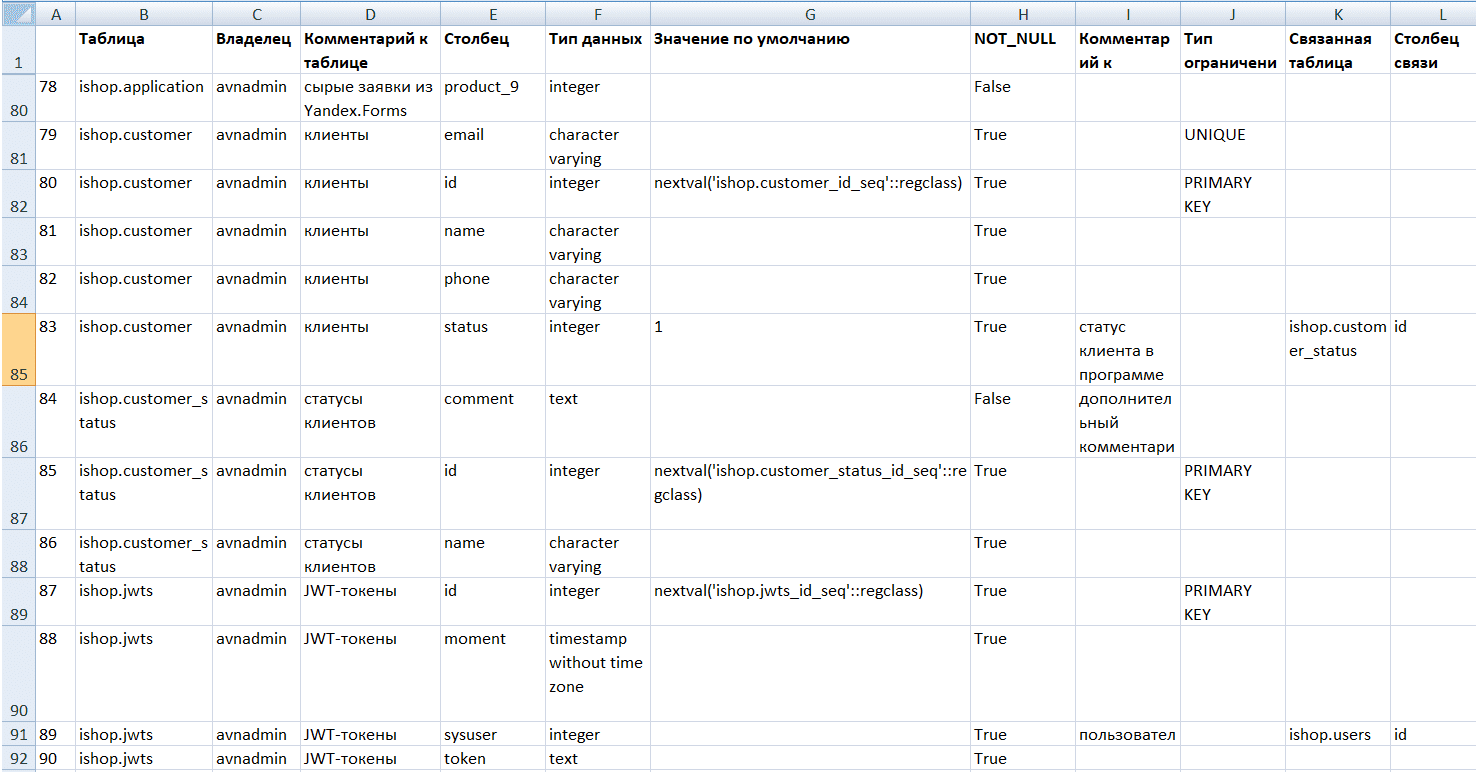
Загрузив сформированный скрипт ER-диаграммы в сервис PlantUML, можно визуально увидеть схему данных.
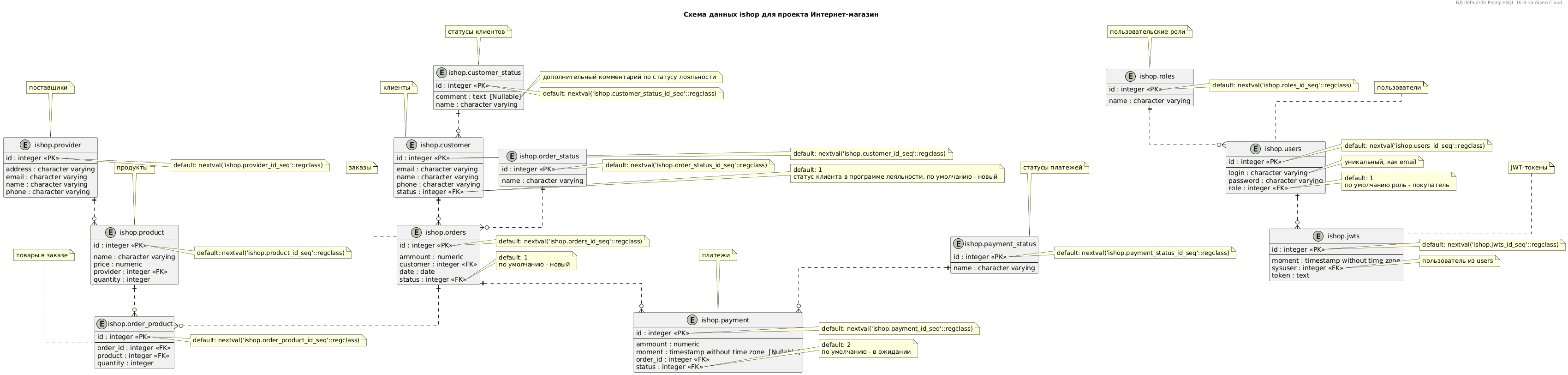
Чтобы отслеживать изменения источника данных, можно доработать предложенный прототип, например, организовав событийное или постоянное отслеживание изменений в источнике данных с их передачей в средства сохранения и визуализации. В частности, можно публиковать новые версии таблицы с метаданными и скрипта для PlantUML в Github-репозиторий или другой подобный сервис. Описанный подход можно адаптировать к другим источникам данных, например, собирать метаданные из других реляционных или нереляционных БД, а также потоковых платформ типа Apache Kafka, RabbitMQ и пр., чтобы получать информацию о топиках/очередях и структуре опубликованных в них сообщений.
Разумеется, чтобы предложенное решение работало постоянно, скрипты сбора и преобразования данных надо развернуть как самостоятельное приложение или как часть какой-либо платформы. Например, Python-скрипты можно упаковать в DAG AirFlow, чтобы периодически опрашивать источники данных или получать от них события изменений через логическую репликацию и коннекторы к брокеру сообщений. Однако, это уже путь к построению своей платформы данных, что не всегда оправдано. Для полноценного управления метаданными можно взять готовое решение, например, Open Metadata, о котором я расскажу в следующий раз.
А в заключение подчеркну, что мой прототип подходит для быстрого предпроектного обследования перед внедрением платформы данных и разработки требований к сервису каталогизации. Как обычно, скрипт описанного решения доступен в моем GitHub.
Рассмотренные темы и другие тонкости работы с платформами и хранилищами данных разбираю на моих курсах Школы прикладного бизнес-анализа и проектирования информационных систем в нашем лицензированном учебном центре обучения и повышения квалификации системных и бизнес-аналитиков в Москве:
- Проектирование и внедрение платформы данных — DAMA DMBOK на практике
- Проектирование и эксплуатация баз данных